GaussianEditor: Swift and Controllable 3D Editing with Gaussian Splatting, Yiwen Chen, CVPR2024
3D Gaussian을 Editing하는 방법에 관한 논문입니다. 물체를 지정해서 제거하거나, text로 사물을 추가하거나, text로 style을 변화시킵니다. 이는 특정영역에 대해 2D가 아닌 3D로 inpainting 한다고 볼 수 있습니다. A6000 GPU로 2-7분만에 변환이 가능합니다. 빠른 속도 때문에 Editor라는 표현이 어울리네요.
| Style 변경 |
Object 추가 |
| Object 제거 |
Object 제거 |
동작 원리를 파악해보겠습니다.
Overview
3D Gaussian Splatting모델(이전글), style변형 Target영역, style text가 입력으로 주어집니다.
GaussianEditor에서 style변형은 3D Gaussian Splatting를 진행하면서, 3D Gaussian들을 업데이드하면서 만들어지게 됩니다.
3D Gaussian들 원하는 style로 업데이트 위한, 핵심 알고리즘은 크게 2가지로 구성됩니다.
- Gaussian Semantic Tracing : 변환 과정에서 editing할 target을 추적합니다.
- Hierarchical Gaussian splatting (HGS) : styling은 Stable Diffusion Model의 2D inpaint를 활용하게 됩니다. 때문에 view마다 이미지가 약간씩 다르게 생성이 되는데, 이를 3D상에서 stable하게 만들고 원본의 3D Gaussian형태를 유지하게 만듭니다.
Problems
논문에서는 3D Object inpainting시, NeRF기법과 3DGS기법에 대해 구분해서 문제를 제기하고 있습니다.
NeRF로 3D를 Editing하는 경우, MLP를 사용하기 때문에, 구체적인 scene 영역을 직접적으로 수정하기가 어렵습니다. 그래서 inpainting하는 것과 scene composition이 복잡해지게 됩니다. 그리고 기존 기법들은 mask 영역 안으로 editing 범위를 제한한다는 문제점이 있습니다. NeRF기반 3D Editing 연구로는 Instruct-NeRF2NeRF, Ed-NeRF, Clip-NeRF, NeRF-ART, Dreameditor 등이 있었습니다.
3DGS로 3D를 Editing하는 경우, 이전 연구들에서는 Gaussian들을 선택하는 방법이 없습니다. 2D Stable Diffusion을 사용하여 inpainting하면 view마다 약간씩 다른 이미지가 생성되는데, (논문에서 random generative guidance라고 적힌 부분인데 많이 의역했습니다.) MLP를 사용해서 style정보가 어느정도 정제가 되는 NeRF와 달리, 3D GS에서는 style정보가 각 3D Gaussian으로 직접적으로 영향을 미치기 때문에, stable하게 update되지 않습니다. 또한 많은 갯수의 Gaussian이 동시에 업데이트 되게 되는데, 디테일한 디자인 요소들이 수렴하기 어렵게 만듭니다.
Diffusion-based Editing Guidance
2D diffusion을 3D로 확장하여 3D 편집에 적용하는 연구들은 크게 2가지 유형으로 분류 할 수 있습니다.
- 첫번째 유형은 Dreamfusion(이전글)의 SDS loss를 사용하는 방법입니다. 2D diffusion 모델의 denosing process에 latent로써 3D를 랜더링한 이미지와 condition(=text 등)을 넣었을 때, condition에 관한 이미지가 생성되도록 3D parameter를 업데이트하게 합니다. InstructPix2Pix, Progressive3D, Ed-NeRF, Dreamfusion, Vox-E, DreamEditor 이 있습니다.
- 두번째 유형은 style에 관한 multi view를 생성하고 3D parameter를 업데이트하는 방법입니다. Instruct NeRF2NeRF, DreamBooth3d, Control 4D 방법이 있습니다.
이러한 기법들은 condition을 따르도록 Loss가 설계가 되기 때문에, 이를 2D diffusion model 연구에서 gudiance라고 불립니다. 본 논문에서는 기존 text-to-3D 연구기법들의 gudiance method를 그대로 적용한다고 되어 있습니다. 3D 모델로 Rendering한 결과값과 condition(=text 등)을 입력으로 Diffusion model로 출력한 결과값이 다를 경우 차이가 커지도록 Loss가 설계됩니다. 논문에서는 이를 symbol로만 표현하고 있습니다.

D는 diffusion모델, Θ는 3D model parameters, p는 카메라 pose, e는 condition입니다.
Gaussian Semantic Tracing
3DGS를 구성하고 있는 5가지 parameter인 position(x), scaling(s), rotation quaternion(q), pacity(α), color(c) 에 mask parameter $m_{ij}$이 추가됩니다. $m_{ij}$ 은 i번째 gaussian point에 j번째 label을 의미합니다.
Gaussian에 Label을 지정하기 위한 단계는 다음과 같습니다.
1) 3DGS를 구성할 때 사용했던 이미지들 중에 일부 이미지를 선택합니다.
2) SAM(Segmentation Anything)으로 2D Image Segmentation하여 mask를 획득합니다.
3) 2D mask를 3D로 unprojection하여 3D Gaussian에 mapping합니다. 이 경우 하나의 Gaussian에 여러개의 label이 mapping이 되게 될텐데, inverse rendering방식을 사용해서 label에 대한 weight를 계산하여, average weight가 (수동으로 정한) 특정 점수(=Threshold)가 될 경우 해당 label로 분류합니다.
$$ w_{i}^{j} = \sum o_i(p) * T_{i}^{j}(p) * \mathcal{M}^{j}(p) $$
$w_{i}^{j}$는 i번째 gaussian에 j번째 label을 나타내는 weight이며, $o$는 opacity, $T$는 Transmittance, $\mathcal{M}$은mask label, $p$는 pixel을 의미합니다.
위 과정을 통해 3D공간상에서 특정 label로 Gaussian들을 선택 할 수 있게 됩니다.

다음으로 Style 변환 과정 중에 label을 tracing하게 됩니다.
Style 변환 과정 중에 3DGS의 Densification가 이뤄지게 되는데, clone gaussian과 split gaussain에서 하나의 gaussian이 2개로 바뀔 때, 같은 label값을 매기도록 설계됩니다.
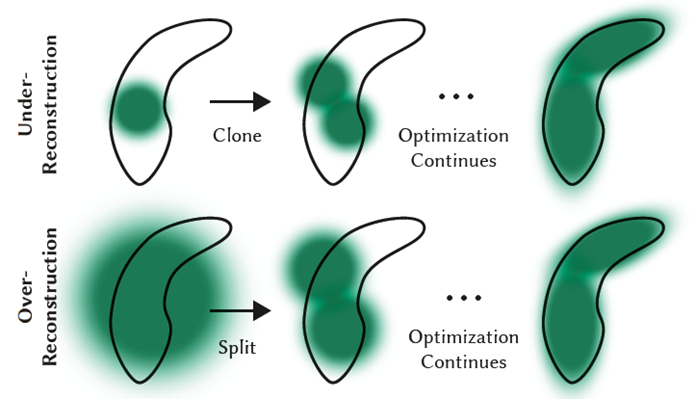
style 변형 과정이 진행되면, 지정한 mask 영역이 커지게 되는 것을 볼 수 있습니다.

Hierarchical Gaussian Splatting (HGS)
styling은 Stable Diffusion Model의 2D inpaint를 활용하게 됩니다. 때문에 view마다 이미지가 약간씩 다르게 생성이 되는데, 이를 3D상에서 stable하게 만들고 원본의 3D Gaussian형태를 유지하게 만듭니다.
Densification 마다 3D Gaussian parameter를 저장합니다. 이를 논문에서는 Anchor로 지칭하고 있습니다. 현재의 3D Gaussian parameter는 Anchor의 값과 멀어지지 않도록 아래 Loss로 정의합니다.

λ는 상수값에 해당하며, iteration이 진행되면 커지도록 설계하여, 최초 시점의 anchor값은 적은 영향력을 가지고, 최근 시점의 anchor값은 큰 영향력을 갖게 합니다. 이는 최초 Gaussian들의 특성을 유지하는 역할도 하고, view마다 다르게 styling되어 랜더링되는 이미지들로 3D Gaussian들을 stable하게 update 할 수 있게 만듭니다.
본 논문에서 최종적으로 사용하는 Loss는 앞부분에서 언급한 Diffusion-based Editing Guidance Loss와 anchor loss 두가지 입니다.

저자가 업로드한 영상에서 캡쳐한 이미지입니다.

학습 22초 경과한 모습이며, 각 view마다 광대 style의 이미지를 diffusion 모델로 생성한 후에, 3D Gaussian parameter가 업데이트 되고 있는 것을 볼 수 있습니다.

최종적으로 학습이 완료되었을 때의 모습입니다. 22초의 각 view마다의 광대 이미지보다 좀 더 짙은 것을 볼 수 있습니다. 시간이 경과하면서, style이미지도 변형되는 것으로 보입니다.
Object Removal
Gaussian Semantic Tracing을 했기 때문에, 단순히 Label된 Gaussian을 지우면 되지 않을까 생각 할 수 있는데, 그렇게 할 경우 경계부분에 artifact가 발생하게 됩니다.

때문에 target Gaussian들 주변에 근접한 gaussian들을 선택해서 지우는 과정이 필요하고, styling을 바꾸는데 사용한 inpainting기법으로, 경계부분을 매끄럽게 처리해줍니다. 구체적인 방법은 아래와 같습니다.
0) 하나의 view에서 제거할 object에 해당하는 pixel을 선택합니다. 해당 pixel에 대한 label을 가진 gaussian을 선택합니다.
1) KNN을 사용해서 제거할 Gaussian과 가까운 Gaussian들을 선택합니다. 경계영역들이 선택됩니다.
2) 해당 경계 영역을 여러 view로 projection합니다.
3) 경계 영역 mask를 늘입니다.
4) hole부분들을 수정합니다.
5) 경계영역을 refine합니다.
6) inpainting방법으로 제거합니다.
7) HGS(Hierarchical Gaussian Splatting)을 사용해서 3D Gaussian들을 update합니다.
아래는 저자가 업로드한 영상에서 캡쳐한 이미지들입니다.

좌상단 이미지에선, pixel단위로, object를 선택하는 것을 볼 수 있고,
0:46 이미지에선 해당 pixel에 대한 3D Gaussian들이 선택된 것을 볼 수 있씁니다. 삭제하는 과정중입니다.
2:32 이미지에선 3D Gaussian들이 사라지고, 테이블 바닥의 경계 영역에 gaussin들이 artifact로 남아 있는것을 볼 수 있습니다.
우하단 이미지는, 최종 제거된 이미지이며 경계 부분의 artifact가 많이 사라진 것을 볼 수 있습니다. 실제 영상에선 artifact가 눈에 띄게 보이긴 합니다.
Object Incorporation
특정 영역을 선택하여, 새로운 contents를 생성하는 application에 대해 소개합니다.
1) 영역을 box로 선택한 후에, Stable Siffusion XL을 사용해서 prompt에 대한 이미지를 생성합니다.

2) forground object를 segmentation합니다.

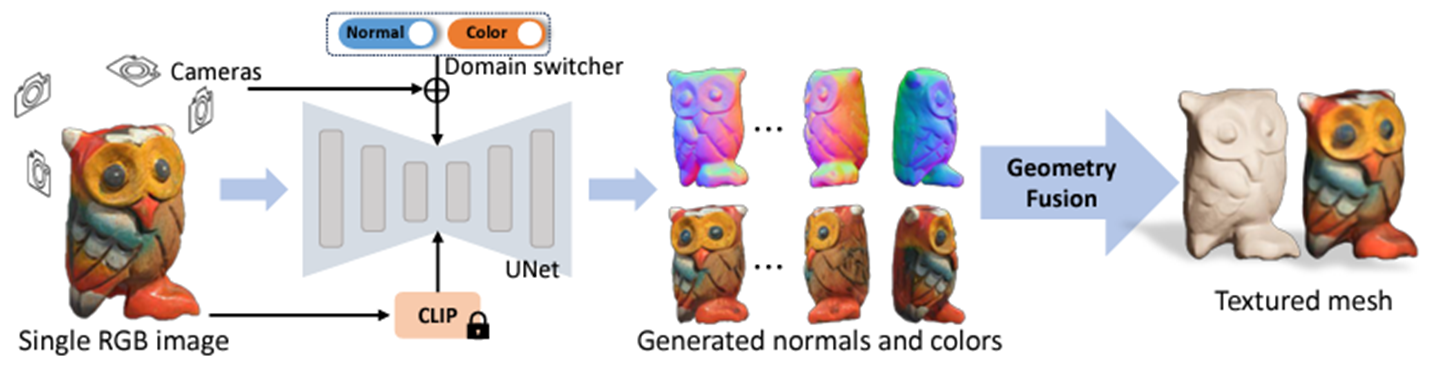
3) image를 Wonder3D를 사용해서 3D mesh로 만듭니다. 아래는 Wonder3D에서 갖고 온 architecture입니다. 하나의 이미지를 입력으로 multi view 이미지를 생성한 후에, normal값을 기반으로 Textured mesh를 만드는 연구입니다.
4) HGS를 사용해서 mesh를 3D Gaussian으로 만듭니다. 오른쪽에 보면, segmented된 곰인형이 view point로 있는 것을 볼 수 있습니다.

5) DPT(Vision Transformers for dense prediction)을 사용해서 depth를 추정합니다.

6) 배경과 생성된 object를 align해서 배치해줍니다.

Implementation Details
실험에서 사용된 카메라 포즈의 갯수는 24~96개입니다.
Styling변형을위해 3DGS 학습은 500~1000 step이며, 전체과정은 5~10분 정도 소요되었습니다. A6000기준입니다.
Wonder3D로 3D mesh 생성은 3분정도 소요되었으며, mesh를 gaussian으로 refine시에는 2분이 소요되었다고 합니다.
Quantitative Comparisons
Instruct-NeRF2NeRF는 30분이 소요되었지만, GaussianEditor는 5~10분 소요되었습니다.
실제 사람의 선호를 테스트하는 User Study와, view마다의 consistency를 측정하는 CLIP Directional Similarity 지표에서 모두 높은 성능을 보였습니다.

Qualitative Comparisons
저자 project page 에선 Web에서 Modeling한 결과를 볼 수 있습니다. 아래는 논문에 언급된 결과물입니다.

Ablation Study
Semantic Tracing이 없을 경우, scene 전체로 스타일이 바뀌는 것을 볼 수 있었습니다.

HGS가 없을 경우, scene 전체에 걸쳐 gaussian들이 spread되고 densify되는 경향을 보였고, densification 제어가 안되었으며 image blurring이 발생했다고 합니다.
Closing..
변형시간이 논문에 언급된 대로 짧고 퀄리티가 높다면, 실용적인 application이 나올 수 있을 것 같네요. 결과물을 보면 cherry picking을 한게 좀 보이긴 합니다. 해당 코드가 오픈소스로 되어있어서 시간이 된다면 한번 구동해보고 싶네요. 3D Gaussian을 선택하고 제어한다는 관점에서 흥미로운 논문이었습니다.
'3D-GS' 카테고리의 다른 글
| [논문 리뷰] PhysGaussian (CVPR 2024) : 물리 기반 변형 (3) | 2024.07.13 |
|---|---|
| [논문 리뷰] VastGaussian (CVPR 2024) : Large Scene (0) | 2024.06.17 |
| [논문 리뷰] GaussianPro (arXiv2024) : surface 퀄리티 향상 (2) | 2024.06.07 |
| [논문 리뷰] MVSGaussian (arXiv 2024) : Generalizable 모델 (0) | 2024.05.27 |
| [논문 리뷰] MVControl (arXiv 2024) : Image+Text to 3D (0) | 2024.05.22 |




댓글