논문명 : NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (ECCV2020)
Introduce
현실 이미지를 다양한 카메라 각도에서 High Quality로 Rendering하는 방법에 관한 연구입니다.
2020년 ECCV에서 최초로 발표 된 후, 주목을 받으며 계속적으로 관련된 많은 논문들이 발표되고 있습니다.
( NeRF 개선방향 및 연구동향 글 참조 바랍니다.)
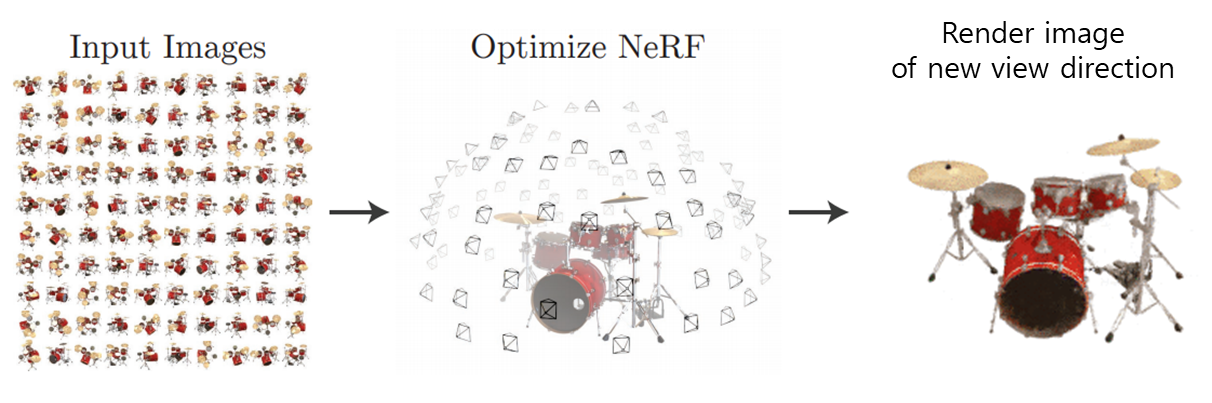
입력으로써 ‘카메라 시점’과 ‘해당 시점에서 촬영한 이미지’가 50~100쌍 주어질 때, 입력에 없는 ‘카메라 시점’에서 보여질 장면을 Rendering합니다.
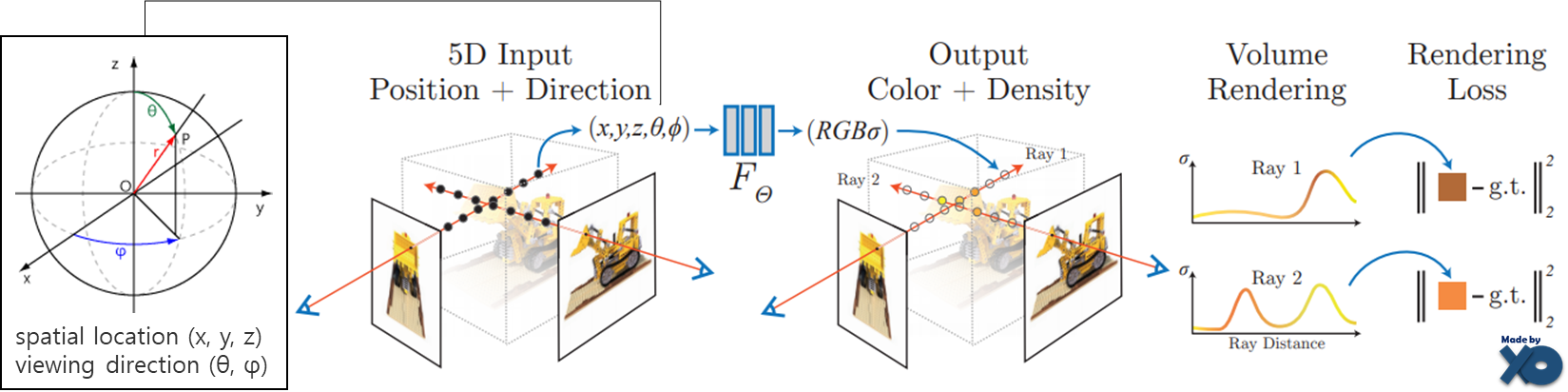
- 2D Image와 카메라 시점 정보로 ‘2D Pixel 좌표’ 1개 점에 맵핑되는 ‘3D Voxel 좌표’위치를 계산 할 수 있고, 반대로 3D Voxel 좌표들의 Color값과 Density값의 SUM으로 각 2D Pixel의 RGBA을 표현 할 수 있습니다.
- Train시, 카메라 시점(𝜃,𝜙)와 voxel 좌표(x,y,z)를 입력으로 하고, RGB와 Volume Density(𝜎)를 출력으로 하는 함수F를 정의하여, FCN(Fully Connected Network)으로 함수F 모델을 학습합니다.
- Inference시, 새로운 카메라 시점(𝜃,𝜙)이 입력으로 주어지면, Train한 모델로 3D Voxel 좌표에서의 RGB𝜎값을 계산한 후, 대응되는 2D Pixel 좌표로 Summation함으로써 색상 값을 Prediction합니다.
전체 프로세스를 도식화 해봤습니다. 입/출력값만 훑어보시고, 아래 세부 개념을 읽은 후에 다시 보시길 바랍니다.
Train Process

- 각 2D Pixel 좌표 마다 View Direction(카메라 시점)으로 3D공간상에 Ray를 그린 후, Ray위의 Voxel 좌표들을 Sampling합니다.
- FCN을 통해 모든 3D Voxel에 대해, Radiance와 Density를 계산합니다.
- 그 Radiance와 Density로 2D Pixel의 RGBA값을 아래 수식으로 계산합니다.
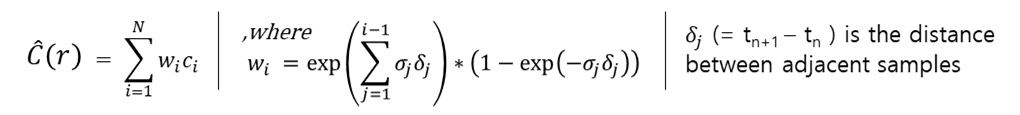
- Pixel마다 실제 색상 값과 예측한 색상 값으로 L2 Loss값을 계산 할 수 있습니다.
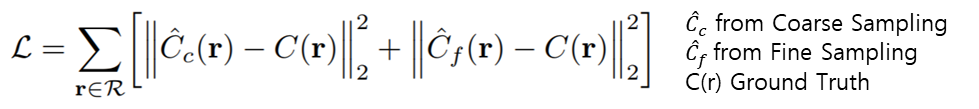
Inference Process

학습이 완료되면, 새로운 View Direction이 주어졌을 때 pixel 좌표마다 색상 값을 계산 할 수 있습니다.
소스 코드 분석한 내용 정리해두었습니다. 참고해서 같이 보시면 됩니다.
-> [NeRF] - [소스코드 분석] NeRF (ECCV2020)
Algorithm
다음으로 NeRF 알고리즘을 구성하는 3가지 개념에 대해 하나씩 다뤄보겠습니다.
- Color Rendering : Radiance을 예측
- Voxel Sampling : 연산량을 줄이기 위한 3차원 좌표 Sampling
- Positional Encoding : 학습 할 Input Feature를 증강
Color Rendering
2D Pixel좌표마다 View Direction(θ,ϕ) 방향으로 Ray를 쏘고, Ray위에 N개의 3D Voxel좌표(x,y,z)를 Sampling합니다. N개 중 i번째 3D Voxel좌표와 View Direction(θ,ϕ)를 MLP의 입력 값으로 넣어, volume density(σi) 와 radiance(ci = RGB)를 계산합니다.
이 때 사용되는 MLP는 다음과 같습니다.
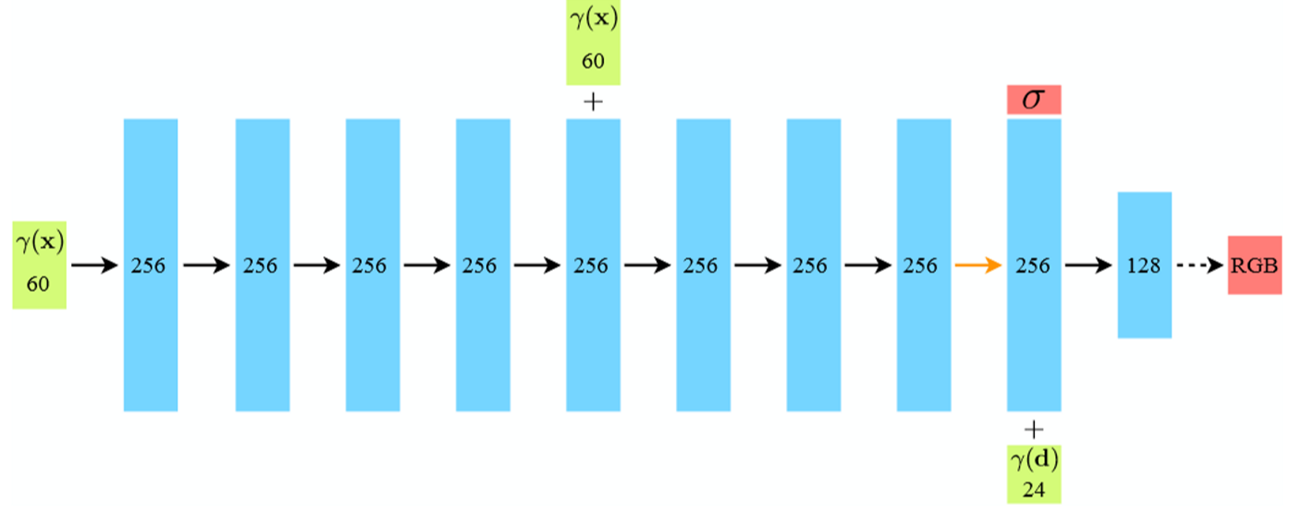
이렇게 계산된 i번째 3D Voxel좌표의 σi , ci 와 δi (=ti+1 좌표와 ti 좌표 사이의 간격)으로 2D Pixel의 RGBA값을 계산합니다.

NeRF논문의 핵심이 되는 수식이고, 이후 파생된 논문에서도 해당 수식을 응용하여 사용합니다. 때문에 좀 더 상세히 설명하겠습니다. 위 수식은 Volume Rendering의 기본 수식을 기반으로 만들어졌습니다. 2D Pixel좌표의 color(C(r))는 3D Voxel좌표 color(ci)와 불투명도(Ti*(1-exp(-𝜎𝑖δi)))에 대한 weighted sum으로 볼 수 있습니다. 불투명도는 2개 부분 Ti와 1-exp(-𝜎𝑖δi)으로 나뉘어집니다.
- Ti는 i번째 Voxel이 보일 확률, 1-exp(-𝜎𝑖δi)는 i번째 Voxel이 surface일 확률입니다.
Ti 수식을 자세히 보면, 0 ~ i-1번째 voxel의 volume density를 사용합니다. 0~i-1번째 voxel이 불투명하다면, Ti는 작아집니다. - 1-exp(-𝜎𝑖δi)는 volume density가 음수를 두번 취하였기 때문에, MLP를 통한 volume density 값이 클수록 i번째 voxel의 color 영향력이 커집니다.
예시를 들겠습니다. i=0이 카메라에서 가장 가까운 3D voxel좌표이고, i가 커질수록 멀리 위치합니다.
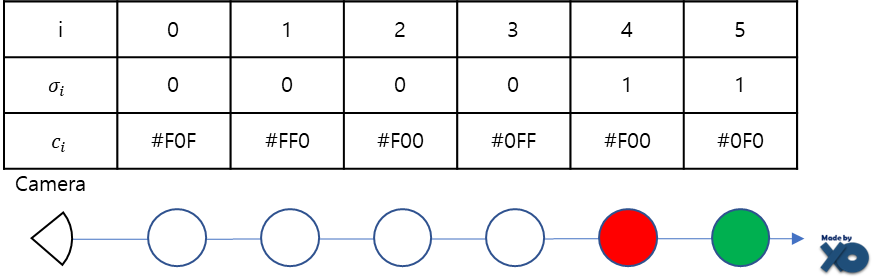
i=3일 때, 𝜎𝑖 는 0이므로, 1-exp(-𝜎𝑖𝛿𝑖) 식은 0이 되면서, c3 은 C(r)에 영향력이 없습니다.
i=4일 때, 𝜎𝑖 는 0보다 크고, Ti는 1이므로, c4 는 C(r)에 많은 영향력을 미칩니다.
i=5일 때, 𝜎𝑖 는 0보다 크고, Ti는 𝜎4에 의해 크기가 줄어듭니다. 이는 4번째 Voxel에 의해 5번째 Voxel이 가려져, c5 가 C(r)에 적은 영향력을 주도록 수식화 되어 있습니다.
이러한 설계를 통해 아래 그림과 같이, 다른 View Direction에서 같은 지점을 바라 볼때, Radience가 달라지면서, 다른 RGB값을 갖게 합니다.

Voxel Sampling
Discrete한 좌표를 입력 값으로 하는 Neural Network를 설계할 경우, 모든 3차원 좌표에 대한 Color값을 계산에는 한계가 있기 때문에, 좌표를 Sampling하는 기법을 사용했습니다.
투명한 영역이나 가려진 영역의 좌표인 경우, Rendering에 큰 영향을 끼치지 않기 때문에, 1차 Sampling 후에, 영향력이 큰 좌표들에 대해 2차 Sampling합니다.
- 1차 Sampling은 Stratified Sampling방식을 사용하였는데, 이는 각 Ray에 대해 중복되지 않도록 균일하게 구간(bin)을 나누고, 각 구간 내에서 랜덤하게 1개의 좌표를 선택하는 방식입니다. tn(n=near) 좌표부터 tf(f=far)까지의 구간을 N개로 균일하게 나누고, i번째 좌표에 대한 U(집합)을 ti로 표현 하였습니다.
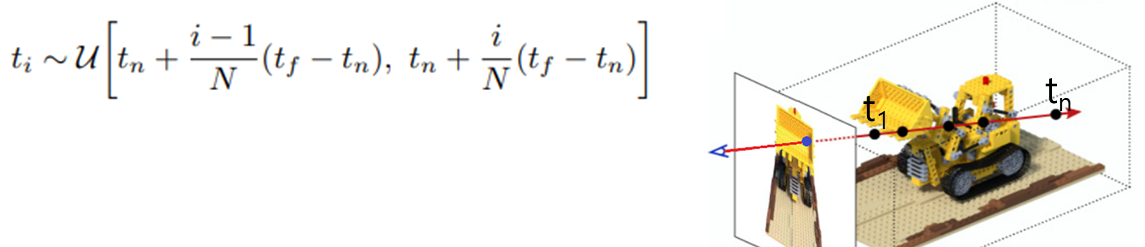
- 2차 Sampling은 Inverse transform sampling을 사용합니다. 1차 Sampling 좌표들에 대해 Color값들을 계산 한 후에, 앞서 설명한 Color을 계산하기 위해 사용한 불투명도인 wi를 사용하여, Ray에 대한 PDF(확률밀도)을 계산 합니다.
PDF를 적분하여 CDF(누적분포)를 계산 한 후, 난수값으로 Sampling을 합니다. 그렇게 되면, Wi가 큰 구간에 대해서, 좀 더 많은 좌표들을 Sampling 할 수 있습니다.
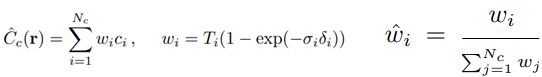
1차 Sampling을 Coarse Sampling, 2차 Sampling을 Fine Sampling이라고 부르고, 1,2차 Sampling을 모두 사용합니다.
논문 기본 수식에서는 Nc를 64개, Nf를 128개 두었습니다
Positional Encoding
네트워크 입력 차원이 총 5개(x,y,z,θ,φ)로 설계 되었습니다.
입력 차원이 다차원일수록 잘 학습되기 때문에, 아래 encodin함수로 입력 차원을 늘여줬습니다.

기본 실험 셋팅으로 좌표(x,y,z)에 대해서는 각각 L을 10, View Direction(θ,φ)에 대해서는 L을 4로 두었다고 합니다.
아래와 같이 성능의 차이가 있었다고 합니다.

Evaluation
Quality
NeRF에서는 아래에 대한 실험을 진행하였습니다.
- Diffuse Synthetic : DeepVoxels Dataset에서는 Lambertian Reflectance(각도와 관계없이 같은 겉보기 밝기)를 갖는 4개의 Object에 대해 512x512이미지를 사용하였고, 각각 Object에 대해 79개를 input 이미지, 1000개를 Test 이미지로 두었습니다.
- Realistic Synthetic : NeRF논문에서는 추가로, non-Lambertian Reflectance를 갖는 8개 Object에 대해 800x800이미지를 사용하였고, 각 Object에 대해 100개를 input이미지, 200개를 Test 이미지로 두었습니다.
- Real Forward-Facing : 정면에서 촬영한 Real Scene 8장면에 대해 1008x756 이미지를 사용하였고, 각 Scene마다 20~62개의 이미지를 사용하여, input이미지로 7/8, Test이미지로 1/8을 사용하였습니다.

각 평가 지표는 다음을 의미합니다. 평가지표에 대한 상세 내용은 여기에 정리해두었습니다. -> 평가 지표 Link
- PSNR(Peak Signal-to-Noise Ratio) : 두 이미지 간의 픽셀 오차가 적을 수록 PSNR값이 높습니다.

- SSIM(Structural Similarity Index Map) : 두 이미지간의 상관계수를 Luminance(휘도), Contrast(대비), structural(구조) 총 3가지 측면에서 평가 -> 픽셀의 평균, 분산으로 평가 값이 높을 수록 유사도가 높습니다.
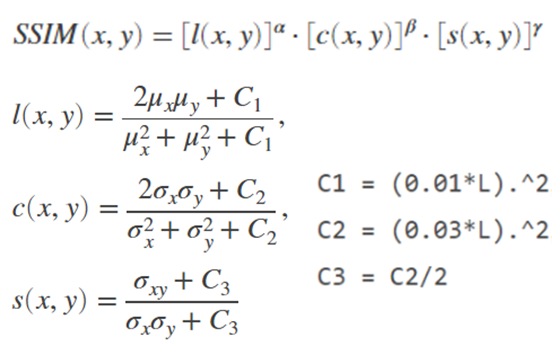
※ PSNR의s, SSIM의 L은 0~1 또는 0~255의 범위를 가집니다.
- LPIPS(Learned Perceptual Image Patch Similarity) : pretrained Alexnet을 활용하여 Image Feature를 추출하고 distance를 계산 값이 작을 수록 유사도가 높습니다.
Speed
Train에 100-300k iteration이 필요하였고, V100 GPU에서 1~2day가 소요되었다고 합니다.
Closing..
Neural Radiance Field에 관한 후속 논문이 끊임없이 발표되고 있습니다. Train, Inference 속도를 개선 시키는 연구, Static이 아닌 dynamic한 물체 Rendering에 대한 연구, 입력 이미지를 최소화 시키는 연구, Radiance가 아닌 Depth를 추정하는 연구, 조명을 변화시키는 연구 등 많은 연구가 진행되고 있습니다.
이후 본 블로그에서는 NeRF 후속 여러 논문들에 대해 정리 해보고자 합니다.
NeRF개선방향 및 연구동향에 대해서 추가로 정리 해두었습니다. NeRF 개선방향 및 연구동향 글 참조 바랍니다.
'NeRF' 카테고리의 다른 글
| [논문 리뷰] MVSNeRF (ICCV2021) : 적은 입력 + 학습 속도 개선 논문 (0) | 2022.10.27 |
|---|---|
| [논문 리뷰] Plenoxels (CVPR 2022) : 학습 속도 개선 논문 (0) | 2022.10.20 |
| [논문 리뷰] Point-NeRF (CVPR 2022) : 학습 속도 개선 논문 (1) | 2022.10.13 |
| [논문 리뷰] PlenOctrees for NeRF (ICCV 2021) : 랜더링 속도 개선 논문 (4) | 2022.10.12 |
| [논문 리뷰] PixelNeRF (CVPR 2021) : 입력 이미지 갯수를 개선한 NeRF 연구 (0) | 2022.10.11 |




댓글