논문명 : PlenOctrees for Real-time Rendering of Neural Radiance Fields(ICCV 2021)
Introduce
학습된 NeRF모델을 다양한 View Direction으로 실시간 랜더링하는 서비스 시나리오에서, 800x800해상도 이미지 1장 Rendering에 30초 소요되는 기존 NeRF논문으로는 실시간 Rendering이 불가능합니다. 본 논문에서는 이를 V100 GPU에서 약6ms로 처리하는 방법에 대해 소개합니다. Training시간이 아닌 Test시에 Rendering시간을 획기적으로 개선한 연구입니다.
이 글은 최초 NeRF 와 비교하는 방식으로 설명 합니다.
NeRF에 대해서 리마인드하지 않으면 읽기 어려울 수 있습니다. -> NeRF 정리 글
최초 NeRF는 View Direction마다 Dense하게 샘플링된 Voxel들이 Neural Network를 통과하면서 속도가 느렸습니다. 예시로, 이미지 해상도를 800x800, Novel View Direction을 100, Ray마다 샘플링하는 voxel 개수를 192로 가정할 때, 연산속도에 가장 영향을 많이 미치는 Neural Network 통과 횟수를 비교하면, 아래와 같이 개선이 됩니다.
기존 800 x 800 x 100 x 192
개선 800 x 800 x 1 x (192이하)
이를 해결 하기 위해 크게 2가지 기법을 통해 연산량을 대폭 줄입니다.
1) Spherical Harmonics으로 View Direction에 관한 연산량 축소
2) Octree로 샘플링에 관한 연산량 축소
Spherical Harmonics으로 View Direction에 관한 연산량 축소
Spherical Harmonics(SH)는 함수 구면 좌표계에서 라플라시아 방정식을 만족하는 (조화)함수입니다.
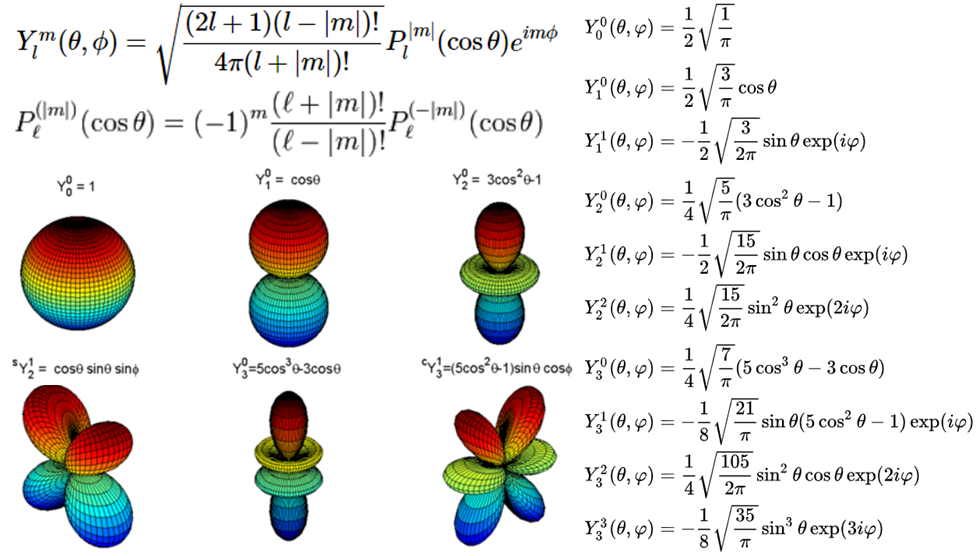
Neural Network가 Voxel좌표를 입력받아, Spherical Harmonics의 coefficient를 출력하도록 만듭니다.

coefficient는 각 Yml에 곱해질 계수를 의미합니다. 아래 수식에서는 k로 되어 있지만 위 예제에서는 C입니다.
-> Voxel마다 서로 다른 SH구조를 생성하게 됩니다.

만들어진 SH구조에 View Direction으로 RGB값을 획득합니다.
-> 1개 voxel에 대해서 NN를 계산해두면, View Direction이 바뀌어도 다시 NN을 하지 않아도 됩니다.
기존 NeRF와 비교하여 다시 설명하자면, radiance 값에 대해, Neural Network의 결과를 곧바로 사용하지 않고, coefficient(k)와 view direction(d)을 입력으로 받는 SH함수로 계산한다는 점입니다.

SH에서 l은 0~4, m은 -l에서 +l까지이기 때문에, 연산량이 이전 NeRF의 Neural Network 방식보다 확실히 적습니다.
Rendering 할 때 뿐만 아니라, Train과정에서도 수렴이 빨리되어 약 10% 속도 향상을 보였습니다.
Train과정에서 memory를 적게 사용합니다.
학습된 NeRF모델을 NeRF-SH모델로 변환 할 수 있습니다. 구체적으로 각 point에 대해, 무작위 view direction으로 NeRF를 Sampling하여 근사치를 추정하는 몬테 카를로 estimation방법을 사용 할 수 있습니다. Point마다 10000 view direction으로 샘플했을 때, 2시간이 소요되었고, PSNR이 1.8차이가 났습니다.
Sparsity Prior Loss 추가 : 기존 NeRF에서 관측되지 못한 Voxel영역들은 임의 geometry값으로 채워지며, 퀄리티에 큰 영향을 미치지 않았습니다.
하지만 뒤에 소개 할 conversion process에 영향이 있어, 아래와 같은 sparsity prior Loss를 추가하였습니다. K는 한 개 Ray에서 sampling한 point의 개수 이고, σ는 volume density이고, λ, Βsparsity는 상수입니다.
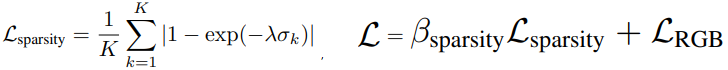
Octree로 샘플링에 관한 연산량 축소
Octree란? 여덟개(oct)의 자식 노드를 가진 트리 자료구조로, 삼차원 공간을 재귀적으로 분할할때 사용합니다.

저자는 Octree자료구조와 SH구조를 사용하여 Plen Octree를 제시합니다. 저자 발표영상을 보면 아래와 같이 표현하고 있습니다.
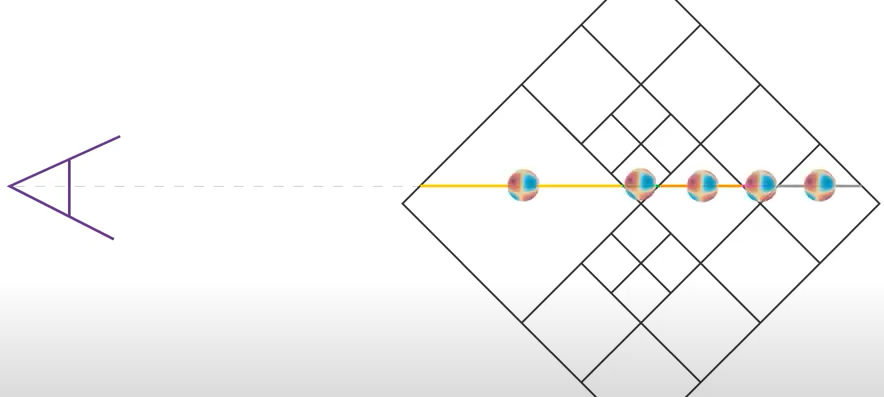
PlenOctree Rendering : Tree가 구성되어 있다는 전제하에 랜더링 방법을 먼저 설명합니다.
- 1) Octree구조에서 ray를 그려 density, color를 가진 voxel grid를 구분합니다. 위 그림에서 각 네모가 voxel grid를 의미합니다.
2) NeRF의 volume rendering 모델로부터 inference한 Color를 해당 ray로 적용합니다. 위 그림에서 SH를 형상화한 구가 Ray위에 위치 되어 있습니다. 이 Ray위의 값들은 기존 NeRF와 동일 방법으로 모두 Weight Summation됩니다.
이러한 접근법은 color와 volume density를 가진 small voxel을 놓치지 않으면서, 값이 없는 large voxel들을 skip할 수 있게 합니다. Test시에는 ray의 transmittance를 합친 Ti값이 0.01보다 적을 경우, 멈추게 함으로써 랜더링 속도를 향상시킵니다.
PlenOctree Conversion : NeRF-SH를 Conversion하여 PlenOctree를 생성합니다.
- Evaluation, Filtering, Sampling 3단계로 나누어집니다.
- Evaluation : NeRF-SH model로 uniform한 3D grid에서 σ(volume density)를 구합니다. Voxel Grid크기는 scene content에 딱 맞게 조절됩니다.
- Filtering : 각 voxel grid의 ray weight(=1-exp(−σiδi))의 최대값은 유지하면서, Threshould보다 낮은 weight를 가진 voxel grid을 제거합니다. 제거 후 남아있는 voxel들로 octree가 만들어집니다. 이는 각 점에서 σ(volume density)로 threshold와 비교하여, non-visible voxel를 제거하게 됩니다.
- Sampling : 각 남아있는 voxel grid 안에서 256개 random point를 샘플링하고, aliasing을 줄이기 위해 이 값의 평균을 octree의 leaf에 저장합니다. 각 leaf는 density와 SH coefficient를 갖게 됩니다. 총 256개 point extraction process에 15분이 소요됩니다. 8개를 sampling하면 1.5분 소요됩니다.
Result
Dataset
- Synthetic NeRF dataset(2020) : 8scene, 100개 view-direction 이미지 , 800x800해상도
Tanks and Temple dataset(2017) : NSVF의 subset에 해당, 5scene, 152-384 view-direction 이미지, 1920x1080해상도
실험 셋팅
- Jax가 reimplmentation한 original NeRF코드를 사용하였습니다.
Synthetic NeRF에서는 SH의 lmax를 3, Tank&Temple에서는 SH의 lmax를 4로 셋팅하였습니다.
Tesla V100기준으로 시간을 측정 하였습니다.
Evaluation
- 퀄리티는 original NeRF보다 약간 좋고, 랜더링 속도는 3000배 향상되었습니다.
(평가지표 의미 : PSNR/SSIM/LPIPS )
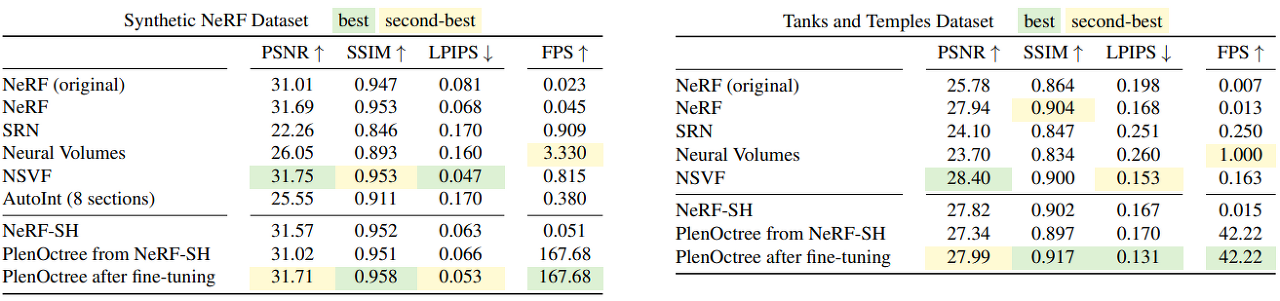
- Rendering 속도 대비 PSNR을 비교하였을 때, Trade-off가 있었습니다. Table1은 위에 테이블을 의미합니다. GB는 Tree의 메모리를 의미하는 것으로 보이며, grid size 256은 512^3에서 256^3으로 줄었다는 것을 의미합니다.

- Training 시간을 비교하였을 때, NeRF와 NeRF-SH는 비슷한 성능을 보였고, NeRF-SH가 수렴되기 전에 ealry stop한 뒤 PlenOctree로 conversion하여 학습하였을 때, 빠르고 좋은 퀄리티를 보여줬습니다. (아래 그래프를 보면, PlenOctree 시작 시간이 약 1시간 뒤인 것을 볼 수 있습니다.)

- Web browser에서 구현한 결과는 여기서 확인할 수 있습니다.
https://alexyu.net/plenoctrees/
Limitation
- 메모리가 너무 많이 사용되어서, 웹 서비스를 위해 30-120MB까지 압축이 필요합니다.
- 3DOF는 지원하지만 6DOF view를 지원하지 하지 않습니다.
Closing..
- Rendering속도를 획기적으로 줄였지만, Training시간까지는 줄이지 못하고 메모리는 오히려 더 많이 사용하였습니다. 이후에 나온 논문들에서는 Training속도까지 줄이게 됩니다. 이후의 Post에서도 최초 NeRF 논문이 변형되며 발전되는 모습을 적어보겠습니다.
'NeRF' 카테고리의 다른 글
| [논문 리뷰] MVSNeRF (ICCV2021) : 적은 입력 + 학습 속도 개선 논문 (0) | 2022.10.27 |
|---|---|
| [논문 리뷰] Plenoxels (CVPR 2022) : 학습 속도 개선 논문 (0) | 2022.10.20 |
| [논문 리뷰] Point-NeRF (CVPR 2022) : 학습 속도 개선 논문 (1) | 2022.10.13 |
| [논문 리뷰] PixelNeRF (CVPR 2021) : 입력 이미지 갯수를 개선한 NeRF 연구 (0) | 2022.10.11 |
| [논문 리뷰] NeRF (ECCV 2020) : NeRF 최초 논문 (3) | 2022.10.08 |




댓글