NICER-SLAM: Neural Implicit Scene Encoding for RGB SLAM, Zihan Zhu, 3DV 2024
NeRF를 활용한 dense RGB SLAM입니다. 논문에서는 tracking과 mapping을 end-to-end optimization하는 one of the first dense RGB SLAM이라고 표현하는데, 최초라는 타이틀을 쓰려다가 2주 앞서 작성된 논문(Related Work 참조) 때문인 것 같습니다.
21-22년에는 NeRF를 사용한 RGB-D SLAM이 대다수였지만, 본 논문이 RGB SLAM 시작을 알리는 것 처럼 보입니다.

Input에 Depth값를 빼고도 더 좋은 퀄리티를 보입니다. NICER-SLAM에서는 Camera pose estimation과 Map representation을 동시에 Optimization하였습니다. Tracking, Mapping, Novel View Synthesis을 하였고, RGB-D SLAM에 비해서도 높은 성능을 보였습니다.
NICER-SLAM의 핵심은 3가지입니다.
- 3D reconstruction과 high-fidelity rendering을 위해 SDF(Signed Distance Fuctions)를 모델링하여 coarse-to-fine hierarchical feature grid를 만들었습니다.
- monocular geometric predictor와 optical flow 알고리즘으로 Loss가 설계되었습니다. geometry consisteny을 위해 warping loss가 사용됩니다.
- indoor scene에 sequential input을 최적화시키기 위해, SDF를 density로 변환하는 adaptive transformation을 제안하였습니다.
하나씩 풀어서 설명해보겠습니다.
Basic Terms
논문을 이해하기 위해 알아야할 기초 용어들입니다.
SDF(Signed Distance Fields) : Geometry관점에서 주어진 모델의 내부는 +, 외부는 - , Edge에 근점 할 수록 0이되는 데이터 포맷입니다. (출처 : link)

Voxel Grid : 단순히 voxel로 구성된 Grid 자료구조입니다. NeRF분야에서는 속도를 향상시키기 위해 사용되고 있습니다. Sparse한 Grid형태에서 각 grid를 기준으로 feature vector로 사용하거나 grid가 만나는 접점을 기준으로 feature vector로 사용합니다. (왼쪽 그림 출처 SNeRG, 오른쪽 그림 출처 Plenoxel)
Optical Flow : 두개 프레임에서 각 pixel의 움직임을 추정하는 알고리즘입니다. Optical flow의 결과는 픽셀별 shift vector값입니다. (출처 : link )

Related Work
이 논문의 Related Work가 최근 연구동향을 보기에 잘 정리되어 있어서 Related Work부분은 단순 번역하였습니다.
Related Work부분은 스킵하고 Overview부터 보셔도 전체 알고리즘 이해하는데 문제가 되지 않습니다.
Dense Visual SLAM
- Sparse Visual SLAM은 정확한 카메라 포즈를 추정하고, map representation을 sparse한 point cloud로 합니다.
- Dense Visual SLAME은 dense map을 만드는데 초점이 맞춰져 있습니다.
일반적으로 Map Representation은 View-centric과 World-centric로 나누어져있습니다.
- View-centric은 keyframes에 대한 depth map으로 3D geometry을 표현합니다. DTAM은 View-centric입니다.
- World-centric은 단일 world좌표계 내에서 한개의 full scene의 3D geometry를 고정하고, voxel grid안에서 surfel(=surface 요소단위) 또는 occupancies/TSDF값으로 표현합니다.
NICER-SLAM에서는 World-centric Map Representation을 사용하였고, surface를 explicit representation하지 않는 대신에 여러 해상도의 voxel grids안에서 latent code를 저장하였습니다. 이를 통해 저해상도에서 high-quality geometry를 reconstruction할 수 있게 하고 unobserved 영역에 있음직한 gemotery값 추정 할 수 있게 하였습니다.
Neural Implicit-based SLAM
Nueral implicit representation은 object-level reconstruction, scene completion, novel view synthesis를 포함하여 많은 다양한 tasks들에서 높은 성능을 보였습니다.
아래 6개 논문에서는 neural radiance field와 camera pose를 같이 optimization하였습니다. 문제는 작은 물체 나 작은 카메라 움직임만 지원하였습니다.
- iNeRF: Inverting neural radiance fields for pose estimation. (IROS 2021)
- Barf: Bundleadjusting neural radiance fields (ICCV 2023)
- Nerf–: Neural radiance fields without known camera parameters (arXiv 2021)
- Gaussian activated neural radiance fields for high fidelity reconstruction and pose estimation (ECCV 2022)
- Nope-nerf: Optimising neural radiance field with no pose prior (ECCV 2022)
- Volumetric bundle adjustment for online photorealistic scene capture (CVPR 2022)
아래 2개 논문은 이러한 제약사항을 넘어, ORB-SLAM 과 DROID-SLAM과 같은 최신 SLAM알고리즘에 의존하여, 정확한 카메라 포즈를 얻고 3D dense reconstruction하고 novel view synthesis를 하였습니다.
- Orbeez-slam: A realtime monocular visual slam with orb features and nerfrealized mapping (arXiv 2022)
- Nerfslam: Real-time dense monocular slam with neural radiance fields (arXiv 2022)
아래 8개 논문은 NeRF과 SLAM pipeline을 사용하였습니다. 문제점은 indoor scene만 가능하고 outdoor scene이 불가능하였고, RGB-D입력만 지원되고 RGB지원은 안됬습니다.
- imap: Implicit mapping and positioning in real-time (ICCV 2021)
- Nice-slam: Neural implicit scalable encoding for slam (CVPR 2022)
- Eslam: Efficient dense slam system based on hybrid representation of signed distance fields (arXiv 2022)
- Meslam: Memory efficient slam based on neural fields (SMC 2022)
- Vox-fusion: Dense tracking and mapping with voxel-based neural implicit representation (ISMAR 2022)
- Towards open world nerfbased slam (arXiv 2023)
- isdf: Real-time neural signed distance fields for robot perception (RSS 2022)
- idf-slam: End-to-end rgb-d slam with neural implicit mapping and deep feature tracking (arXiv 2022)
NICER-SLAM에서는 RGB입력만으로 고퀄리티의 3D reconstruction이 가능하였고 동시에 정확한 camera pose 추정이 가능하였습니다.
NICER-SLAM보다 2주 앞서 출간된 유사 연구인 아래 논문은 정확한 camera tracking(=camera pose추정)에 포커싱하였지만, NICER-SLAM에서는 고퀄리티의 3D reconstruction과 novel view synthesis에 포커싱하였습니다.
- Dense rgb slam with neural implicit maps (ICLR 2023, Jan 24)
논문에서 RGB-D SLAM에 비해 RGB SLAM이 어려운 점에 대해 이렇게 소개하고 있습니다.
- Depth값이 ambiguity(모호)하다면, Feature가 유사한 color들로 매칭이 됩니다. Mapping과 Tracking이 어렵습니다.
- ambiguity때문에 surface estimation이 less localized되면서, data structure updates가 복잡하게 되고 sampling이 오래걸립니다.
- Optimization에 제약이 줄고 좀더 복잡해지면서, Optimization convergence하는데 시간이 더 소요됩니다.
이를 어떻게 해결하였는지 하나씩 보겠습니다.
Overview

설명을 위해 순서를 numbering해보았습니다.
1. Video에서 RGB Iamge들을 입력받아, RGB Input, Monocular Normal Estimator, Depth Estimator를 GT로 두고, RGB이미지, Normal map, Depth map을 생성하여 각각 (RGB, Normal, Depth) Loss를 구합니다.
2. 일정규칙에 따라 frame(keyframe)을 Selection하게 되고, 그 keyframe의 GT값과 예측한 값간의 Warping Loss, Optical Flow Loss를 구하게 됩니다. Regularization을 위한 Eikonal Loss도 사용됩니다.
3. Inference를 위한 네트워크는 Hierarchical Feature Grid 기반으로 Geometry Grids, Color Grids가 모델링 됩니다. 입력 이미지 각 pixel에 대해 ray를 marching하고, 샘플링되는 ray위의 point들은 Grid를 통해 Encoding됩니다. Encoding된 voxel point들은 MLP를 통과하여 1번에서 소개한 RGB 이미지, Normal map, Depth map을 만들게 됩니다.
단어 하나하나가 큰 의미를 갖고 있기 때문에, 위의 내용이 지금은 이해 안되실 겁니다. 어떤 구조인지만 느낌적으로 파악하고 알고리즘 부분에서 세부적으로 이해 하시길 바랍니다.
Algorithm
Mapping and Tracking
NeRF기반한 Scene Representation을 구성하면서, mapping과 tracking이 동시에 진행됩니다. mapping은 5frame마다 tracking은 매 프레임마다 진행합니다.
tracking과정에서는
- scene representation이 고정된 상태에서
- 현재 프레임에서 Mt개의 pixel을 샘플링하고
- RGB Loss를 사용해서 100번의 Iteration으로
- camera 포즈(rotation 과 translation)를 계산합니다.
mapping과정에서는
- video입력 frame 중 loss를 계산할 keyframe 선택하는 과정이 추가됩니다. 10개 frame마다 keyframe list에 추가하고, keyframe list에서 5개를 랜덤으로 선택하고, 최근 20개 keyframe에서 10개를 랜덤으로 선택하고, 현재 frame 1개까지 선택하여 총 16개의 frame을 Selection합니다.
- 선택된 keyframes에서 M개의 pixels, M개의 rays를 균등하게 샘플링합니다.
- 아래 Loss를 3step에 걸쳐 optimization을 통해 학습합니다.
전체 Loss는 다음과 같습니다. 3step Optimization에 대해서는 아래 Loss를 설명 한 후에 뒤 쪽에서 언급드리겠습니다.

RGB Loss, Warp Loss 에 대해서 많은 페이지를 할애하고 있고, 그 뒤의 flow, depth, normal, eikonal Loss에 대해서는 다른 연구들을 그대로 들고와서 언급하고 있어서 몇 줄 안됩니다.
RGB Loss는 간단히 Color의 차이를 계산하는 아래의 형태로 표기되어 있습니다.

하지만 이 Color를 계산하기 위해 많은 개념이 들어갑니다. Hierarchical Neural Implicit Representations과 Volume Rendering에 대해서 소개하겠습니다.
Hierarchical Neural Implicit Representations
전체 알고리즘이 복잡해서 최대한 그림으로 표현해봤습니다. 하단 XO가 붙은 이미지들은 논문에 없는 이미지이며, 제 견해가 들어가 있으니 틀릴 수 있습니다. 이야기해주시면 정정하도록 하겠습니다.
Coarse-level Geometric Representation
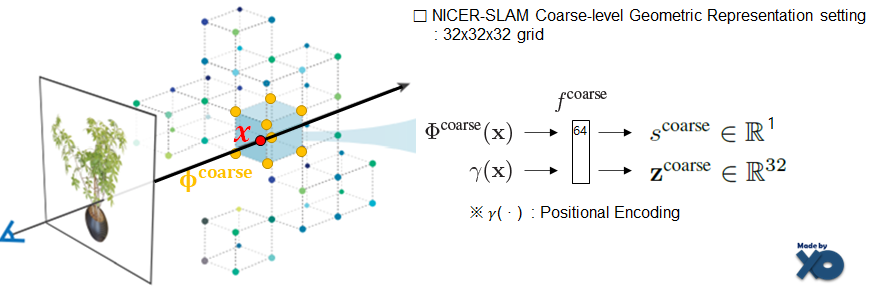
Coarse한 Geometry를 모델링하는 단계입니다. Geometric관점에서 정확한 SDF값이 아닌 Scene layout(e.g. walls, floors)을 모델링 하기 위한 네트워크를 설계하였습니다. 'Ray위의 voxel x 주변 8개 점의 feature값'과 'x에 대한 Positional Encoding'을 입력으로하여 f^coarse 네트워크에 넣으면 SDF값인 s^coarse값과 geometric feature값인 z^coarse값을 출력합니다. 32x32x32로 해상도가 고정되어 있습니다.
Fine-level Geometric Representation

fine(디테일)하게 geometry를 모델링하는 단계입니다. Instant NeRF에서 언급된 multi-resolution dense featrue grid 방법을 사용했습니다. 이 파트와 다음 파트인 Color Representation을 이해 하기 위해서 Instant NeRF 이전글 의 Algorithm 파트를 먼저 읽고 오시길 바랍니다(A4 2장 분량이 될 것 같습니다.). grid가 어떻게 구성되는지, L(=Level)이 어떻게 구성되는지에 대해서는 그림 안에 설명해두었습니다. 입력값인 { Φ^fine(x) } 부분은 Level별로 Ray위의 Voxel x주변 8개점에 대한 집합 값입니다. f^fine 네트워크를 통해 fine한 SDF값인 △s와 geometric feature값인 z^fine값을 얻습니다.
coarse network에서 s&coarse값과 fine network에서 △s의 합으로 최종적인 SDF값을 구합니다.

△s으로 표기한 이유가 coarse를 통해 큰 골격을 잡은 후에 fine을 통해 변화량을 세부적으로 계산한다는 의미이지 않을까 생각해봅니다.
Color Representation

Color값을 Prediction 하는 단계입니다. 위 그림을 통해 L(Level), F(Feature Size)가 어떻게 바뀌었는지 확인바랍니다. Instant NeRF와 입력값이 다릅니다. geometry network에서 출력된 feature vector와 SDF를 통해 계산된 normal값이 입력으로 사용됩니다. f^color 네트워크를 통해 color값 c헷(소문자)이 계산됩니다.
Volume Rendering

NeRF의 기본 Volume Rendering과 유사하게, ray위의 voxel에 대한 color값과 density를 구한 후에 Volume Rendering 공식으로 Radiance(C헷) 값을 계산합니다. voxel의 density와 color값을 계산 하는 방식은 완전히 다릅니다. denstiy를 구할 때, σβ(s)는 VolSDF(2021년) 연구의 SDF값을 volume density로 변환하는 수식을 갖고 와서 사용되었습니다.
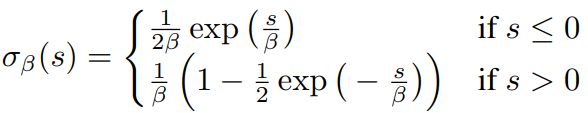
학습시에, β는 아래 수식으로 조절된다고 합니다. c0 = 0.01208 , c1 = 0.00000626471, c2 = 0.0023 입니다.

기존 VolSDF연구에서는 Global하게 β값을 사용하였지만, NICER-SLAM에서는 sequencial input값이 주어지므로 이에 맞게 Local β을 사용하였다고 합니다. voxel마다 point sample의 갯수를 카운팅(Tp)하면서, β값을 조정합니다. β값이 줄어들면서 object surface일 확률이 높아진다고 합니다. β를 조절하는 부분을 논문에서는 adaptive transformation이라고 표현하고 논문 introduction에서 key idea로 언급하고 있습니다.
Loss
다시 전체 Loss를 보겠습니다.
RGB Rendering Loss는 알고리즘 초반부에 언급했었습니다.
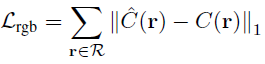
RGB Warping Loss는 아래 수식입니다.

먼저 아래 수식을 통해 Depth에 대한 depth map을 생성합니다. ti는 ray위의 sample된voxel의 깊이입니다. Ti는 Transmittance값 α는 alpha값입니다. 좀 더 부가 설명은 위의 Volume Rendering 그림 내 수식 참고바랍니다.
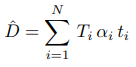
현재 frame을 m이라고 할 때, 그 안의 하나의 pixel을 rm으로 둡니다. depth map을 생성 한 후에 3D로 unproject하고, intrinsic, extrinsic parameter를 사용해서 만든 다른 프레임 n 내에서, rm과 대응되는 pixel을 rn이라고 둡니다. C(rm)은 현재 프레임의 한개 pixel의 color값이고, C(r m->n)은 대응되는 n의 color값입니다. 이 색상값으로 Loss를 구하게 됩니다.
Optical Flow Loss는 GMFlow라는 알고리즘을 사용합니다. m 프레임에서 n 프레임으로 바뀔 때 rm이라는 pixel과 관련성이 있는 pixel들을 rn이라고 둡니다. 그리고 rm과 rn의 pixel변화량(?) 과, Optimical Flow값(좌표 변화량 벡터)간의 차이로 Loss를 계산합니다.

Monocular Depth Loss는 predicted depth D(왼쪽 Term)과 omnidata라는 최신 monocular depth predictor의 결과 depth D(오른쪽 Term)간의 차이로 Loss를 구합니다. least-squares criterion 이라는 알고리즘으로 두 Depth간의 scale(w)과 translation(q)을 계산 한 후에 Loss를 계산합니다.

Monocular Normal Loss는 predicted normal N(왼쪽 Term)과 omnidata predictor의 결과 normal N(오른쪽 Term)의 차이로 Loss를 구합니다.

Eikonal Loss는 SDF값인 s로 regularize합니다. x는 균일하게 샘플링된 surface 주변 point set입니다. SDF 최신 연구들이 많이 사용하는 Regularization Loss입니다.

Training Process

mapping단계에서 위에서 3가지 Step으로 optimization한다고 언급하였습니다. 논문에 소개된 각 Step별 update되는 Parameters들을 도식화 해 봤습니다.
1. coarse geometric과 관련된 부분이 먼저 업데이트 됩니다. RGB관련 부분도 업데이트 됩니다. (전체 Interation중 초반 25%까지 빨간 색 부분만 업데이트 합니다.)
2. fine geometric과 관련된 분이 업데이트 됩니다. (전체 iteration 중 75%까지 빨간, 파란 영역이 업데이트 됩니다.)
3. rgb voxel grid의 feature vector부분이 업데이트 되고, pose쪽도 업데이트 됩니다.
tracking단계에서 16개 fraem중에 현재 카메라와 가장 멀리 있는 8개의 frame에서는 camera pose를 freeze하고 가까운 8개 frame에서는 앞으로 볼 Loss로 만들게되는 scene representation으로 camera pose를 optimize합니다.
mapping과 tracking단계에서 모든 픽셀을 계산하지 않고, mapping에서는 16개 keyframe을 선택 후에 8096개 픽셀, tracking단계에서는 1024pixel을 각각 sampling합니다. 그리고 100 iteration 학습합니다.
이러한 Tracking과 Mapping구조로 Dense RGB SLAM이 가능하였습니다. 다음으로는 실험 결과에 대해 다루어보겠습니다.
Experiments
속도 : A100 GPU에서 mapping은 평균 496ms, tracking은 147ms라고 합니다. 실시간 SLAM은 불가능해보입니다.
데이터셋 : RGB-D 형태인 Replica 합성 데이터셋과 640x480의 real-world 7개 scene데이터셋을 사용했습니다.
비교 논문
- NICE-SLAM, Vox-Fusion : neural implicit 기반 RGB-D SLAM
- COLMAP : MVS함수 기반 RGB Structure from Motion(SfM)
- DROID-SLAM : dense monocular SLAM
- DROID-SLAM* : bundle adjustment 와 loop closure를 수행하지 않는 DROID-SLAM
평가 방법
- Tracking 평가 : evo를 사용해서 estimated trajectory와 GT trajectory를 align함. 그리고 ATE RMSE camera tracking의 Accuracy를 평가
- Scene Geometry평가 : ICP tool을 사용해서 GT mesh와 align한 후 Accuracy, Completion, Completion Ratio, Normal Consistency를 측정
- Scene Synthesis 평가 : PSNR / SSIM / LPIPS 참조
Quality
- 아래 테이블 왼쪽은 3D Reconstruction(scene geometry)를 평가한 표이고, 오른쪽은 Novel View Synthesis를 평가한 표입니다. Replica 데이터셋으로 평가하였습니다.
- NICER-SLAM이 RGB 입력 기반 연구에서는 3D Reconstruction 최고의 성능을 보입니다. RGB-D 입력 기반 연구보다는 성능이 낮지만 비슷한 수준입니다.
- NICER-SLAM이 Novel View Synthesis에서는 최고 성능을 보입니다.

- 3D Reconstruction 결과, Novel View Synthesis 결과입니다.


- 아래 테이블은 tracking결과를 평가하였습니다. 왼쪽은 Replica 데이터셋, 오른쪽은 7scene 평가입니다.
- NICER-SLAM이 tracking성능은 좋지 않습니다. DROID-SLAM이 가장 좋은 성능을 보입니다.

- 아래 테이블은 Ablation Study항목으로써, 알고리즘 각 모듈의 설계에 따라 전체 성능의 영향도를 보여주고 있습니다.
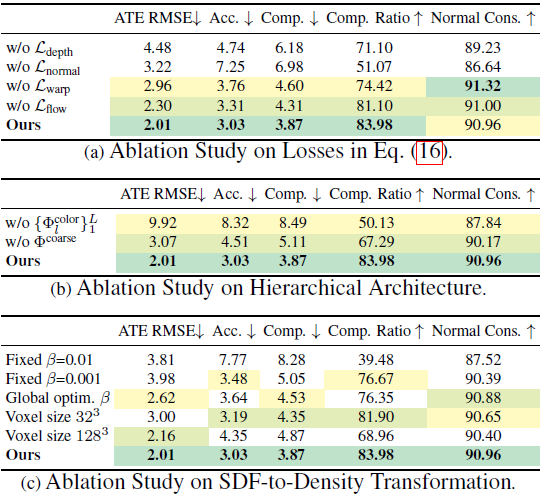
- Ablation Study중에 하나로 언급된 SDF vs Occupancy입니다. 최근 implicit-base dense SLAM은 scene geometry를 나타내기 위해 occupancy를 사용한다고 합니다. NICER-SLAME에서는 대신에 SDF를 사용했더니 더 좋은 성능을 보였다고 합니다.

- 현재 pipeline으로 loop closure가 안된다고 합니다. limitations에 언급되어 있습니다.
Closing..
내용을 다 담을려니 글이 좀 지루해 졌을 것 같네요.. 가능한 다 담으려 했지만 못 담은 것도 있습니다. Optical flow, monocular predictor와 같이 기존에 만들어진 다양한 연구를 활용하여 Loss로 사용하는 것이 눈에 띄였습니다. Neural Implicit Representation과 Volume Rendering으로 설계 된 RGB Loss를 보면 NeRF 논문인 것 같은데, SLAM System이 목표다 보니 논문명에서 NeRF라는 키워드가 완전히 빠진 것 같아 보이네요. 상당히 많은 Process를 거치게 되는데, 이게 A100 GPU에서 mapping은 평균 496ms, tracking은 147ms으로 구동된다는게 신기하네요. 본 블로그 글을 작성시점에서는 코드가 공개되지 않았는데, 같은 저자인 NICE-SLAM 코드가 공개 된 것 보면 곧 업로드 되지 않을까 싶습니다.
그림 출처
https://nvlabs.github.io/instant-ngp/assets/mueller2022instant.pdf
'NeRF' 카테고리의 다른 글
| [논문 리뷰] NeuS (NeurIPS2021) : 3D Surface Reconstruction - SDF연구 (0) | 2023.03.07 |
|---|---|
| [API 리뷰] NeRF Studio : NeRF 통합 Framework (10) | 2023.02.27 |
| [논문 리뷰] NeRF-Art (arXiv 2022) : Text 입력 Style 변형 연구 (0) | 2023.02.11 |
| [논문 리뷰] RawNeRF (CVPR 2022) : HDR, Denoising, Defocus연구 (0) | 2023.01.29 |
| [논문 리뷰] iMap NeRF (ICCV 2021) : SLAM에 NeRF를 접목 (1) | 2023.01.06 |




댓글