NoPe-NeRF: Optimising Neural Radiance Field with No Pose Prior, Wenjing Bian, CVPR2023
NoPe-NeRF는 Camera Pose와 Radiance Field를 동시에 최적화하는 방법에 대해 다루는 연구입니다.
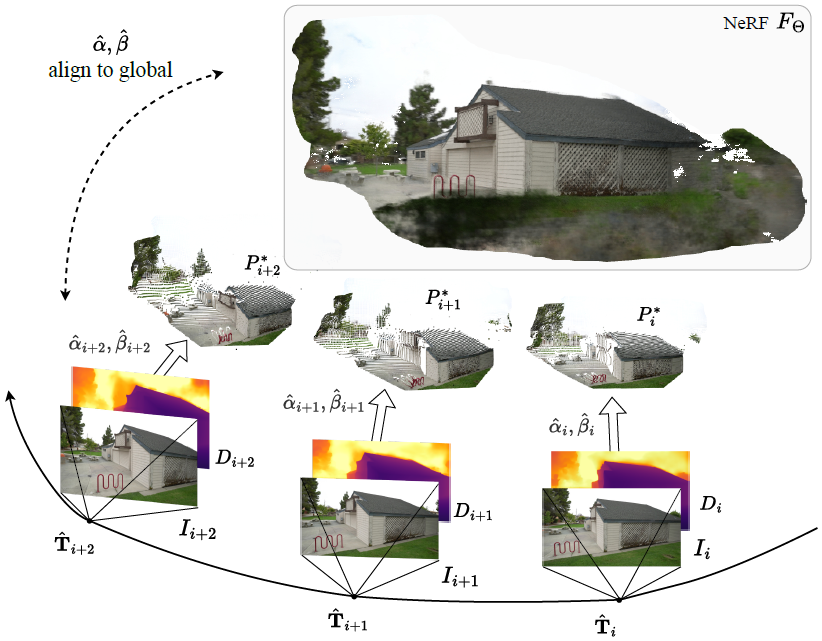
위 그림은 Camera Pose T에 대한 RGB 이미지 I와 Depth Estimation한 Depth Map D, 이를 back-projection한 Point Cloud P 그리고 NeRF Model FΘ을 α, β parameter로 alignment하는 것을 보여줍니다. 이러한 parameter들을 기반으로 어떤 Scene에 대한 카메라 Intrinsic값을 가진 Image I 들이 주어졌을 때, 카메라 Extrinsic Parameter T와 NeRF Model FΘ를 최적화시키는 방법을 소개하고 있습니다.
Introduction
논문 Introduction이 기존의 문제점과 해결방법이 논리적으로 잘 구성되어 있어서, 서술 방법을 그대로 들고 왔습니다.
Camera Pose와 Radiance Field를 동시에 최적화하는 방법으로 NeRF--, BARF, SC-NeRF 연구들이 있었습니다.
- 이 연구들은 (정면에 위치한 물체를 일정 거리에서 비슷한 위치에서 촬영한) forward-facing scene에 대해서만 다룰 수있었고
- 손으로 촬영한 흔들림 있는 영상을 다룰 수는 없었습니다.
논문에서 언급하기로 2가지 이유 때문인데,
- 전통적인 SLAM, Visual odometry, pose estimation 연구 분야에서는 relative pose를 추정했었지만, NeRF 기반 연구들은 이를 따르지 않고 (Radiance Field를 동시에 만들어야 했기 때문에) 이미지마다 개별 pose를 추정했었습니다.
- NeRF에서는 radiance ambiguity를 줄이면서 학습이 진행되는데, 이를 고려하면서 동시에 pose를 추정하기 때문에 느리게 수렴하고 unstable하게 optimisation 되었습니다.
논문에서는 카메라 움직임이 큰 scene (forward-facing scene이 아닌 unbounded scene)을 다루기 위해, monocular depth estimation에서 아이디어를 얻었습니다.
- monocular depth는 strong geometry 를 갖기 때문에, shape radiance ambiguity에 constraint를 줄 수 있습니다.
- 인접한 depth map간의 relative pose는 쉽게 training pipe line에 사용 될 수 있습니다.
- (multi-view stereo depth estimation과 달리) monocular depth는 빠르게 실행되고, 입력으로 camera parameter가 필요 없습니다.
mono-depth를 그대로 사용하는 것으로는, multi-view에 대한 scale과 shift distortion이 고려되지 못하기 때문에,
- 학습단계에서 rendered depth와 mono-depth 간의 difference를 줄이도록 (Chamfer Distance Loss와 depth-based surface rendering Loss)를 설계하여, scale과 shift parameter를 explicitly하게 최적화하였습니다.
- NeRF가 multiview consistency(일관성)을 가지는 특성을 사용하여, mono-depth map을 undistorted multiview consistent depth map으로 변형할 수 있게 했습니다.
Camera Pose와 Radiance Field를 동시에 최적화하는 Task에 대해, 논문의 contribution은 다음과 같습니다.
- scale과 shift distortion을 explicitly하게 모델링하여, mono-depth를 unposed-NeRF training에 사용했습니다.
- mono-depth map에 inter-frame loss를 사용해서, relative pose로 camera와 NeRF를 joint optimisation했습니다.
- depth-based surface rendering loss를 사용해서, relative pose estimation을 regularization하였습니다.
Related Works
- Pose를 추정하면서 Radiance Field를 만드는 여러 논문들에 대해 한줄씩 언급되어 있습니다. NoPe-NeRF저자는 이러한 논문들을 unposed-NeRF라고 표현했습니다.
- iNeRF : reconstructed NeRF 모델로 포즈를 추정
- GNERF : GAN과 NeRF를 조합하여 포즈를 추정. pose에 대한 알려진 sampling distribution이 입력으로 요구됨
- NeRFmm(=NeRF--) : NeRF 학습 단계에서 camera intrinsic, extrinsic이 jointly optimize됨
- BARF : pose, NeRF를 joint optimisation위해 coarse-to-fine positional encoding을 제안
- SC-NeRF : camera distortion을 parameter화 하고, ray를 regularise 위해 geometric loss를 적용
- GARF : Gaussian-MLP를 사용해서 joint pose와 scene optimisation을 쉽고 accurate(정확)하게 만듦
- SiNeRF : SIREN layer를 사용하고, NeRF--내 joint optimisation의 sub-optimality를 완화하기 위해 novel sampling적용
이러한 연구들은 forwoard-facing 데이터셋인 LLFF에 대해 좋은 성능을 보였지만, large camera motion 입력 이미지들로는 적용하기 어렵습니다. NoPe-NeRF에서는 mono-depth maps으로 이를 해결하고자 하였습니다.
Algorithm
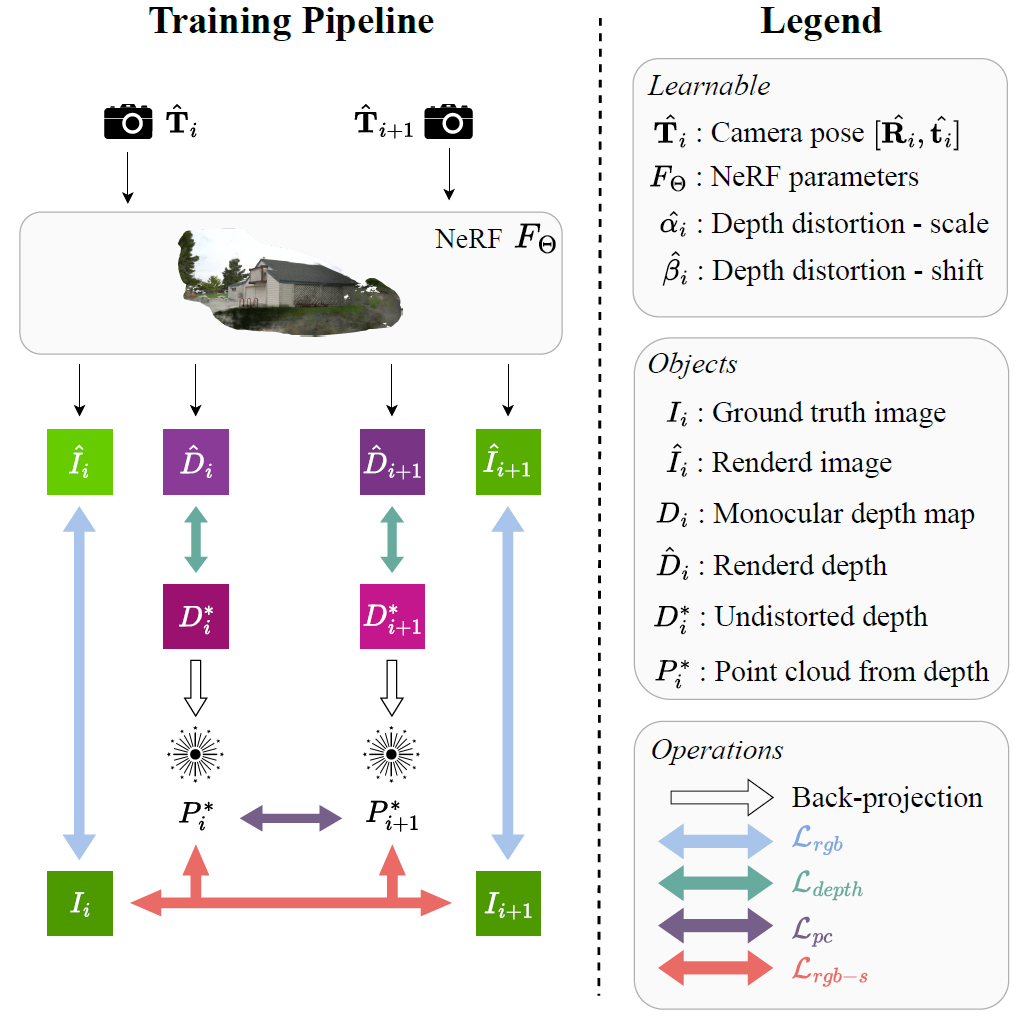
위 이미지로 전체 알고리즘이 설명됩니다.
카메라 Pose T가 주어질 때, NeRF를 통해 RGB Image I^와 Depth map D^를 추정합니다. i는 이미지 index입니다. GT RGB Image I로 mono-depth estimation을 통해 view에 독립적인 depth map D를 만들며, 여러 view에 대해 scale factor α와 shift factor β로 align한 Undistorted depth D*를 만들어줍니다. D*를 카메라 Inrinsic parameter으로 back-projection하여 point cloud P*를 만들어 줍니다. 위 변수들로 Loss가 설계됩니다.
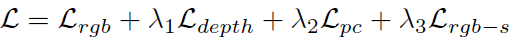
총 4개의 Loss로 구성됩니다. λ는 Loss의 weight factor입니다.
RGB Loss
기존 NeRF에서는 GT RGB Image와의 RGB Loss(하늘색 화살표)만으로 NeRF FΘ 모델을 업데이트 했었습니다. NoPe-NeRF도 RGB Loss는 동일합니다.
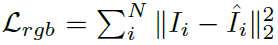
Depth Loss
GT RGB Image로 DPT라는 공개된 mono-depth estimation 알고리즘으로 mono-depth map D을 만들어 주고, scale factor α와 shift factor β를 통해 multi-view들을 align한 Undistorted depth map D*을 만들어 줍니다. scale factor α와 shift factor β는 학습과정에서 학습되는 parameter가 됩니다.

D*를 NeRF통해 prediction된 depth map D^와 비교하여 Loss (초록색 화살표)를 구합니다.

이를 NeRF통해 prediction된 depth map D^는 논문상에 위의 오른쪽 식과 같이 되어 있는데, discrete한 수식은 아래와 같습니다. C(r)에 대해서는 최초 NeRF Color Rendering 파트 참조 바라며, D(r) 에 대해서는 Nicer-SLAM 의 Loss부분에 설명 참조 바랍니다. ti는 1개 ray위의 sampling된 points들의 깊이 값을 나타냅니다.

스크롤이 내려와서 Training Pipeline 이미지와 전체 Loss를 다시 첨부하겠습니다.
Point Cloud Loss
먼저 Undistorted Depth map를 Back-projection해서 point cloud로 만들어 줍니다. 이미지마다 Pose Matrix T를 정의한 후, 2개 이미지에 대해 각 T Matrix로 2개 point cloud를 align하였고, 2개 point cloud의 차이를 Chamfer Distance로 거리를 계산하여 Loss를 설계 하였습니다.

Tji x Pi* 수식이 align하는 것에 해당하고, lcd는 Chamfer Distance로써 아래와 같이 정의됩니다. Chamfer Distance에 대한 설명은 이전글 참조 바랍니다.
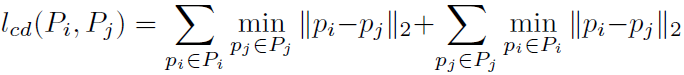
앞서 설명했던 Undistorted Depth으로 만들 때 사용했던 scale factor α와 shift factor β와 함께, 이미지마다 정의 된 Matrix T는 학습되는 Parameter가 됩니다. T는 전체 Task에서 목표로 하는 결과값이기도 합니다. T는 rotation matrix R (3x3배열)과 transition vector t로 구성되어 있습니다.

Surface-based Photometric Loss
앞서 소개한 Loss로는 points마다 labeling이 안되어 있기 때문에, incorrect matching이 발생 할 수 있습니다. 때문에 추가로 surface에 관한 loss를 적용해서 이를 해결해줍니다. photometric 정보는 consistency를 가진다는 가정을 갖고, appearance difference를 사용해서 Loss가 설계되었습니다.
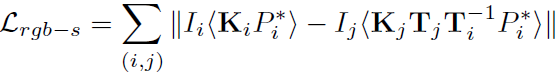
K는 3D point에서 2D Image로 projection하는 matrix입니다. <>는 pixel 샘플링을 나타냅니다.
Algoithm Summary

NoPe-NeRF는 RGB Image I와 Depth Estimation한 Depth Map D 가 주어졌을 때,
- NeRF Model로 RGB Image I^, Depth Map D^를 1차적으로 생성하면서,
- rotation matrix R (3x3배열)과 transition vector t로 구성되어 있는 camera pose parameter π^
- Depth Map에서 Undistorted Depth Map으로 변환할 때 쓰이는 scale factor α와 shift factor β에 해당하는 distortion parameter ψ^ 를 같이 생성합니다.
위 Loss를 최소화 함으로써 NeRF parameter Θ*와 camera pose parameter π*, distortion parameter ψ* 를 찾는 문제로 정의 될 수 있습니다. 결과적으로 novel view에 대한 이미지를 생성 할 수 있고, 입력 이미지에 대한 camera pose를 계산 할 수 있습니다.
Overall Structure
아래는 개인적으로 깊이 이해하려고 그려본 그림입니다. 논문에서 그려진 구조도의 색상을 맞췄습니다. 나중에 기회가 된다면 추가 설명하도록 하겠습니다.

비교를 위해 최초 NeRF 구조도도 첨부하겠습니다.

Experiments
데이터셋
2개의 Dataset으로 Test하였습니다.
Tanks and Temples : pose accuracy와 novel view synthesis quality를 평가하기 위해 사용 되었습니다. 960x540 해상도의 8개 Scene으로 구성되어 있습니다. family scene에 대해서 홀수 프레임은 trainset 짝수 프레임은 testset으로 사용했습니다. 나머지 7개 scene은 연속 프레임으로 1/8을 testset으로 사용하고 나머지는 trainset으로 사용했습니다.
ScanNet : pose accuracy, noview view synthesis quality에 추가로 depth accuracy를 평가하기 위해 사용 되었습니다. 648x484 해상도의 4개 scene으로 구성되어 있고, 80-100 연속 프레임 중에서 1/8을 testset으로 사용했습니다.
평가지표
Novel View Synthesis Evaluation에 대해서는 PSNR / SSIM / LPIPS 이전글 에 정리해두었습니다.
Pose Evaluation에 대해서는 ATE(Absolute Trajectory Error), RPE(Relative Pose Error)를 사용했으며, ATE는 추정된 camera position과 GT camera position 사이의 difference를 측정한 지표이고, RPE는 Image pair 사이의 상대 pose를 측정하는 지표입니다. RPE는 세부적으로 relative rotation error인 RPEr 과 relative translation error인 RPEt로 구성됩니다. 자세한 설명은 ATE / RPE 이전글 에 정리해 두었습니다.
Depth Evaluation에 대해서는 Abs Rel, Sq Rel, RMSE, RMSE log, δ1, δ2, δ3 을 사용했습니다.
Pose Estimation Comparision


COLMAP 결과를 GT로 두었고, SC-NeRF, NeRF--, BARF와 비교하였습니다. 모든 Scene에 대해서 높은 성능을 보였습니다. (그림이 작아서 잘 안보이는데 COLMAP결과가 빨간색이고 평가 대상 모델이 초록색입니다.)
Depth Estimation


(평가 수치 설명에 대해서는 다음으로 미루겠습니다...)
모든 평가지표에 대해서 높은 성능을 보였습니다. 심지어 전처리에 사용했던 Mono Depth Estimation인 DPT보다 좋은 성능을 보였습니다.
View Synthesis Quality

모든 경우에 높은 성능을 보였습니다. 이전에 리뷰하였던 Point-NeRF(CVPR202) 에서는 Camera Pose가 주어진 상태에서 학습되었고, Tanks데이터셋에서 평균 PSNR 29.61 / SSIM 0.954 / LPIPS 0.080 이었고, ScanNet 데이터셋에서는 평균 PSNR 30.32 / SSIM 0.909 / LPIPS 0.220 이었습니다. NoPe NeRF가 Camera Pose가 주어진 Point-NeRF보다는 좋지 않은 성능을 보입니다.
COLMAP과 성능 비교
NoPe-NeRF로 Pose Estimation하고 pose를 고정시킨 후에 original(최초) NeRF를 scratch부터 학습(Ours-r)시켰습니다. 비교군은 original NeRF의 기존 학습 방법과 동일하게 COLMAP으로 pose를 획득해서 학습(COLMAP+NeRF)했습니다.

Tanks 데이터셋의 3개의 Scene을 제외하고 PSNR기준으로 Ours-r이 더 좋은 성능을 보였습니다. 이를 통해 Pose Estimation관점에서 COLMAP보다 NoPe-NeRF가 더 좋은 성능을 보인다고 보았습니다.
COLMAP은 low-texture scene에서 성능이 안좋다고 알려져 있어서, 정확한 카메라를 획득하지 못하는 경우가 발생합니다. 이로인해 low texture 에서 COLMAP+NeRF로 학습할 경우에 Artifacts가 발생합니다. 아래는 이에 대한 예시 그림입니다.

위 표에서 Ours는 NoPe-NeRF를 사용하는 경우를 말하며, 이 경우에 초기 학습 단계에서 random으로 초기화된 pose로 잘못된 값으로 학습되었기 때문에 성능이 좋지 않았다고 말하고 있습니다.
Ablation Study & Limitation

각 Parameter가 성능에 어떤 영향을 주었는지를 Test하였습니다. NVS는 New View Synthesis약자입니다.
Effect of Distortion Parameters(2번째줄) : depth distortion을 처리하지 않으면(scale을 1로, shift를 0으로 상수처리하였을 때) Image 합성관점에서는 성능차이가 없었지만 pose accuracy에 대해 상당한 성능 저하가 발생하는 것을 확인하였습니다.
Effect of Inter-frame Losses(3,4번째줄) : inter-frame Loss를 제거하면 relative pose를 고려하지 않게 되게 됩니다. relative pose를 고려하지 않으면, accuracy가 낮아짐을 확인 할 수 있습니다.
Effect of NeRF Losses(5번째줄) : depth-map에 대한 distortion 최적화(=α, β 업데이트)는 inter-frame loss만으로 수행됩니다. 이로 인해, 누적 오차(drift)가 발생하고 pose accuracy가 낮아집니다.
Limitation : 입력 이미지의 카메라 pose가 비선형적 위치일 경우, 비선형적 Scale일 경우 고려되지 않았고, mono-depth estimation의 성능도 고려되지 않았다고 합니다.
Closing..
NeRF가 다양한 분야에서 실험적으로 사용되고 있는데, Novel View Rendering 뿐만 아니라 활용처가 점점 더 넓어지고 있다는 것을 느낍니다. NoPe를 120개 이미지로 구성된 Scene에 대해 학습 했을 때, 3060 GPU로 62시간 소요됬습니다. 아직은 학습 속도 관점에서는 아쉽습니다. 점점 학습 속도가 개선되고 Intrinsic Parameter 까지 추정 할 수 있으면 COLMAP 대신 카메라 Pose Estimation에 사용 될 것 같습니다.
'NeRF' 카테고리의 다른 글
| [논문 리뷰] F2-NeRF (CVPR 2023) : 속도 개선 + Unbounded Scene (4) | 2023.06.13 |
|---|---|
| [논문 리뷰] DreamFusion (ICLR 2023) : Text to 3D 연구 (6) | 2023.06.06 |
| [논문 리뷰] Mip-NeRF 360 (CVPR 2022) : Anti-Aliasing 연구2 (2) | 2023.04.22 |
| [논문 리뷰] FreeNeRF (CVPR 2023) : 적은 입력 + 퀄리티 개선 연구 (0) | 2023.04.14 |
| [논문 리뷰] NeuS (NeurIPS2021) : 3D Surface Reconstruction - SDF연구 (0) | 2023.03.07 |




댓글