논문명 : Point-NeRF: Point-based Neural Radiance Fields
Introduce
기존 NeRF 연구(이전 Post 참조) 대비 획기적으로 Training 속도와 퀄리티를 개선한 논문입니다.

DTU데이터셋에서 학습 2분만에 PSNR 28.43을 달성하게 됩니다. 20분 학습에 PSNR 30.12를 달성합니다. (PSNR 참조)최초 NeRF에서 20+시간 이상 학습한 Scene들에 대해서, PointNeRF는 20-40분 학습으로 더 좋은 퀄리티를 보였습니다. NeRF Synthetic 데이터셋으로 충분한 학습을 하였을 때는, 최신 NeRF연구들 대비 가장 좋은 퀄리티를 보였습니다.
PointNeRF을 요약하여 간단히 설명하자면,
Point-NeRF에서는 연속 볼륨 radiance 공간을 모델링하기 위해 3D neural point cloud를 사용하였습니다.
- 장면마다 fitting 의존성 있는 초기 NeRF와 달리, PointNeRF는 pre-trained된 DNN을 통해 효과적으로 DNN값을 Initialize하여 사용하였습니다.
- 실제 scene geometry를 approximate하는 전통적인 point cloud기법을 사용해서 empty 공간의 ray sampling을 효율적으로 하였습니다.
- Initial field를 생성하기 위해, Multi-view Stereo(MVS) 기법을 사용하였습니다. MVS는 3D sapce로 unprojected되는 depth를 예측하기 위해 cost-volume기반의 네트워크를 적용하였습니다.
Volume rendering하면서 geometric reasoning를 하고 high volume density영역에 point cloud 경계와 가까운 point들을 grow하고, low volume density영역에서는 pruning하였습니다.
자세한 내용을 아래 알고리즘 파트에서 소개하겠습니다.
Algorithm
논문의 서술방법과 달리 알고리즘이 수행되는 순서대로 정리해봤습니다.
① Neural Point Cloud를 생성합니다.
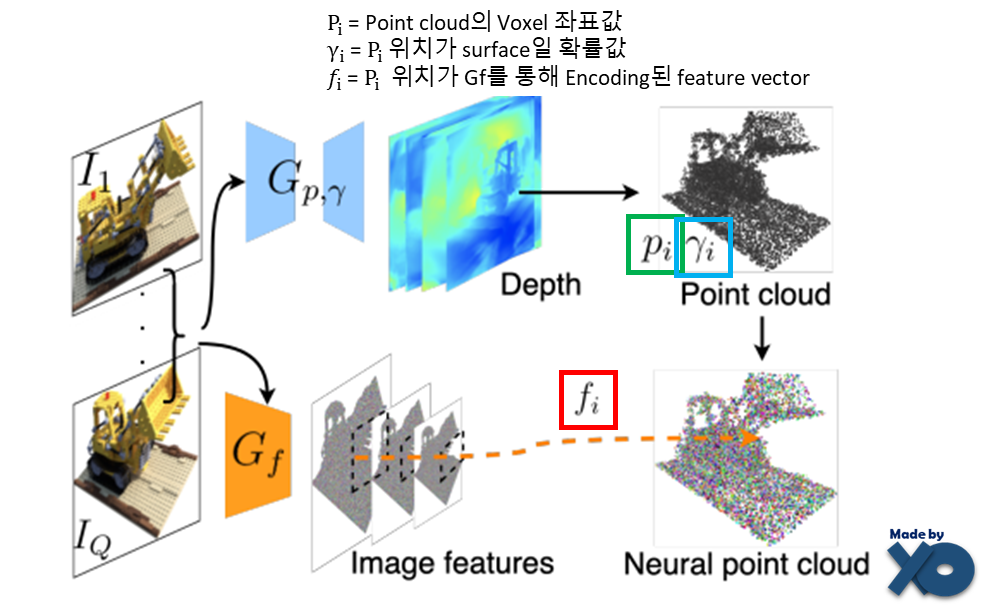
Multi-View Stereo(MVS)기법으로, depth를 추정하고, point cloud를 생성합니다.
- Gp,r는 MVSNet을 사용해서 여러장의 이미지와 카메라 parameter를 입력으로 받아 Point cloud 좌표값 p가 surface일 확률값(point confidence) γ을 출력합니다.
- Gf는 이미지들을 VGG Network에 통과시킨후, 중간 layer의 값들을 feature vector로 만들고, point cloud 내 point로 unprojection시켜, voxel좌표(p)에 feature vector(f)를 맵핑 시킵니다.
+ DTU Train dataset으로 Pretrain합니다.
+ 3개 input view로부터 neural point cloud를 생성하는데, feed-forward network로 inference시간이 0.2초 소요됩니다.
+ PixelNeRF(2021), IBRNet(2021) 에서는 2D형태로 feature가 구성되었지만, PointNeRF에서는 3D 형태로 구성하게 됩니다.
② Ray를 통해 point를 샘플링하고, feature를 추출합니다.
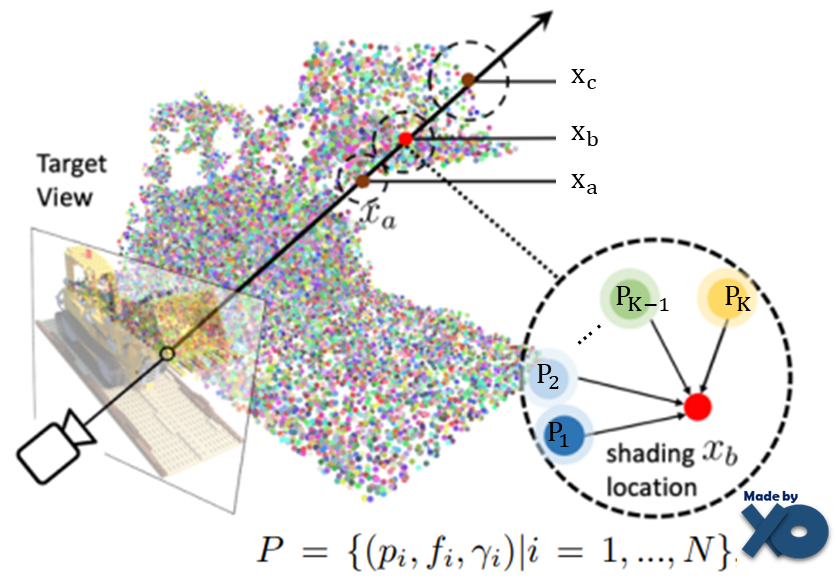
최초 NeRF와 동일한 방법으로, 입력 이미지의 각 픽셀에 view direction 으로 ray를 그리고, ray위에 point들을 샘플링 합니다.
3차원 voxel 좌표 x가 주어지면, radius R안에 위치한 K개의 가까운 neural point들을 탐색합니다.
최초 NeRF와 다르게, 샘플링시에 neural point confidence값을 사용하여, Empty space에서 불필요한 sampling을 피하여, 속도가 개선 되게 됩니다.
③ F Network를 통해, new feature 를 만들어냅니다.
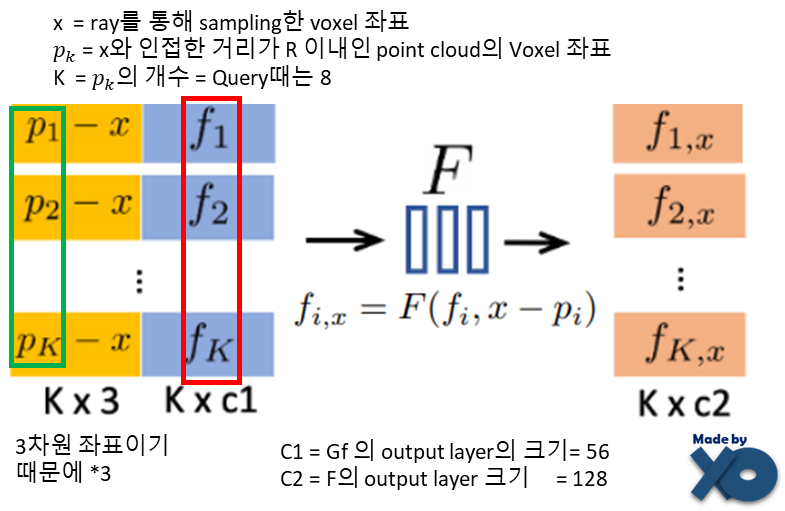
‘Sampling한 point x와 근접 neural point p 사이의 거리값’과 ‘해당 p의 feature값’을 입력으로 F Network를 통과시켜, new feature를 출력합니다.
상대적 위치 x-p를 사용하여 point translation 에 대해 network 를 invariant 하게 만들어 일반화 시킵니다.
입력과 출력이 모두 f로 표현하였는데, 인자가 1개인지 2개인지로 구분하면 됩니다.
④ T Network를 통해 volume density를 계산합니다.

fi,x를 입력으로 하여, density를 구하고, sampling point x와 근접 neural point 좌표 p와의 거리를 weight로 하여 weighted sum 하여 volume density를 계산합니다. 이를 통해 가까운 neural point의 기여도를 높여주는 역할을 합니다.
논문에서는 이를 Inverse distance-based weighting 라고 표현했습니다.
최초 NeRF와는 다르게, neural point의 confidence값(γ)도 explicit하게 수식에 사용되었습니다. 이를 통해 불필요한 point를 제거하는 역할을 하게 됩니다.
⑤ R Network를 통해 view-dependent Radiance 를 계산합니다.

Volume density에 계산했던 weight sum과 동일한 방법으로, new new f를 계산합니다.
같은 알파벳 f을 다른 용도로 3번 써서 헷갈리게 합니다. Neural point의 f와 동일하지만, 이 단계에서도 인자수로 입,출력을 구분하시면 됩니다.
단계 ④ 에서는 T Network를 통과한 후에 weighted sum했지만, 여기에서는 R Network를 통과하기전에 weighted sum이 되었습니다.
View Direction을 최초 NeRF와 동일한 방식으로 계산하고, new new f와 함께 Network R의 입력으로 넣어줍니다.
Weight Udpate & Optimization
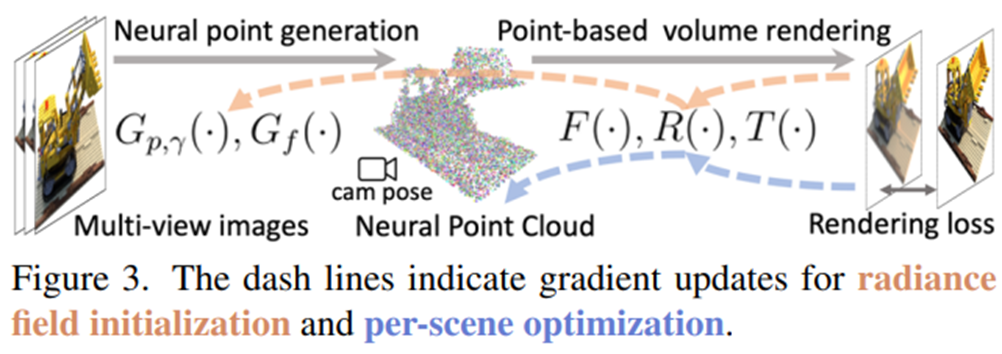
Pretrain 과정과 Train과정이 구분되어 있습니다.
Pretrain과정에서는 Neural Point Cloud는 DTU Train데이터셋으로 학습을 진행합니다.
그리고 Gp,r Gf를 고정한 상태에서 다양한 데이터셋으로 Scene(Object)마다 F,R,T를 학습합니다.
Feature를 추출하는 네트워크를 고정한 상태에서, Rendering을 위한 네트워크를 Optimization한다고 생각하면 됩니다.
Pretrain을 통한 Weight initialization통해, Scene마다 수렴 속도가 빨라지게 됩니다.
최초 NeRF와 PointNeRF 비교

최초 NeRF는 이미지 각 픽셀에 대해 ray를 그려 voxel point 들을 샘플링하고, voxel point 마다 좌표와 view direction를 입력으로 volume density 와 radiance 를 구한 뒤에, Volume Rendering 수식으로 2D Pixel에 대한 color값을 계산하게 됩니다.
PointNeRF는 Neural Point Cloud를 통해 3D 공간 상에서 voxel point 마다 Feature, confidence 를 먼저 구성합니다. 이러한 구성을 기반으로, 샘플링된 point와 neural point간의 거리 정보로 weigh를 구성하고, neural point confidence 값을 사용해서, volume density 와 radiance 값을 계산하게 됩니다.
최초NeRF와 같은 방식으로 Volume Rendering 수식으로 2D Pixel에 대한 color값을 계산합니다.
Point pruning, growing
Neural Point cloud를 최초로 구성하게 되면, hole과 outliner 가 발생하게 됩니다.
T와 R network에서 neural point confidence 는 volume density 와 Radiance 값에 직접적으로 영향을 미치게 됩니다.
이 문제를 해결하기 위해, 새로운 Scene에 대해 optimization 을 하는 동안 point pruning 과 growing 기법을 적용하였습니다.
Point Pruning : Scene마다 Optimization과정에서 10K iteration마다 0.1보다 적은 confidence 를 가진 point들을 제거 합니다. Sparsity loss 도입하여 confidence 값이 0 또는 1에 가까워지게 설계하였습니다.
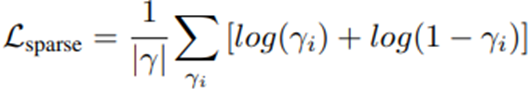
Point growing : ray마다 샘플링된 포인트 x에 대해, 아래 수식으로 ray마다 가장 높은 opacity 를 가진 x를 찾습니다. Jg는 ray내 가장 opacity 가 높은 인덱스를 나타냅니다.

해당 인덱스의 point의 volume density 가 Topacity 상수보다 크고, neural point와 거리가 Tdist 상수 보다 클 때, neural point를 추가해줍니다. 아래는 1000 neural point를 시작으로 150K iteration까지 진행했을 때, neural point가 구성되는 과정을 그렸습니다.

Experiments
Evaluation on the DTU testing set

오른쪽 표에서 finetuning으로 PointNeRF 10K iterations이 가장 좋은 결과를 보여줍니다.
- IBRNet의 PSNR이 높지만, 실제로 눈으로보면 PointNeRF의 세부 디테일이 좀더 정확합니다.
IBRNet이 large global CNN을 이용하지만, PointNeRF는 optimize하기 쉬운 작은 MLP를 가진 local point feature를 쓰고, empty sapce의 ray point 샘플링을 안하기 때문에, PointNeRF가 훨씬 빠릅니다.
IBRNet처럼 좀더 복잡한 feature extractor는 퀄리티를 향상하지만, memory 사용량과 학습 효율성에 부정적인 영향을 미칩니다.
PointNeRF의 1K-iteration이 MVS-NeRF의 10k-iteration와 비슷한 quality를 보였습니다.
왼쪽 표에서 fine-tuning없을 때의 결과를 보여줍니다.
- IBRNet, MVSNet은 좀더 복잡한 variance-based feature extraction을 사용하기 때문에, Fine-tuning없이 PointNeRF의 direct inference가 IBRNet, MVSNet보다 훨씬 안좋습니다.
PointNeRF와 유사하게 VGGNet으로 featrue를 추출하는 PixelNeRF와 비교하면, PointNeRF의 Initial radiance field가 PixelNeRF보다 훨씬 좋다는 것을 볼 수 있습니다.
PixelNeRF도 같은 VGGNet을 사용하지만, PointNeRF는 Surface-adaptive point-based representation를 사용했기 때문에 PointNeRF가 더 좋은 결과를 보였습니다.
Evaluation on the NeRF Synthetic dataset

Point-based rendering model인 NPBG(2020) / generalizable radiance field method인 IBRNet(2021) / per-scene radiance reconstruction techniques인 NeRF(2020)와 NSVF(2020)와 결과를 비교하였습니다.
DTU 데이터셋으로 purely training하여서, 완전히 다른 카메라 distribution을 가진 다른 데이터셋에도 일반화가 잘되었습니다.
Comparisions with generalizing methods
- NeRF Synthetic 데이터셋은 360도 카메라 distiribution 데이터를 가집니다.
MVSNeRF와 같은 함수는 3개의 input image로부터 local perspective frustum volume을 recover하기 때문에 360도 rendering을 적용할 수 없습니다.
어떤 임의의 갯수로 free-viewpoint rendering을 잘 handling하는 (generalize 관점에서 최고인) IBRNet과 비교하였을 때, PointNeRF가 더 좋은 퀄리티를 보임. PointNeRF 20K에서는 PSNR,SSIM이 능가하였고, 200K에서는 모두 능가하였습니다.
Comparisons with pure per-scene methods
- 200K iteration 학습한 NeRF와 20k iteration 학습한 PointNeRF가 비슷한 성능을 보였습니다. PointNeRF 20K iteration은 40분 소요됬고 NeRF는 20+시간이 소요됬습니다. 이는 최소 30배 더 빠르다는 것을 보여줍니다.
NSVF는 per-scene optimization이 상당히 오래 걸리는데 PointNeRF 40분의 결과보다 약간 좋습니다.
PointNeRF 200K iteration은 다른 모든 알고리즘보다 성능이 좋고, Ship Scene에서 디테일한 것까지 표현하는 것을 보여줍니다.
Comparisions with point-based rendereing
- PointNeRF와 같이 MVSNet로부터 생성하는 point cloud를 사용하는 NPBG와 비교하였을 때, blurry한 랜더링이 될 수 있었습니다.
PointNeRF에서는 neural radiance field를 갖고 volume rendering을 하였기에 photo-realistic result를 보였습니다.
Evaluation on the Tanks & Templets and the ScanNet dataset

PSNR / SSIM / LPIPS 순서로 평가 결과가 표기되어 있습니다.
Additional experiments
Converting COLMAP point clouds to Point-NeRF
- PointNeRF는 다른 point cloud 생성 기술을 사용해서 point-based radiance field로 convert 할 수 있었습니다.
COLMAP point cloud를 사용해서 NeRF synthetic 데이터셋을 실험하였고 "Evaluation on the NeRF Synthetic dataset"를 소개한 표에 Point-NeRF col 200k 라는 열이 실험 결과입니다.
COLMAP point cloud는 많은 구멍과 노이즈가 포함되기 때문에, 많은 point growing과 pruning이 필요해서, 200K iteration을 하였습니다 (아래 의자 이미지가 COLMAP을 통해 만든 결과 참조)
이를 통해, Low-quality point cloud라도 높은 퀄리티를 보임을 볼 수 있었고, 다른 Point cloud reconstruction 기술들과 조합해서 사용 할 수 있음을 보여 줍니다.
Point growing and pruning

- Point growing과 pruning없을 때의 실험 결과를 비교하였고, MVSNet를 사용한 기본 모델과 COLMAP point clouds을 사용한 모델로 실험하였습니다.
순서대로 PSNR / SSIM / LPIPS Vgg이고, 모든 경우에 상당한 효과를 보였습니다.
Hotdog scene에서 outlier point가 pruning될 수 있었고(왼쪽사진), hole이 fill될 수 있었습니다(오른쪽 사진).
아래 의자 그림은 Extreme한 예제로 샘플링된 1000개 points로 시작으로해서, point growing을 보여줍니다. Iteration을 통해 전체 scene surface를 채울 때까지 new point가 점진적으로 grow될 수 있음을 보여줍니다.
Low-quality point cloud로 부터 정확한 scene geometry와 appearance를 recovery를 효율적으로 할 수 있다는 것을 보여줍니다.
Conclusion
Neural point cloud를 갖고 volumetric radiance field를 모델링하는 것을 보였습니다. Direct network inference로 좋은 initialization을 구성하였고, 그 initialization으로 각 scene에 대해 효과적으로 fine-tune하였습니다. Scene마다 NeRF가 20+시간 동안 학습하였던 것을 20-40분만에 optimization하였고 퀄리티도 더 좋았습니다. Per-scene optimization을 위한 growing과 pruning 기술은 상당한 성능 향상을 보였고, 다른 point cloud quality에도 robust하였습니다. PointNeRF는 classical한 point cloud representation과 neural radiance field representation둘다의 이점을 잘 조합하였습니다. 결과적으로 PointNeRF는 high efficiency이면서 realistic이고 실용적인 scene reconstruction을 만들었습니다.
'NeRF' 카테고리의 다른 글
| [논문 리뷰] MVSNeRF (ICCV2021) : 적은 입력 + 학습 속도 개선 논문 (0) | 2022.10.27 |
|---|---|
| [논문 리뷰] Plenoxels (CVPR 2022) : 학습 속도 개선 논문 (0) | 2022.10.20 |
| [논문 리뷰] PlenOctrees for NeRF (ICCV 2021) : 랜더링 속도 개선 논문 (4) | 2022.10.12 |
| [논문 리뷰] PixelNeRF (CVPR 2021) : 입력 이미지 갯수를 개선한 NeRF 연구 (0) | 2022.10.11 |
| [논문 리뷰] NeRF (ECCV 2020) : NeRF 최초 논문 (3) | 2022.10.08 |




댓글