논문명 : Instant Neural Graphics Primitives with a Multiresolution Hash Encoding, THOMAS MÜLLER
이번 논문은 NeRF분야에 한정되지 않고, 2D 또는 3D 좌표값을 입력으로 받아 MLP로 Prediction하는 다양한 분야들에서 사용 될 수 있는 Feature Encoding 방법에 대해 다룬 논문입니다. 핵심은 단순하나, 모델 설계와 Parameter를 선정하게 된 근거, 다양한 분야에서 어떻게 적용하고, 기존 연구 대비 얼마나 개선되었는지에 대해 자세히 설명되어 있습니다. 적용한 분야는 4가지 입니다.
- Gigapixel Image : 10^9개의 2D Pixel로 이루어진 초고해상도 이미지를 Rendering하는 분야입니다.
- Signed Distance Function (SDF) : 3D공간 내 각 좌표들에 대해, 주어진 Object의 Surface와의 거리 값을 추정하고, Object의 내/외부인지를 판단하여 Shape를 Reconstruction하는 분야입니다.
- Neural Radiance Caching (NRC) : 주어진 Scene에 대해 가속된 global illumination computation(전체 조명 연산)을 위한 ray-tracing기반의 연산입니다. 모든 조명에 대해 voxel들이 계산하여 랜더링 할 수 없기 때문에, glossy한 surface의 radiance를 sparse하게 sampling하고, caching하고, interpolation하는 분야입니다.
- Neural Radiance Field (NeRF) : 시점이 알려진 2D 이미지들로부터 학습하여, 다른 시점에서 관측될 2D 이미지를 추정하여 Rendering하는 분야입니다.
저에겐 Gigapixel Image, NRC 분야가 생소했는데요. 본 논문이 NVIDIA 연구팀에서 써진 것을 보면, 고해상도에 다양한 광원을 가지는 Application들에 대해서 Nvidia GPU에서 빠른 속도로 랜더링하기 위해 해당 분야를 다뤘을 것으로 보입니다.
기본 알고리즘을 소개하고, 설계 근거, 성능 평가 순으로 소개하겠습니다.
Algorithm
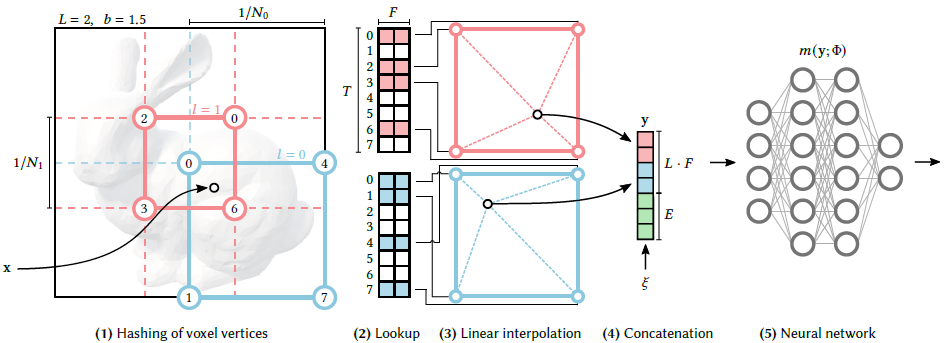
주어진 2D/3D Scene의 모든 좌표 각각에 대해 MLP를 계산하여 MLP출력(Radiance 또는 Density)값을 구하면 연산량이 너무 크고 학습시 수렴 속도가 느립니다. 이를 줄이기 위해, HashMap, Linear Interpolation으로 좌표를 Encoding하는 방식을 제안하였습니다.
(1) 주어진 x좌표에 대해, Grid Level별로 주변 4개의 좌표를 선택합니다.
(2) 선택된 좌표들로 HashKey값을 만들어, HashTable에서 Value들을 읽습니다.
(3) x좌표와 주변 4개 좌표의 거리를 기반으로 4개의 Value들을 Weighted Sum하여, 1개의 Feature Vector로 만듧니다.
(4) 각 Grid Level별 Feature Vector들과 Auxiliary값(ex, view direction)들을 Concat하여 최종 Feature Vector로 만듧니다.
(5) MLP를 통과합니다.
(1) 주어진 2D/3D Scene에 대해 Level이 정의됩니다. 위 자료에서는 2D Scene에서 Level(=L)이 2개인 경우를 도식화 하였습니다. 각 Level마다 다른 Resolution을 갖게 되는데, 여기서 말하는 Resolution은 N값 입니다. 위 자료에서 Level0인 파란색의 Resolution은 2, Level1인 빨간색의 Resolution은 3입니다. 이 resolution 크기는 최소resolution을 기준으로 b만큼 곱해서 다음 level의 Resolution이 정해지게 되는데, 위 자료에서는 최소 Resolution(=Nmin)이 2이고, 최대 Resolution(=Nmax)는 3이고 b가 1.5입니다. 실제 논문에 언급된 수식은 다음과 같습니다.
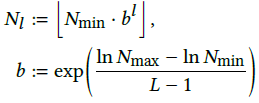
소문자 엘(=l)은 level을 나타내어, 0번째 level에서는 Nmin, 1번째 level에서는 Nmin*b^1 계산 후 내림한 값입니다. Nl은 l번째 level의 Resolution을 나타냅니다.
(2) Scene내 모든 각각의 좌표는 아래 식에 의해, MLP값이 계산될 주변 좌표값을 얻게 됩니다.

2D Scene이면 4개의 좌표를, 3D Scene이면 8개의 좌표를 얻게 됩니다. 위 예시에서 빨간색 level의 resolution(=N1)는 3이었는데, x가 3만큼 Scaled된 값이 계산 되어지게 됩니다. 이렇게 변형된 좌표들은 아래의 spatial hash function(2003) 수식에 의해 Hash Table을 위한 Hash key값으로 변형됩니다. Hash Table은 Level마다 1개씩 정의 됩니다.
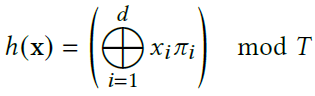
d는 dimension을 의미하고, π는 dimension마다 임의로 정해둔 실수값(𝜋1 := 1, 𝜋2 = 2 654 435 761, 𝜋3 = 805 459 861) , 십자가 표시는 비트별 XOR연산, T는 hash table의 size를 의미합니다. Hash Key Collision을 최소화한 공식이라 생각됩니다. (Collision은 발생하며, 이를 다루는 방법에 대해서 아래에서 다룹니다.) 이를 통해 각 좌표의 Hash Key값이 계산되어집니다. 그리고 해당 Hash Key로 접근한 Hash Table에 대한 Value값은 F개의 Feature Dimension으로 구성되어 있습니다. 위의 예시 이미지에서 T는 7이고 F는 2입니다.
위에 각 값은 설명을 위한 값이며 실제로 사용되는 값은 아래와 같습니다.

스크롤이 너무 내려와서 다시 같은 이미지 첨부하겠습니다...
(3,4,5) MLP의 입력으로 들어가는 Feature Vector로 변환하는 과정입니다. 기준 좌표 x와의 떨어진 거리를 Weight로 하여 각 Hash Table의 Value인 Feature Vector(단계(2)에서 사각형 )을 Summation하여 Feature Vector(단계 (4)에서 사각형)를 구합니다. 각 Level마다 계산한 Feature Vector와 추가 auxiliary(보조) 값들(예를 들면, view direction)을 Concatenation하여 MLP의 Feature Vector로 만듧니다. 그리고 MLP를 통과합니다.
학습시에는 MLP의 Weight가 업데이트가 되며, 추가로 Hash Table의 Value가 업데이트 하게 됩니다.
다음으로는 위와 같이 설계하게 된 근거를 하나씩 언급해보겠습니다.
Encoding
위의 연구와 기존 Encoding기법을 비교 해보겠습니다.
Frequency Encoding은 최초 NeRF의 Positional Encdoing처럼 입력 Feature의 크기를 늘이는 방법입니다. (최초 NeRF 이전글 참조)
Parametric Encoding은 grid, tree 와 같은 보조 자료구조를 추가적인 trainable parameter로 사용하는 방법입니다. (Plenoxels 이전글 참조). Parameter 갯수가 많아서 메모리 크기는 커지고, 개별 Parameter 업데이트하는 횟수가 적어지지만, 연산량과 메모리 Access횟수는 증가하지 않습니다. 대신 MLP의 크기가 작아짐으로써, 수렴속도가 빠르고, Approximation quality 손실도 없습니다.
Sparse Parametric Encoding은 말그대로 적은 갯수의 Parameter로 Parameter Encoding하는 방법입니다. Dense grid에서는 MLP weight보다 grid의 trainable feature의 메모리가 더 많이 소요됩니다.
각각의 Encoding방법을 적용하였을 때 결과를 보여줍니다.
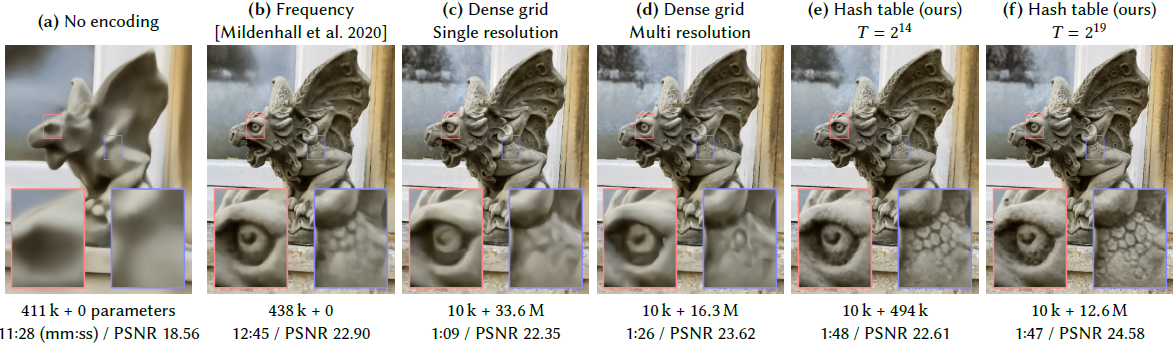
(a) Encoding이 없을 경우입니다. Smooth하게 Rendering됩니다.
(b) Positional Encoding을 사용 할 경우 (a)보다 좀 더 정확합니다.
(c) 128^3 grid에서 16개 feature를 사용할 경우 경우 33.6M이 사용됩니다. 메모리가 더 많이 사용되지만, 수렴속도가 빨라집니다.
(d) 16^3에서 173^3으로 해상도를 올리면서 각 2개 feature를 사용하는 multi-resolution의 경우, 메모리를 덜 사용하면서 좀 더 좋은 성능을 보입니다.
piror단계에서 surface를 알려주는 Octree(Octree 이전글 참조), sparse grid와 같은 데이터 구조는 training하면서 unused faetrue를 발견할 수 있었습니다. NSVF에서는 점진적으로 feature grid의 영역을 정제하는 multi stage, coarse to fine 전략을 사용하였었습니다. 이 방법들은 효과적이나 sparse data structure가 주기적으로 업데이트 되어짐으로써, 학습 과정이 복잡해집니다. 이에 반해 본 연구는 training동안 점진적으로 pruning하지 않고, scene의 geometry의 선행 정보를 사용하지 않습니다.
(e,f) 본 연구에 해당되는 방법론 입니다. 다른 해상도로 index된 multiple hash table을 사용하였습니다. 위에 언급드렸듯이 interpolated된 output이 concat되어 MLP의 input이 됩니다. dense grid encoding와 퀄리티가 비슷하면서, 20배 메모리가 적게 사용하게 됩니다. 이전의 3D reconstruction을 위한 spatial hashing과 다르게 hash collision을 explicitly하게 다루지 않았습니다. 대신에 hash collision이 disambiguate되도록 학습하는 MLP에 의존하였습니다.(<-의미해석 뒤에서 다시 언급) 이는 control flow divergence를 피하면서 구현 복잡도를 줄임으로써 성능을 향상시킬 수 있었습니다.
data간의 독립성을 가진 hash table의 predictable memory layout으로 performance 향상을 만들었습니다. Tree와 같은 데이터 구조에서 caching이 어려웠지만, 본 논문의 hash table은 cache size와 같은 low-level architectural detail을 fine-tune할 수 있었습니다.
Encoding Hyperparameter
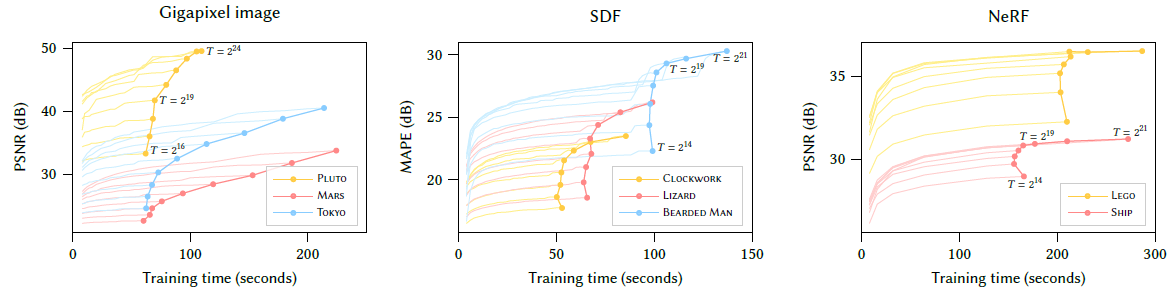
T(hash table size)를 크게하면 Quality가 높아지고 H/W performance는 줄어듭니다.
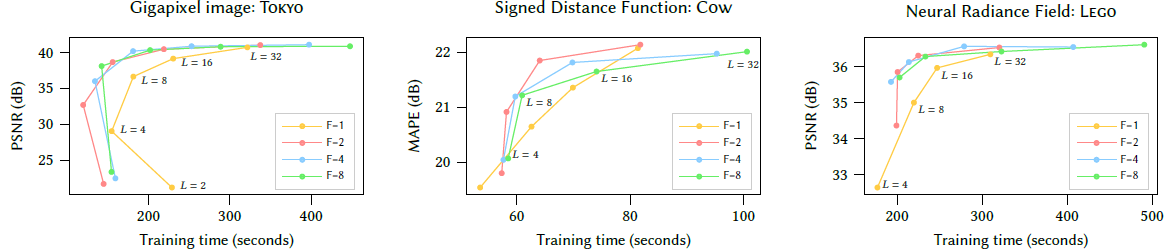
L (number of levels), F(number of feature dimension)도 Quality와 H/W performance의 Trade Off를 가졌으며, 최적의 값으로 선정하였습니다. (T=2^14 ~ 2^24, F=2, L=16)
Hash Collusion
Hash collision이 disambiguate되도록 학습하는 MLP에 의존하였다고 표현되어 있어서 무슨말인지 와닫지 않는데... 좀더 설명하자면 다음과 같습니다.
1) 가까이 있는 좌표간에는 collision이 발생하지 않습니다. 전체 공간에 걸쳐 랜덤하게 collision이 발생하고, 통계적으로 같은 level에서 동시에 collision이 발생될 개연성(확률)이 낮습니다.
2) 학습단계에서 collision이 발생 할 때 중요한 point들은 gradient기여량이 많아지면서 collision발생한 경우들의 평균값이 되어 버립니다. surface영역에 대한 entry는 많은 변화량을 만들고, empty영역에 있는 entry는 적은 weight를 가지게 됩니다,
추가로, coarse level의 경우 Hash Table 크기보다 적을 때는 1:1 mapping이 되면서 충돌이 발생하지 않습니다.
Online Adaptivity
training동안 input x의 distribution이 변하여 small region에만 집중하게 된다면, fine grid level(높은 해상도)에서도 적은 collision이 발생하고 좀더 accurate한 함수가 학습되어지게 됩니다.
d-Linear Interpolation
논문에서 사용되는 기본 수식입니다. θ는 encoding parameter, x는 좌표, Φ는 weight를 나타냅니다.
enc(x;θ) : encoding parameter가 주어졌을 때, x를 입력으로 Encoding
m(enc(x;θ),Φ) : weight가 주어졌을 때, enc(x;θ)를 입력으로 MLP
enc(x;θ)가 linear interpolation하여, continuous하기 있기 떄문에, MLP도 continous합니다. 이를 통해 고차원에서 smoothness한 효과를 가질 수 있습니다.
이제 논문에서 제안하는 방법으로 4가지 분야에 적용한 결과를 보겠습니다.
Gigapixel Image Approximation

ACORN(Adaptive Coordinate Networks)(2021) 최신 연구에 본 논문이 제안한 Multiresolution Hash Encoding방법론을 적용하여 20,000 x 23,466 해상도의 RGB이미지를 Approximation한 결과입니다. Table Size가 커질수록 Quality가 향상되는 것을 볼 수 있습니다. T=2^12, 2^17, 2^22 일때 학습가능한 parameter는 각각 117K, 2.7M, 47.5M였습니다. T=2^22일 때, 29.8PSNR을 보였습니다.
ACORN에서 36.9시간 학습하여 38.59 PSNR을 보였지만, 본 논문에서는 T=2^24로 셋팅하여 2.5분만에 같은 성능을 보이고, 4분후에 41.9 PSNR을 만들어냈습니다. ACORN보다 아주 작은 MLP를 사용하여 10X-100X속도를 만들어냈습니다.
Signed Distance Functions (SDF)

비교대상 논문은 NGLOD (2021)입니다. trainable feature vector를 Octree로부터 갖고 와서 MLP의 입력으로 사용하는 방식으로 속도와 퀄리티를 향상시킨 최신 기법입니다. (Octree개념은 Octree 이전글 참조) 본 연구 기법은 NGLOD와 유사한 performance와 memory cost를 보였습니다. Shading모델을 사용해서 SDF를 Visualize하였을 때, 일반적으로 color들은 약간의 변화에 민감하지만, Color들을 직접적으로 prediction하는 기존 방법론들 보다 본 연구 기법이 좀 더 강인한 것을 보였습니다. 자세히 보면 NGLOD에 비해 Hash방법의 표면이 거친 것을 볼 수 있는데, NGLOD는 Collision방지가되어 있기 때문에, Hash방법은 Hash collision영향으로 인해 발생됬다고 보고 있습니다.
Neural Radiance Caching (NRC)


NRC에서 MLP task는 Feature Buffer로부터 photorealistic한 pixel color를 예측하는 역할을 합니다. 3D coordinate가 포함되는 Per-Pixel Feature로써 Feature Buffer가 다뤄질 수 있기 때문에, MLP는 각 pixel에 독립적으로 수행됩니다. 그렇기 때문에 직접적으로 Hash Encoding을 적용 할 수 있습니다. Triangle Wave Encoding(2021) 기법과 비교하였을 때, 1920x1080해상도에서 Hash Encoding이 133FPS, Triangle Wave Encoding이 147FPS였습니다. 본 연구 기법이 약간 더 느렸습니다. mild performance라고 표현했네요.
Neural Radiance and Density Fields (NeRF)
Nvidia 홈페이지에서 Instant NeRF라고 부르네요.
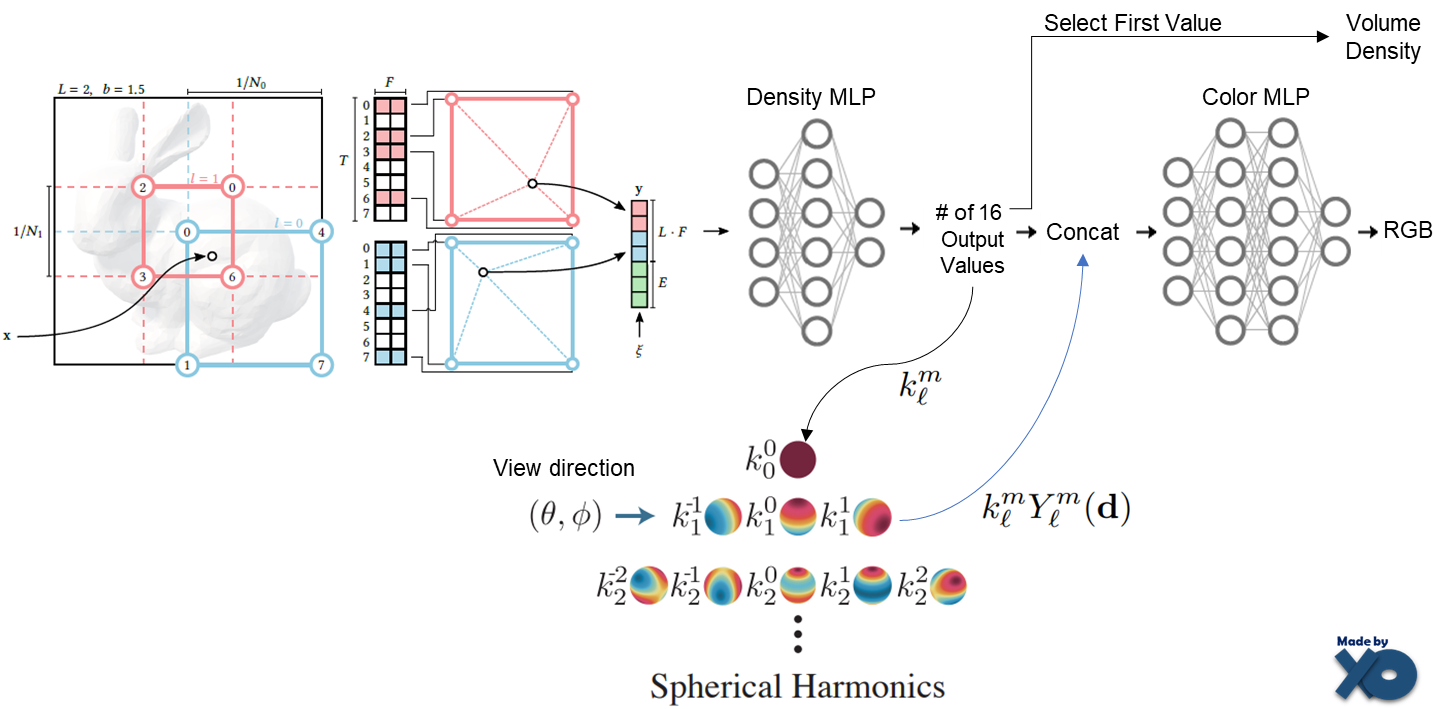
논문에 써져 있는 내용으로 제가 추측해서 도식화 하였습니다. 16개 output의 첫번째가 density가 된다는게 이상했는데, Spherical Harmonics의 첫번째 Yml값은 입력 view direction에 관계없이, 항상 같은 값을 갖기 때문에 coefficient를 Volume Density를 사용하는 것 처럼 보입니다. 추측입니다. 첫번째 Yml값에 대해서는 PlenOctree 이전글을 참조바랍니다.
그리고 이전 포스트에서 작성한 NeRF, PlenOctrees NerF모델 구조를 갖고 왔습니다. 이전 논문과 비교하면서Volume Desity와 Radiance로 어떻게 최종 Color값을 구하는지 참고하시면 됩니다.
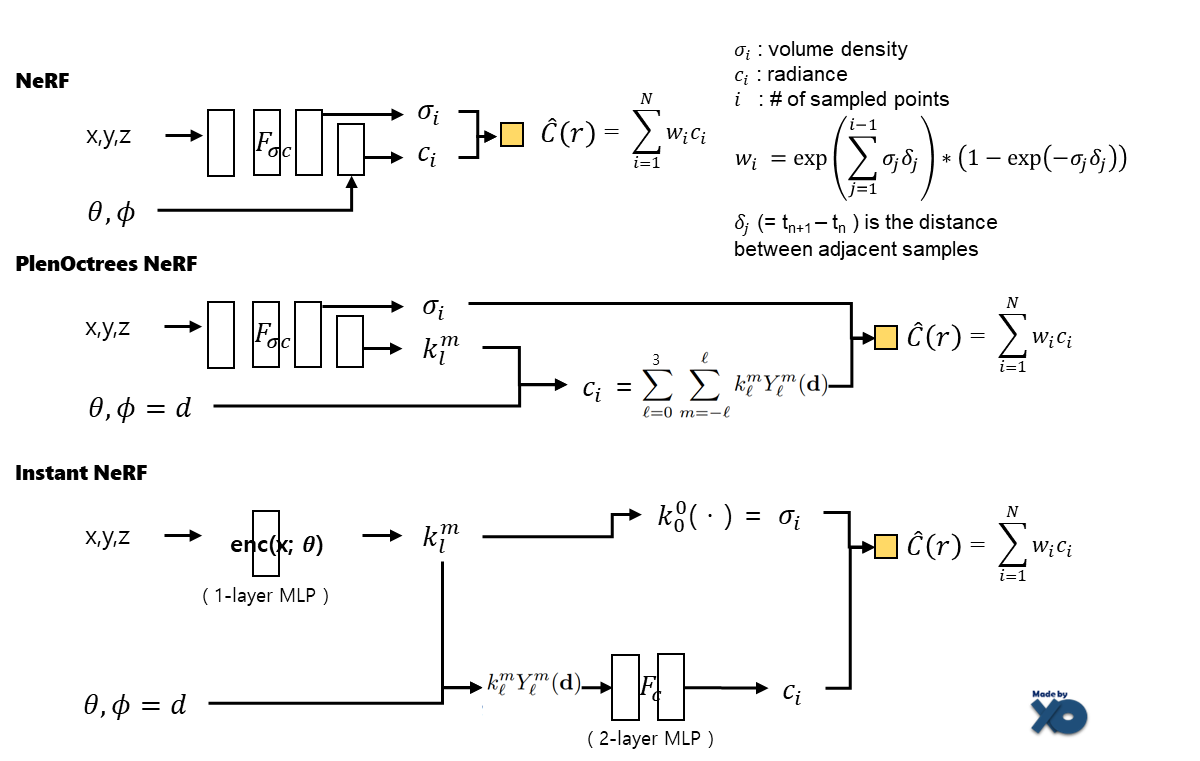
세부사항으로는 low dynamic-range(sRGB)를 가진 데이터는 sigmoid activation으로 학습시키고, high dynamic range(linear HDR)를 가진 데이터는 exponential activation으로 학습시켰습니다. 해당 activation에 대한 이점은 NeRF in thd Dark (NeRF in the Dark 이전글) 연구를 참조하라고 되어있습니다.
empty space인지 non-empty space인지를 mark한 Occupancy Grid를 유지하면서 surface 가까이에 있는 voxel들을 샘플링하였습니다. large scene의 경우, occupancy grid를 추가적으로 cascade하고, uniformly하게 샘플링하기보다 exponential하게 샘플링하였습니다.
HD해상도에서, RTX 3090에서 syntetic scene, real scene모두에서 수초내에 학습하였고, 60FPS로 랜더링하였습니다. MLP결과를 Caching하는 기법은 사용하지 않았습니다.
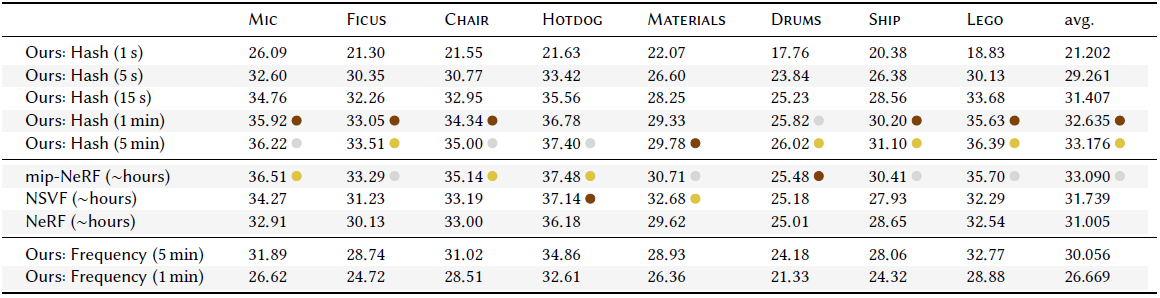
5초 학습에 꽤 괜찮은 성능을 보이고, 5분 학습하면 몇시간씩 학습한 다른 기법보다 더 좋은 결과도 보입니다.
Closing..
NeRF를 메인으로 블로그를 쓰고 있었는데, 본 논문에서 Encoding기법을 다루면서, Encoding기법을 사용한 다양한 분야의 모델을 볼 수 있었네요. Pretrain된 모델이 없는데도 아주 빠른 속도로 학습하고 랜더링합니다. 속도에서는 만족스럽지만 많은 입력 갯수가 필요한 NeRF의 단점을 갖고 있어서 아쉽네요. NeRF쪽을 자세하게 다뤘지만(?), 다른 분야도 한번 자세하게 보고 싶네요.
'NeRF' 카테고리의 다른 글
| [소스코드 분석] NeRF (ECCV 2020) (3) | 2022.11.26 |
|---|---|
| [논문 리뷰] BARF (ICCV 2021) : Unknown 카메라 pose에서 NeRF (1) | 2022.11.24 |
| [논문 리뷰] MVSNeRF (ICCV2021) : 적은 입력 + 학습 속도 개선 논문 (0) | 2022.10.27 |
| [논문 리뷰] Plenoxels (CVPR 2022) : 학습 속도 개선 논문 (0) | 2022.10.20 |
| [논문 리뷰] Point-NeRF (CVPR 2022) : 학습 속도 개선 논문 (1) | 2022.10.13 |




댓글