DREAMFUSION: TEXT-TO-3D USING 2D DIFFUSION, Ben Poole, arXiv2022, Google Resarch
Dream Fusion에서는 NeRF와 Diffusion Model기반의 Text-to-2D 모델을 사용해서 Text-to-3D 방법을 제시합니다.
유사한 이전 연구인 Dream Fields(2022)는 NeRF와 Contrastive learning 을 사용한 text to image 모델인 CLIP를 기반으로 text to 3D 방법론을 제시했었습니다. 본 연구에서는 Diffusion Model 사용한 text-to-2D 연구인 Imagen과 inverse rendering 이 가능한 NeRF를 기반으로 이전 연구보다 더 좋은 퀄리티의 Text to 3D 방법이라고 소개하고 있습니다.
논문의 contribution은 3D dataset 학습데이터 없이 Text-to-3D모델을 생성 할 수 있다는점, Diffusion모델을 사용한 Text-to-3D 모델이라는 점입니다.
DreamFusion은 크게 "Diffusion Model기반의 Score Loss", "3D model의 Neural Rendering", "Text to 3D Synthesis"으로 내용 순서로 구성되어 있습니다. 가독성을 위해 글의 순서를 거꾸로 바꾸었습니다. 그리고 중간중간에 논문에 없는 부연적인 설명을 추가로 넣었습니다.
아래 두개 글의 서론 부분만 읽고 오는 것을 권장합니다.
NeRF : [논문 리뷰] NeRF (ECCV 2020) : NeRF 최초 논문
Diffusion Model : [개념 정리] Diffusion Model 과 DDPM
Overview

전체 구조 파악을 위해, 수도코드를 작성해봤습니다.
## Training Process ##
random weight로 NeRF를 initialization
for iteration in range(15000):
1. random한 camera 위치와 각도, random한 light 위치와 색상을 sampling
2. NeRF로 이미지를 rendering
3. NeRF parameter들과 text embedding값으로 SDS(Score Distillation) Loss를 계산
4. NeRF의 weight를 update
## Test Process ##
학습된 NeRF weight로 특정 camera 위치, 각도에서 NeRF로 이미지를 합성하나씩 간략하게 소개하겠습니다.
1. Random camera & light sampling
3D model은 bounding sphere 로 제한됩니다. 3D model은 구안에 존재하고, spherical coordinates(구면 좌표계) 로 카메라 위치가 샘플링 됩니다. (그림 출처 : link)

- x,y평면의 회전각 azimuth angle Φ은 0~360도 사이의 값으로 sampling하고, z축으로의 회전각 elevation angle θ은 -10~90도로 sampling하고, 구의 반지름 r은 1~1.5 로 sampling하였다고 합니다. (위 그림 기준으로 설명드렸으며, 논문에서 notation은 Φ와 θ 가 바뀌어져 있습니다.)
- 샘플링한 구의 표면의 점에서 구의 원점을 바라보게(Look at)하게 하고, 카메라의 위쪽을 up vector방향으로 지정하였습니다. (OpenGL look at 함수 참조 : link)
- Focal length는 w(=width=64) 에 0.7~1.35로 균등하게 나눈 상수 λ값을 곱해서 사용했습니다.
- Light 의 위치는 카메라 위치를 중심으로 한 확률분포로부터 sampling하였습니다.
카메라 위치의 범위가 넓을수록 일관된 3D Scene을 합성하는 것이 어려웠고, 카메라 거리 범위가 넓을수록 퀄리티 관점에서 좋아졌다고 합니다.
2. Rendering
Sampling한 camera pose, light position을 사용해서, 64x64 해상도로 shade된 NeRF를 Rendering 합니다.
기존 NeRF와 다른 점은 3가지의 rendering 방법을 랜덤하게 사용한다는 점입니다.
1) shading없이 albedo ρ로 랜더링(=최초 NeRF와 동일)
2) shading하여 랜더링
3) albedo ρ 를 white로 바꿔서 shading하여 랜더링
아래 shading 부분에서 2),3)에 대해 설명드리겠습니다.
3. Diffusion loss with view-dependent conditioning
Imagen모델을 사용 할 때 약간의 text prompt engineering이 들어가게 됩니다. Elevation angle이 60도 이상일 때 “overhead view”, 그 외 azimuth angle에 따라 “front view”, “side view”, back view”라는 단어를 생성하고자 하는 Text 문장에 덧붙여주었다고 합니다.
( Imagen 모델은 T5-XXL text embedding으로 large-scale web-image-text데이터로 학습하였습니다. Noise level이 너무 크거나(t=1) 작은 경우(t=0)에 수치상 instability가 있었기 때문에, t는 0.02~0.98로 균등하게 샘플링하였고, classifier-free guidance weight인 w를 100으로 셋팅해서 퀄리티를 높였다고 합니다. 너무 적은 weight를 사용할 경우, object를 표현하는 중간값을 찾기 때문에 over smoothing되는 현상이 발생했다고 합니다. )
NeRF로 생성된 이미지, timestep t, text embedding y가 주어지면, Diffusion model의 noise ε로 샘플링하고 SDS loss를 계산하여 NeRF의 Gradient를 업데이트 해줍니다. SDS loss에 대해서 뒤에서 설명 하겠습니다.
4. Optimization
TPUv4로 학습을 진행하였으며, 15,000 iteration으로 약 1.5시간 소요됬습니다.
각 cpu는 개별적인 view를 랜더링하고, batch size를 1로해서 diffusion U-Net을 evaluation하였습니다.
Distributed Shampoo optimizer를 사용했다고 합니다.
3D model의 Neural Rendering
Shading
기존NeRF는 Ray방향에 따라 달리 보이는 3D point 좌표들의 radiance color ρ들로 2D pixel의 color C를 계산하였지만,
DreamFusion는 위 방식에 추가로, 추가 조명에 따라 달리 보이는 surface color c들로 2D pixel color C를 계산합니다.
상세히 설명하기 위해, 기존 NeRF와 DreamFusion의 구조를 그려봤습니다.

실제적으로 DreamFusion에선 NeRF는 Mip-NeRF 360를 사용합니다. 본 글에서는 DreamFusion의 설명에 초점을 맞추기 위해서 Mip-NeRF360과 입/출력값이 동일한 최초 NeRF모델을 도식화해 비교했습니다. 위 그림에 대해서는 최초 NeRF 이전글 설명 참조바라며, Mip-NeRF 360 이전글에서 NeRF와 Mip-NeRF 360의 차이점을 확인하시길 바랍니다. (DreamFusion에선 Appendix A.2에 Mip-NeRF 360에 대해 소개하고 있습니다.)
NeRF와 DreamFusion의 MLP 부분은 동일합니다. 3D points 좌표 μ 와 view direction θ 입력값으로 volume density τ 와 albedo ρ를 출력합니다. NeRF에서는 ray위의 point들의 τ,ρ로 volume rendering 공식을 사용해서, 최종 Color C를 계산합니다. (대소문자 유의)
DreamFusion에서는 추가적으로, volume density τ를 surface 위 3D 좌표 μ에서 2번 미분(▽:nabla)하여 normal vector n을 계산하였습니다. (NeRV연구 3.2 마지막 6줄+ 4.2 참조)

그리고 light 3D point 좌표ℓ 에서 발산되는 조명 색상 ℓp 과 ambient 조명 색상 ℓα 를 가정하여, diffuse reflectance (입사각과 동일하지 않은 반사각을 갖는 반사)가 아래 수식으로 고려되어,

최종적인 Color C를 계산하게 됩니다.

랜덤하게 albedo ρ 를 white color(1,1,1) 로 바꿔주게 되면, 텍스처가 없는 shaded output을 만듦으로써, 성능이 향상되었다고 합니다. Text condition을 만족시키지만 flat한 geometry가 그려 질 수 있는데, 해당 방법을 통해 3D 형태로 만들어지게 하였다고 합니다. 이 부분이 위의 rendering파트에서 언급한 "albedo ρ 를 white로 바꿔서 shading하여 랜더링"에 해당하는 부분입니다.
Scene Structure
앞에서 이미 한줄로 소개 했지만, 고정된 bounding sphere 내에서 NeRF로 다양한 카메라 position의 view들을 generation을 했을 때 좋은 성능을 보였다고 합니다. 카메라의 범위가 고정되었을 경우 수렴이 빠르게 되기 때문으로 추측됩니다.
배경 색상을 계산하는 2번째 MLP를 사용해서, environment map을 생성하고, 그 위에서 Ray를 rendering함으로써 좋은 성능을 보였습니다. 기존 연구들에서 카메라와 가까이에 있는 공간에 density가 채워지는 현상을 막기 위해 위와 같은 방법을 사용했습니다. (Mip-NeRF360, FreeNeRF 에서 이러한 문제가 언급됬었습니다.)
카메라로부터 그려지는 ray는 누적 alpha값으로 구성됩니다. 배경이 보이면 배경에서 누적 alpha값이 1이고, 배경이 닿기 전에 사물이 있으면, 배경에서 누적 alpha값이 0됩니다.
Geometry Regularizer
Empty 공간이 불필요하게 채워지는 것을 막기 위해, DreamField의 regularization penalty 방식을 사용했습니다. 아래 수식은 DreamField 4.5 단락에서 가져왔습니다. Parameter θ와 카메라 pose p를 입력으로 하는 Transmittance값과 최대값 상수 τ로 구성된 수식입니다.

추가로, Normal vector의 back-facing(물체 안으로 향하는?) 문제를 막기 위해, Ref-NeRF에서 제안한 orientation loss (ReF-NeRF 단락4 참조)를 사용했습니다. 위에서 언급한 texture가 없는 white shading을 포함하면 카메라로부터 normal vector 들이 멀어지게 된다고 하며, 이 white shading 을 dark 하게 만들기 위해서, orient loss를 사용했다고 합니다. 아래 수식은 ReF-NeRF 에서 갖고 온 수식입니다. N’은 predicted된 normal 이고, d는 ray direction 입니다. 둘을 dot product한 후, (visible) weight 곱하고 summation하여 계산됩니다.
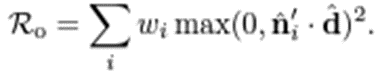
SDS(Score Distillation Sampling) Loss
다른 Text-to-3D 논문에서도 많이 참조되는 Loss라서 별도의 글로 정리해두었습니다. -> SDS Loss 설명 바로가기
Experiments
zero-shot text-to-3D 생성 모델과 비교하였고, 다양한 text prompt로 일관된 3D scene을 생성하는지 평가하였습니다. 3D reconstruction task는 일반적으로 recovered geometry와 GT간의 Chamfer Distance(reference-based metrics)를 계산해서 평가합니다. view-synthesis 분야에서는 rendered된 view와 GT를 비교하는데 PSNR을 사용합니다. 이러한 평가 방법들은 zero-shot text-to-3D generation에선 text prompt에 대한 3D GT를 만들 수 없기 때문에 사용하지 못합니다. Dream Field에서 했던 방식과 동일하게, 입력 문장에 대한 랜더링된 이미지의 일관성을 측정하는 CLIP R-Precision로 평가하였습니다. CLIP에 대해선 CLIP 개념 이전글 확인 바랍니다. R-Precision은 랜더링된 이미지가 주어질 때, CLIP모델이 오답 텍스트들 중에서 적절한 텍스트를 찾는 정확도(Accuracy)로 계산되어집니다.
Dream Fields연구에서 다뤘던 object-centric COCO validation 데이터의 subset인 153개의 prompt를 사용하였습니다. 기존 평가 지표는 geometry의 quality를 측정 할 수 없기 때문에, flat한 geometry에서도 높은 평가 결과값이 나올 수 있습니다. 때문에 본 연구에서는 geometry를 측정하기 위해, textureless render의 R-Precision을 추가로 측정하였습니다.

GT Image(=oracle=CLIP 학습에 사용된 데이터셋), Dream Fields, CLIP-Mesh(CLIP으로 mesh를 optimize한 연구)와 DreamFusion를 평가하였습니다. Dream Fields 밑에 (reimpl.)은 본 연구에 사용한 3D representation으로 재구현하였다고 표시되어 있는데, 제 개인적인 추측으론 고정된 bounded 구(sphere)형태로 representation하는 것이라 생각됩니다. DreamFusion은 학습시에 Imagen모델을 쓰고 비교군인 Dream Fields와 CLIP-Mesh는 학습시에 CLIP을 사용하기 때문에 비교군이 더 성능이 좋아야 하지만, DreamFusion이 color image 평가에서 높은 성능을 보였습니다. 그리고 Geometry 평가에서 Dream Fields보다 DreamFusion이 더 좋은 성능(=58.5%의 텍스트 일관성)을 보였습니다.
Ablations

어떤 optimization 방법이 좋은 성능을 만들었는지 파악을 위한 실험입니다. 아래 4가지 방법이 점진적으로 더해지게 됩니다.
- viewpoints의 범위를 넓히는 방법(ViewAug)
- view-depedent한 prompt engineering (ViewDep)
- 추가인 조명 사용 (Lighting)
- albedo를 white로 만들어 shading한 방법 (Textureless)
Geometry의 퀄리티를 확인하기 위해, 위에서 언급한 Render Type에 따라, Albedo renderer, full shaded renderer, textureless renderer로 구분해서 테스트하였습니다.
Geometry관점에서 3번째 Render Type에 5번째 막대를 보면 상당한 영향력이 있다는 것을 볼 수 있습니다. full rendering의 경우 0.125의 성능 향상이 있었습니다. albedo만 사용할 경우 평가 결과가 잘못 될 수 있다는 것을 아래 그림에서 보여줍니다. albedo render type에서는 좋은 성능을 보였지만, 그림을 보면 geometry는 좋지 않는 것을 볼 수 있습니다.

정확한 geometry를 만들기 위해선, view-depedent prompt와 illumination, textureless render이 필요하다는 것을 도출 할 수 있습니다.
Limitation
SDS는 image sampling을 적용할 때, 완벽한 loss 함수가 아닙니다. 종종 ancestral sampling(=CLIP결과?)에 비해서 oversaturated하고 oversmooth한 결과를 만드는 것을 보였습니다. dynamic thresholding 연구(2022)에서 부분적으로 이 문제를 해결하였지만, NeRF에서는 해결 할 수가 없었습니다. ancestral sampling(=CLIP결과?)와 비해서 SDS를 사용해서 만든 2D image sample은 다양성이 부족했습니다. variational inference와 probability density distillation의 context에서 중간값을 찾는 특성을 가지는 reverse KL divergence이 기반이 되어서 이런 문제가 발생할 것 이라고 추측하고 있습니다.
(해석이 애매한 부분은 밑줄로 했습니다. 참고만 하시길 바랍니다.)
64x64 Imagen model을 사용함으로써 높은 퀄리티로 생성이 안됩니다(=fine detail을 고려하지 못합니다). higher-resolution diffusion model과 더큰 NeRF모델을 사용할 경우 가능할 수도 있지만, (실용적이지 않게) 느려지게 됩니다.
2D observation으로 3D를 reconstruction하는 문제는 ill-posed(잘못된 포즈)로 이해되어져서, 이러한 모호성이 3D 합성 결과물에 반영되게 됩니다. 근본적으로 inverse rendering이 어렵기 때문에, text-to-3D를 하는 것이 어렵습니다. 유일한 2D 이미지라 할지라도 무수한 가능성의 3D world가 존재 할 수 있기 때문입니다. text-to-3D task의 optimization landscape는 highly non-convex이고, 많은 디테일한 작업들이 local minima를 피하기 위해 구체적으로 설계되어질 수 있습니다. 하지만 이렇게 설계 할지라도 flat한 surface에 paint되어지는 것 과 같이 한번씩 local minima에 빠지게 됩니다. 본 연구에서 언급한 기술이 effective하더라도, 2D observation을 3D world로 변환하는 작업은 항상 모호성이 내재합니다. 그리고 보다 강인한 3D prior의 이점을 얻을 수 있습니다.
Closing..
2021년 이전까지만 해도 3D data 없이 3D 생성 모델을 만들기 어려웠는데 Text-to-2D분야가 발전하고 NeRF분야가 발전하면서, 이런 연구 분야가 새롭게 만들어 질 수 있었던것 같습니다. 해당 논문을 시점으로 후속 논문들이 diffusion model 과 nerf를 사용해서 text-to-3D 연구가 많아졌습니다. 개인적으로 diffusion model을 좀 더 공부하고, 가능한 많은 Text-to3D 논문들을 보면서 자세한 설명을 시도해보겠습니다.
'NeRF' 카테고리의 다른 글
| [논문 리뷰] TensoRF (ECCV 2022) : 메모리/속도 개선 (1) | 2023.07.30 |
|---|---|
| [논문 리뷰] F2-NeRF (CVPR 2023) : 속도 개선 + Unbounded Scene (4) | 2023.06.13 |
| [논문 리뷰] NoPe-NeRF (CVPR 2023) : Camera Pose Estimation & NeRF (3) | 2023.04.29 |
| [논문 리뷰] Mip-NeRF 360 (CVPR 2022) : Anti-Aliasing 연구2 (2) | 2023.04.22 |
| [논문 리뷰] FreeNeRF (CVPR 2023) : 적은 입력 + 퀄리티 개선 연구 (0) | 2023.04.14 |




댓글