논문명 : MVSNeRF: Fast Generalizable Radiance Field Reconstruction from Multi-View Stereo

88개 Scene 각각에 대해 3개 이미지 입력으로 feature를 추출하는 모델을 pre-train하고, Novel Scene에 대해 16개 입력 이미지가 주어졌을 때 5-15분만에 Optimization(fine-tuning)하는 방법(c사진)에 관한 논문입니다.
3개 입력 이미지에 대해서도 좋은 랜더링 결과를 보였습니다(b사진). 시간은 명시되어 있지 않습니다.
(처음엔 본 논문이 3개 이미지 입력을 5-15분만에 학습하는걸로 착각 했었네요.)
전체적으로 3가지 Neural Network로 구성되어 있고, 전체 Network를 pre-train으로 30시간 학습(RTX2080Ti)해놓고, Novel Scene이 주어졌을 때, 앞의 2개 Network는 freezing하고 뒤의 1개 Network를 Fine-tuning하는 방식으로 속도를 개선 했습니다.
Overview

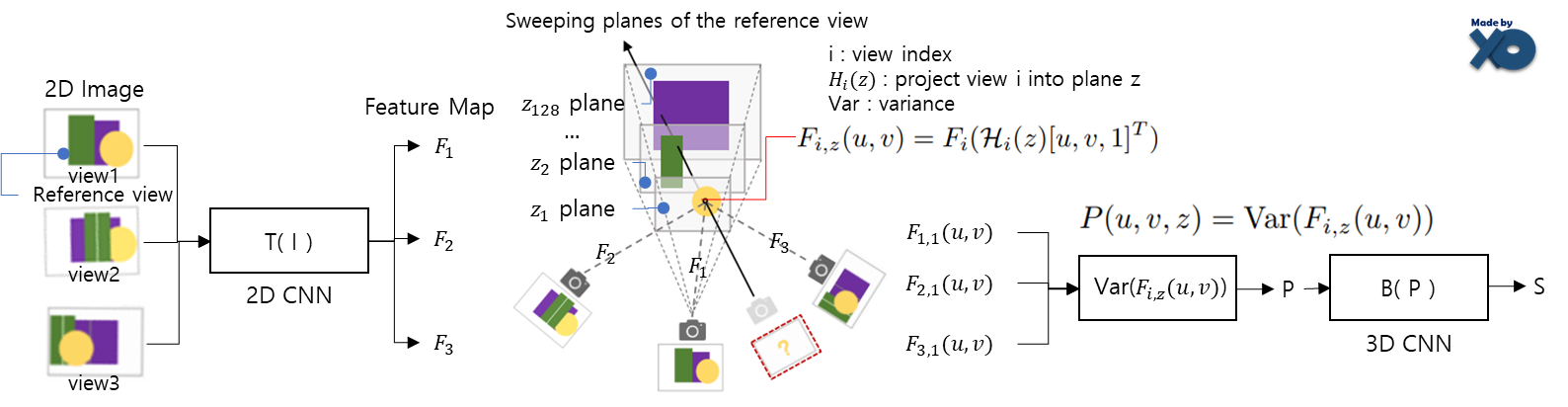
a) 각 이미지마다 2D CNN으로 feature를 추출하고, 1개의 view 시점에서 frustrum형태로 multi sweeping plane으로 만듭니다. 2D CNN Feature를 해당 plane들로 warping하여 cost volume이 설계되었습니다. (용어는 본문에 설명해두었습니다.)
b) Neural encoding volume을 reconstruct하기 위해 3D CNN를 사용하고, radiance field를 표현하기 위해 volume rendering properties를 regress하는 하나의 MLP를 사용하였습니다.
c) Network로부터 모델링되는 radiance field를 사용하여 novel viewpoint에서 이미지를 regression하도록 differentiable ray marching을 사용하였습니다. rendering loss로 전체 framework가 end-to-end 학습이 가능하도록 하였습니다.
+ Few image로 radiance field reconstruction을 하도록 하였습니다. 독립적으로 rendering quality를 향상시키기 위해, 16개의 image가 주어지면, reconstructed encoding volume과 MLP decoder가 빠르게 fine-tuned될 수 있게 하였습니다.
각각에 대해서 상세하게 다뤄보겠습니다.
a) Cost Volume Construction
학습 2D image 에서 feature를 CNN으로 추출합니다. downsampling convolution을 통해 HxWx3인 입력 이미지를 H/4 x W/4 x C 인 feature map으로 만듦니다. (C는 채널 갯수를 의미합니다.)
Reference View를 하나 지정하고, frustrum형태로 multi seeping plane (128개)을 만듭니다. View 1만 지정하고 view 2,3은 지정하지 않습니다. Frustrum은 절두체라고합니다. 아래 그림과 같습니다.

해당 학습 이미지 각각에 대한 카메라 parameter 사용해서, image feature map를 특정 dpeth z에 있는 sweeping plane로 투영하고, z깊이에서 u,v좌표의 feature map을 Fi,z(u,v)로 정의합니다. i는 i번째 학습 이미지를 의미합니다. Depth는 가장 먼 곳에서 가까운 곳까지 균등하게 샘플링 됩니다.
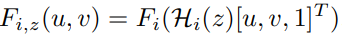
Cost volume은 여러 학습 이미지 M 개 view로부터 feature map인 Fi,z(u,v)의 분산(variance)으로 설계 되었습니다.

Hi(z)를 추가로 설명하자면, 핀홀 카메라 모델을 표현하는 수식인 K·R·t을 사용해서, 입력 view 이미지를 z번째 sweeping plane으로 변환하는 translation matrix를 계산하는 식입니다. (Intrinsic Camera Matrix인 K, camera rotation matrix인 R, translation matrix인 t를 나타냅니다.)
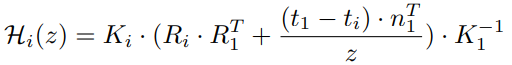
b) Radiance field reconstruction

image-feature cost volume P가 neural feature volume S로 transform할 수 있도록, 3D CNN B를 학습 했습니다.
- S=B(P)로 정의 하였습니다. 이전 MVS 연구들은 scene geometry만 표현하는 cost volume으로부터 직접적으로 depth probability를 예측하였었다고 합니다.
3D CNN B는 downsampling, upsampling, skip connection으로 구성된 3D UNet입니다.
- 이 구조는 효과적으로 infer할 수 있고, scene appearance를 propagate 할 수 있습니다. Unsupervised 방법으로 encoding volume을 infer할 수 있고, volume rendering으로 end-to-end train 할 수 있습니다.
view direction으로 ray를 그렸을 때, ray 위의 특정 3D 좌표 x에서의 neural featrue인 S로부터 density와 view-dependent radiance r을 regress하는 MLP A를 설계하였습니다.
- 특이한 점은 MLP의 input으로 학습 image의 원본 pixel값이 들어간다는 점입니다. 3D 좌표 x를 학습 image들의 plane으로 projection하였을 때, 각 plane의 pixel값들을 MLP입력으로 넣습니다. 앞선 3D CNN에서 2D feature extraction의 downsampling 때문에 scene encoding volume이 relative low resolution 특성을 가진다고 합니다. 때문에 High-frequency appearance regress를 위해 이러한 기법을 사용했다고 합니다. 1개 ray당 128개의 point가 샘플링 됩니다.
다음과 같이 정의 될 수 있습니다.
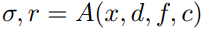
최초 NeRF에서는 coarse, fine network로 MLP가 구분되는데, MVSNeRF에서는 single MLP입니다. 그래도 성능이 좋았다고 합니다.
Location x에서 feature volume S로부터 trilinear interpolation합니다.
- 자세한 설명이 없는데, multi seeping plane을 사용하기 때문에, 모든 좌표에 feature가 없을 것이므로, feature가 없는 위치에 feature를 주변 값으로 interpolation한다는 의미로 보입니다. 이를 통해 나온 neural feature를 f = S(x)로 정의합니다. S=B(P)이므로, f=B(P(x))로 표현 될 듯 합니다. x는 NDC(normalized device coordinate) 공간으로 나타내어 unit vector로 표현됩니다. NDC 공간을 사용하는 것은, 다른 데이터 소스로부터 scene scale을 normalize하는데 효과적이어서 좋은 generalizability를 보였다고 합니다.
MLP decoder A의 입력값들은 최초 NeRF와 같이 positional encoding을 사용하였습니다.
c) Volume Rendering and end-to-end training
Volume rendering은 최초 NeRF와 똑같이 Volume Rendering 기본 수식을 기반으로 설계하였습니다. 설명은 최초 NeRF 이전 포스트 를 참조바랍니다. (최초 NeRF와 비교하였을 때, MVSNeRF는 가장 먼 곳과 가까운 곳을 균등한 간격으로 ray위 point를 샘플링하므로 간격을 나타내는 인자는 없습니다.)
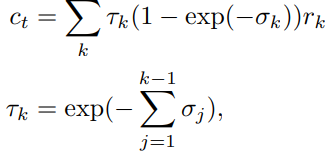
이렇게 계산한 color값과 GT의 color값의 차이를 L2 loss로 사용합니다.

최초 NeRF는 scene마다 학습에 초점이 맞춰져 있었다면, MVSNeRF는 DTU데이터의 서로 다른 Scene으로 전체 네트워크를 학습합니다.
이러한 설계를 통해, Geometric-aware scene 추론에 유용하였고, (High-quality view 합성 할 수 있는) novel testing scene에서 (neural encoding volume으로 radiance field를 reconstruction 할 수 있는) generic function을 효과적으로 학습 할 수 있었습니다.
Dense Image(많은 입력 데이터)가 주어질 경우 Optimization 방법
앞에 설계를 통해 3개 입력으로 generalizable function는 만들 수 있지만, Scene간의 diversity로 인해 좋은 퀄리티를 만드는 건 어렵습니다. 추가로 많은 입력 데이터셋이 주어졌을 경우에 Optimization하여 퀄리티를 향상시키는 방법을 소개합니다.
2D CNN, plane-sweep warping, 3D CNN의 network processing 는 freeze하여 그대로 사용하고 encoding volume S와 MLP만 optimize(fine-tune)합니다. 이를 통해 매우 빠르게 Optimization(학습) 할 수 있고, Voxel마다 local neural feature를 독립적으로 adjust하는 neural optimization에 좀 더 flexibility를 만듭니다.
Encoding volume S는 Sparse Voxel field기법과 유사합니다. Sparse Voxel fields방법에서는 pure per-scene optimization 되지만 MVSNeRF에서는 초기에 빠른 inference를 통해 network로부터 prediction 되어집니다. 다른 관점으로, Sparse Voxel fields방법처럼 좋은 성능을 위해 fine-tuning안에서 volume grid로 분할 될 수 있습니다.
Appending Colors
앞선 소개에서 Neural encoding volume S가 MLP decoder로 보내질 때, pixel color와 combine되었습니다. Fine-tuning 설계로는 적절하지만 reconstruction이 항상 3개 input에 의존성을 갖게 됩니다.
Encoding volume S에 추가적인 채널로써 voxel center들의 per-view color를 더함으로써 독립적인 neural reconstruction을 만들었습니다. (이해가 안되는 부분 - 원본 : We instead achieve an independent neural reconstruction by appending the per-view colors of voxel centers as additional channels to the encoding volume)
Feature로써 이 color들은 per-scene optimization에서 학습됩니다. 이러한 간단한 appending은 랜더링 초기에 blur로 보일 수 있지만, fine-tuning과정에서 매우 빠르게 처리됩니다. Color를 appending한 후의 Encoding volume S는 reasonable image를 합성 할 수 있는 적절한 initial radiance field입니다.
Implementation details
데이터셋 : generalizable network를 학습하기 위해 DTU데이터셋으로 학습했습니다. PixelNeRF(이전 포스트) 의 방법을 따라 512x640해상도를 88:16=train:test scene으로 나누었습니다. 학습데이터와 다른 distribution을 가진 Realistc Synthetic NeRF data와 Forward-Facing data로 모델을 test했습니다. 각 test scene에서 20개 가까운 view를 선택하고, 3의 center view들을 input으로, 13개를 per-scene fine-tuning을 위한 추가적인 input으로, 나머지 4개를 test view로 두었습니다.
Network details
첫행은 2D CNN, 두번째행은 3D CNN, 3번째행은 MLP decoder를 의미합니다. K는 kernerl size, s는 stride, d는 kernal dilation, chns은 각 layer의 input/output 채널을 의미합니다. CBR2D/CBR3D/CTB3D/ LR/PE 는 ConvBnReLU2D/ConvBnReLU3D/ConvTransposeBn3D/ LinearRelu/Positional Encoding을 의미합니다.
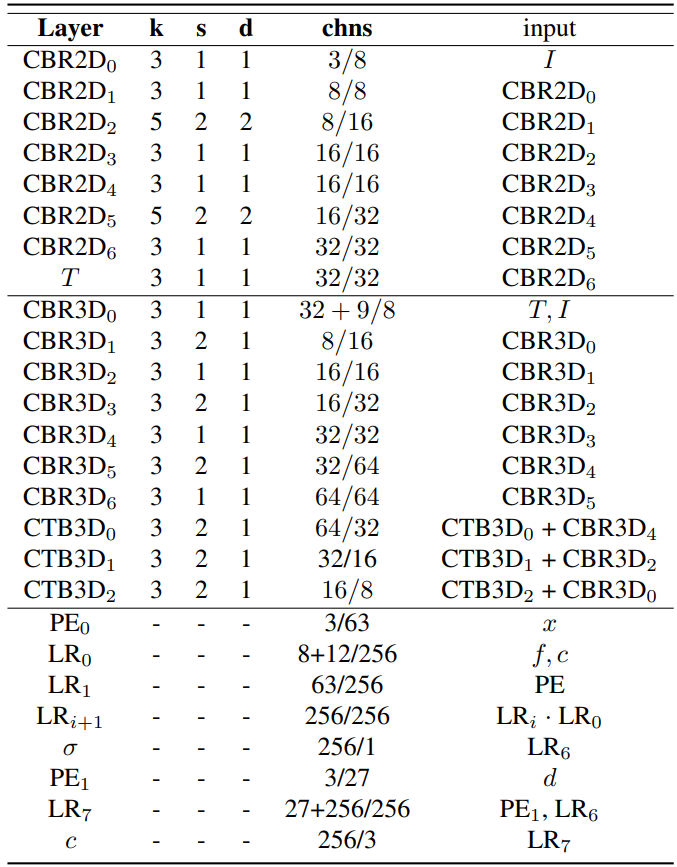
2080TI을 사용했고, 1개 배치마다 1024 pixels들을 랜덤하게 샘플하여 학습하였습니다.
Experiments
Comparisons on results with three-image input
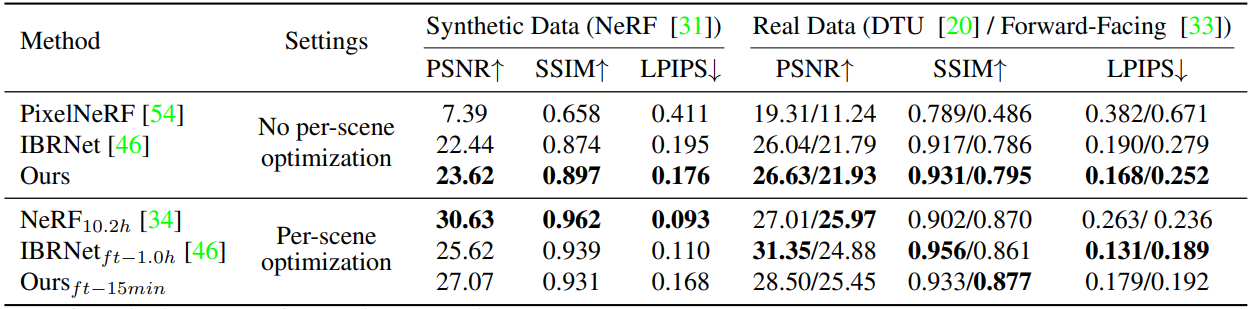

평가지표에 대해서는 PSNR/SSIM/LPIPS 글에 소개해 두었습니다.
Radiance field reconstruction을 generalization한 유사한 논문인 PixelNeRF(이전 포스트), IBRNet과 비교하였고, DTU데이터셋에서 3개의 center view를 input으로 학습하였습니다. 그리고 4장으로 각 Scene을 test하였습니다. No per-scene optimization은 3장으로 optimization한 것이고, Per-scene Optimization은 16장으로 optimization한 결과 입니다. DTU 데이터셋으로 학습하고, DTU 데이터셋, Synthetic Data 데이터셋, Forward-facing 데이터셋으로 테스트 하였습니다. 논문에는 명시되지 않았지만 github코드에서 2D CNN, 3D CNN pre-train에 6 Epoch을 했고, 총 30시간 소요되었다고 합니다.
PixelNeRF는 DTU데이터셋에 Overfit되는 경향을 보였습니다. Realistc Synthetic scene에서 obvious artifact를 포함하였고, Forward-Facing scene에서 완전히 fail되었습니다. IBRNet은 다른 데이터셋에서 PixelNerF보다 확실히 성능이 좋았지만, flicker(빛의 깜빡임) artifact가 관측었고, video에서는 더 분명하게 나타났습니다. MVSNeRF는 모든 경우에 더 좋은 성능을 보였습니다. Plane-swept cost volume에서 geometry-aware scene 추론을 위한 MVS 기법을 사용하고, neural encoding volume으로써 localized radiance field representation을 reconstruction하였기 때문입니다.
Per-scene fine-tuning results
16개의 input image로 per-scene optimization하였습니다. 15분의 짧은 시간 동안 (10K iteration) fine-tune을 하였습니다. Photo-relistic결과를 보였습니다. 장시간(10.2hours)의 ptimization으로 생성되는 NeRF와 비교하였습니다. 퀄리티가 같거나(Realistc Synthetic), 더 좋았습니다(DTU, Forward-Facing).
시간에 따른 결과를 비교하였습니다. MVSNeRF가 확실히 수렴속도가 빠르는 것을 볼 수 있습니다.

Initial radiance field를 가능하게 하는 generic network를 사용함으로써, dense image가 주어질 때, practical한 per-scene radiance field reconstruction이 가능하게 하였습니다.
Depth reconstruction
Volume density로써 scene geometry를 나타내는 radiance field를 reconstruct합니다. Marched ray의 샘플링된 point의 depth value의 weighted sum인 volume density값으로 생성되는 depth reconstruction 결과와 비교함으로써 geometry reconstruction quality를 평가하였습니다.
DTU test셋으로 Radiance field method와 MVSNet 과 비교하였습니다. Cost-volume 기반 reconstruction 덕분에, 다른 neural rendering method보다 좀더 정교한 depth를 보였습니다. MVSNeRF는 depth 지도 학습하지 않고, 랜더링 지도학습만 하였지만, direct하게 depth 지도학습하는 MVSNet와 비교하였을 때 좀더 정확하였습니다. 이를 통해, Realistic rendering을 만드는 주요 factor는 geometry reconstruction의 퀄리티라는 것을 알 수 있습니다.

Limitation
- High glossiness/specularities가진 scene에서는 network를 통해 directly하게 recover 하기가 어려울 수 있고, fine-tuning process 시간이 오래 소요될 수 있습니다.
- reference view에 있는 scene contents에서만 잘 reconstruct됩니다. Volume을 padding하는 것은 초기 frstrum을 벗어난 contents를 포함 할 수 있지만 occluded되고 보이지 않는 영역은 network로 부터 직접적으로 recover될 수 없습니다. 때문에, single neural encoding volume S로부터 wide view range를 랜더링 하는 것은 challenge하다고 합니다.
- Scene주변에 cover하는 dense image로 long per-scene fine-tuning은 360도 랜더링을 할 수 있지만, 최초 NeRF처럼 training속도가 느립니다.
- Multiple view에서 multiple neural encoding volume을 조합하면서 large view range를 빠른 속도로 하는 것은 다음 연구 주제가 될 수 있습니다.
Closing
최초NeRF는 많은 학습 이미지로 scene마다 학습하고 generalization 하지 않았기 때문에, 연산량이 많았습니다. MVSNeRF에서는 여러 이미지로 feature extraction 부분을 학습하고, 재사용해서 학습속도를 높였습니다.
3장 입력 이미지에 대한 optimization속도가 16장 입력 이미지에 대한 속도와 비슷할 것 같을 거라 생각되는데 궁금해서 한번 구동해보고 싶네요.
Novel View Direction마다 Rendering 시간은 최초 NeRF와 비슷할 것 같습니다.
Reference
'NeRF' 카테고리의 다른 글
| [논문 리뷰] BARF (ICCV 2021) : Unknown 카메라 pose에서 NeRF (1) | 2022.11.24 |
|---|---|
| [논문 리뷰] Instant NGP(SIGGRAPH 2022) : 인코딩 방법 개선으로 속도 향상 (2) | 2022.11.10 |
| [논문 리뷰] Plenoxels (CVPR 2022) : 학습 속도 개선 논문 (0) | 2022.10.20 |
| [논문 리뷰] Point-NeRF (CVPR 2022) : 학습 속도 개선 논문 (1) | 2022.10.13 |
| [논문 리뷰] PlenOctrees for NeRF (ICCV 2021) : 랜더링 속도 개선 논문 (4) | 2022.10.12 |




댓글