논문명 : PixelNeRF: Neural Radiance Fields from One or Few Images
PixelNeRF 소개 사이트 에서 연구 결과 3개를 가져왔습니다.
PixelNeRF로 입력이 1개, 2개, 3개(좌측) 일 때 Rendering결과(우측)입니다.
가장 마지막 열은 NeRF로 3개 입력에 대한 결과 입니다.






PixelNeRF는 1~3장의 Image와 해당 Image에 대한 View Direction이 입력으로 주어질 때, 입력에 없던 View Direction에서 보여질 Image를 합성하는 연구입니다. 초기 NeRF연구에선 50~100 장의 이미지가 입력으로 필요했었지만, PixelNeRF에서는 입력 이미지 수를 줄였습니다.
Prior Knowledge를 가질 수 있게 CNN Encoder를 사용함으로써, 적은 수의 Input Image로 다양한 View Direction을 Rendering 할 수 있게 하고 속도 또한 개선 하였습니다.
Algorithm
Scene들 간의 knowledge를 재사용하지 못하는 최초 NeRF연구를 개선하고자, 최초 NeRF연구에서 Spatial Image Feature를 사용 할 수 있도록 설계하였습니다.
- 입력 이미지에서 각 Pixel을 해당 Pixel과 매핑되는 feature grid로 Encoding
- View Direction과 Encoding된 feature가 주어졌을 때, NeRF Network로 Color와 density를 출력
- 공간 좌표계는 초기NeRF에서 사용한 Canonical Space(Object가 중심이 되는 자표 시스템)을 사용하지 않고 입력 View에 대한 Camera Space(촬영 카메라가 중심이 되는 좌표 시스템)을 사용
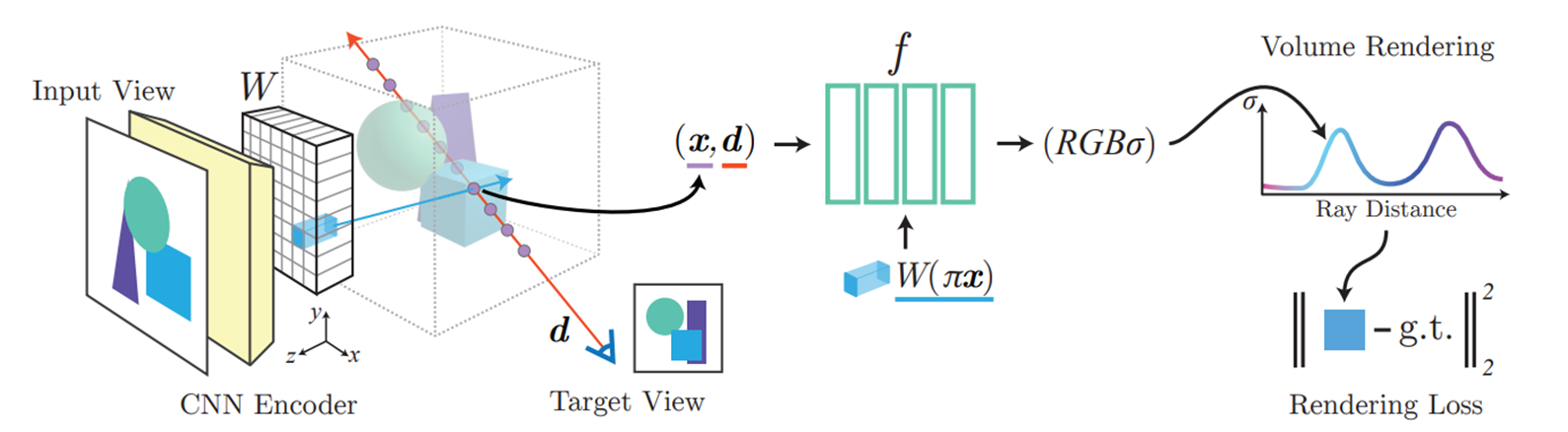
전체 Sequence
하나의 scene에서 입력 이미지I가 주어졌을 때, 이미지가 CNN을 통과하여 Feature Volume(Vector)을 추출합니다. 이는 Encoder과정으로써, W=E(I)로 나타냅니다.
Target View에서 한 pixel에 대해 카메라 ray를 그었을 때, 각 Voxel x에 대해 Input 2D image의 좌표공간으로 projection하여, project된 이미지 pixel에 해당하는 Feature Vector를 갖고 옵니다. 이를 W(π(x))라고 표현 합니다.
- 카메라 Intrinsic Parameter(focal length, pricipal points, skew coeficient)를 사용하여 projection합니다. (Intrinsic Parameter가 주어져야 합니다.)
- 3D를 2D로 projection하면 pixel에 정확히 매칭이 안되므로, 주변 pixel에 해당하는 Feature Vector값들을 Bilinear interpolation합니다.
그리고 NeRF Network를 통과합니다.
- Image Feature는 position정보와 view direction 정보와 함께 NeRF network의 입력으로 사용됩니다. 둘다 카메라 좌표계를 사용합니다.
- r()은 NeRF에서 소개된 Positional Encoding으로 표현합니다.
- 출력은 최초 NeRF와 같이, volume density와 radiance를 출력으로 가집니다.
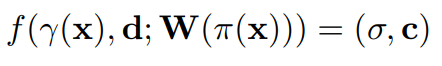
NeRF Network Architecture
- 입력이 2개 이상일 경우에는 아래와 같습니다.
- 입력이 1개일 경우에는 V(2~N)을 사용하지 않습니다.

Train Process

Train dataset의 각 Scene마다 1~3개 view를 random으로 샘플링하여 CNN Encoder(W)를 학습하고, 해당 Scene의 모든 view들로 NeRF Network(F)를 학습합니다.
NeRF Netowrk(F)의 Weight를 업데이트 하는 방법은 최초 NeRF 에서 Train Process부분을 참고 바랍니다.
CNN ENcoder(W)의 Weight를 업데이트하는 방법은 구체적으로 명시되어 있지 않지만, NeRF Network(F) 출력 Layer로부터 W(π(x))까지 전파된 에러값을 사용해서 업데이트 합니다.
추가적인 기법으로, Train 전체 interation 중 첫 2/3정도는 Object영역에 해당하는 Bounding Box 안에서만 Voxel을 샘플링하고, 그 후 나머지 1/3정도는 이미지 전체에 대해 Voxel을 샘플링하여 background artifacts를 피하고자 하였습니다.
Test Process
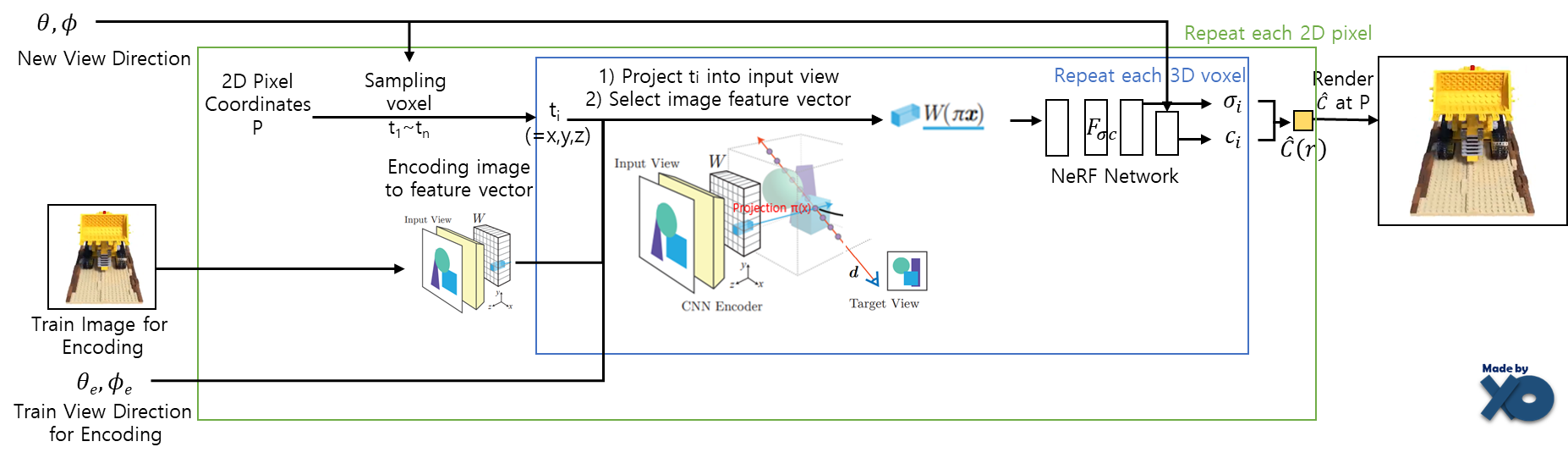
Test dataset에서 1~3개의 인코딩용 이미지를 CNN Encoder(W)을 사용하여 Feature Vector로 생성하고, Novel View에 대한 이미지를 NeRF Network(F)를 사용해 Rendering합니다.
구체적인 Rendering알고리즘은 최초 NeRF 에서 Test Process부분을 참고 바랍니다.
Experiments
6가지 실험에 대해 소개되어 있습니다.
1. Category-specific View Synthesis Benchmark
2. Category-agnostic Object Prior
3. Generalization to novel categories
4. Multiple-object scenes
5. Sim2Real on Cars
6. Scene Prior on Real Images
평가지표에 대해서는 PSNR/SSIM/LPIPS 글에 소개해두었습니다.
1. Category-specific View Synthesis Benchmark
- ShapeNet의 char,car 카테고리마다 모델을 훈련하여 평가 하였습니다.
- Train : Scene마다 50개의 random view를 사용 하였습니다. 50개의 view중에 1or2개 view로 Encoder를 학습하고, 50개의 view는 NeRF weight를 업데이트 하기 위한 loss계산에 사용 되었습니다.
- Inference : ShapeNet Testset에서 각 Scene에 대해 1or2개의 view로 Feature Vector를 만들고, 다른 251개 View Direction으로 rendering하여 평가 하였습니다.
- Train Time : Titan RTX, 400000 iteration, 6days
- Result : Single view, Two-view 입력 둘다에서 좋은 성능을 보였습니다.

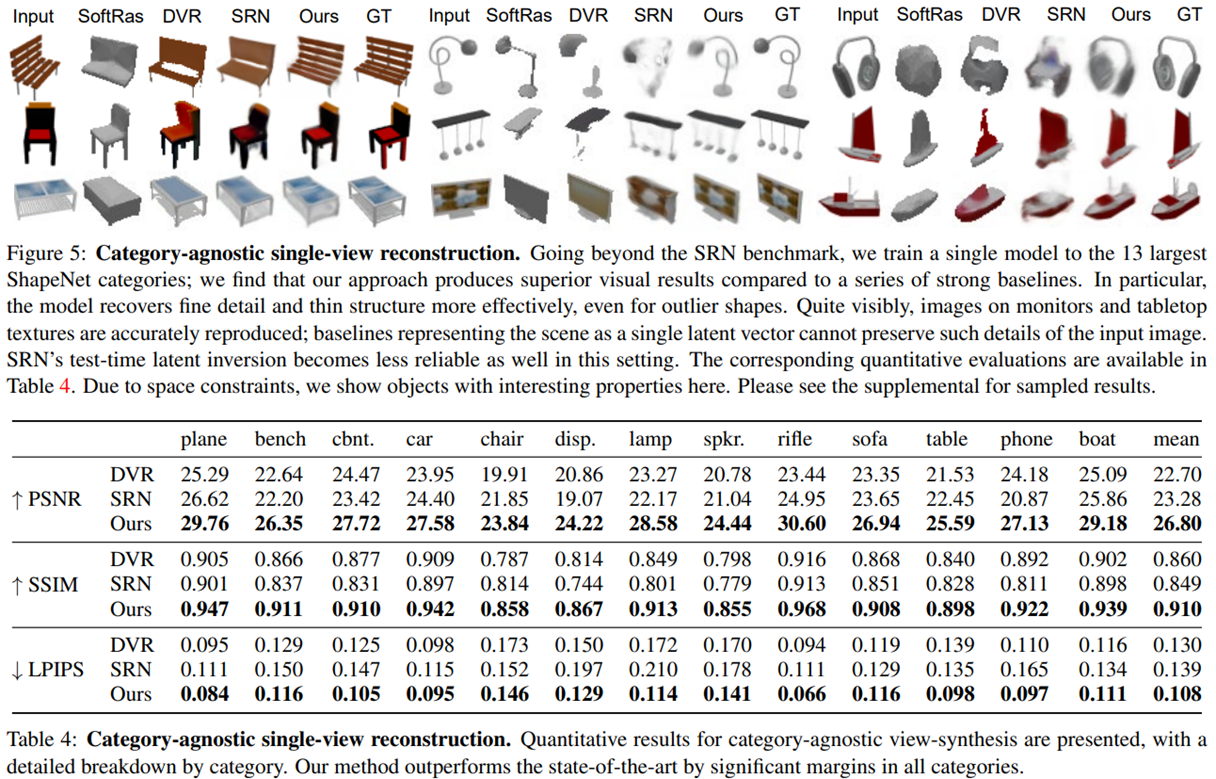
2. Category-agnostic Object Prior
- 13개의 카테고리로 1개의 모델을 학습하고 평가 하였습니다.
- Train : ShapeNet 13개 카테고리의 80%의 Scene을 Training set으로 두고, 각 Scene마다 1개 view로 Encoder를 학습 하였습니다.
- Inference : ShapeNet 13개 카테고리의 20%의 scene을 Test set으로 두고, 각 Secne마다 1개 view로 Feqture Vector를 만들어 다른 23개 각도로 rendering하여 평가 하였습니다.
- Train Time : RTX 2080Ti, 800000 iteration, 6days
- Result : 1개의 모델로 다양한 카테고리를 커버할 수 있었습니다.
3. Generalization to novel categories
- ShapeNet 3개 카테고리로 1개의 모델을 학습하고 10개 카테고리 각각의 23개 view로 평가 하였습니다.
- Train Time : GTX 1080Ti, 680000 iteration, 5days
- Result : 학습하지 않은 카테고리도 성능이 좋은 것을 확인 할 수 있었습니다. intrinsic geometric과 apperance prior를 학습 한다는 것을 보여줍니다.

4. Multiple-object scenes
- ShapeNet 2개의 의자 object를 무작위로 배치하여 학습 및 평가 하였습니다.
- Train : 2715개 scene으로 모델을 학습 하였습니다. 각 Scene마다 20개의 view가 있고, 20개의 view중에 2개의 view로 Encoder를 학습하였습니다.
- Inference : 1101개의 Scene마다 50개의 view가 있습니다. 50개의 view중에 2개의 view로 Feature Vector를 만들고, 다른 48개 각도로 rendering하여 평가 하였습니다.
- Result : 추가design 변형없는 simple한 Scene에서 잘 수행됩니다.

5. Sim2Real on Cars
- 실험1에서 학습한 car 카테고리의 모델을 다른 데이터셋인 Standford Car 데이터셋으로 평가하였습니다.
- Result : Synthetic Domain을 넘어 변환 될 수 있다는 것을 보여줍니다.

6. Scene Prior on Real Images
- 현실 데이터셋인 DTU MVS으로 학습하고 평가하였습니다. 데이터셋의 특징은 배경과 빛이 있고, 복잡합니다. 400x300 해상도에 88개 Train셋, 15개 Test셋을 갖고 있습니다.
- Train : 3개의 view로 Encoder를 학습 하였습니다.
- Inference : 3개의 view로 Feature Vector를 만들고, 다른 View Direction으로 Rendering 하여 평가 하였습니다.
- Result : 복잡한 데이터셋에도 잘 적용되는 것을 확인 할 수 있습니다.

Closing..
1~3개의 입력 이미지로 Rendering 할 수 있다는데 의의가 있는 연구였습니다. 1개 입력으로 Rendering한 결과물 퀄리티가 약간 아쉽고, 느린게 단점이지만, 이 정도로 성능이 나온 것도 대단하다고 생각합니다. 현실 문제에서는 입력 이미지 수가 적고 속도가 빨라야 되는 시나리오가 만들어지기 마련인데, 입력 이미지수 관점에서는 어느 정도 해결 해준 것 같습니다. 향후 NeRF속도를 개선한 다른 연구들과 잘 조합하면 되지 않을까 생각해봅니다.
'NeRF' 카테고리의 다른 글
| [논문 리뷰] MVSNeRF (ICCV2021) : 적은 입력 + 학습 속도 개선 논문 (0) | 2022.10.27 |
|---|---|
| [논문 리뷰] Plenoxels (CVPR 2022) : 학습 속도 개선 논문 (0) | 2022.10.20 |
| [논문 리뷰] Point-NeRF (CVPR 2022) : 학습 속도 개선 논문 (1) | 2022.10.13 |
| [논문 리뷰] PlenOctrees for NeRF (ICCV 2021) : 랜더링 속도 개선 논문 (4) | 2022.10.12 |
| [논문 리뷰] NeRF (ECCV 2020) : NeRF 최초 논문 (3) | 2022.10.08 |




댓글