Gaussian Splatting(GS) 분야에서 굉장한 논문이 하나 나왔네요. Camera Pose정보가 없는 이미지들로 37초만에 Scene을 학습합니다!
Novel-View Synthsis분야에서 NoPe-NeRF(CVPR2023, 이전글), Colmap-free 3DGS(CVPR2024, youtube)연구들에서 Unknown Camera Pose로부터 scene을 학습하는 방법에 대해 다뤘습니다. 12개의 view로 NoPe-NeRF는 학습에 95분이 소요되었고, Colmap-free 3DGS는 60초가 소요되었습니다. InstantSplat에선 무려 37초를 달성합니다! (Colmap-free 3DGS논문 내에서는 더 많은 수로 학습하였기에, Colmap-free는 2시간, NoPe-NeRF는 20시간으로 되어 있습니다.)
해당 기법을 간단히 요약하자면, point기반으로 representation하는 3D Gaussian Splatting(이전글)연구와 카메라 pose가 없는이미지들을 global하게 alignment하는 DUTs3R(이전글)연구를 조합하였습니다. Pose를 추정하면서 3D Gaussian representation을 동시에 수행하게 됩니다.
관련 연구들을 먼저보고 아래에서 자세히 설명해보겠습니다.
Related Works
대부분의 NeRF와 3DGS알고리즘을 수행하기 위해서는 COLMAP과 같은 SfM(Structure from Motion)알고리즘을 사용해서 camera intrinsic, camera extrinsic parameter 계산이 선행적으로 필요로 합니다.
COLMAP은 몇가지 단점이 있습니다.
- COLMAP은 입력 이미지수가 적은(sparse) 경우에 정확한 camera parameter를 추출하지 못합니다.
- COLMAP은 연산 시간이 오래 소요됩니다. COLMAP사이트를 보면, 수십장의 이미지는 a few minutes, 수백장의 이미지는 few hours, 수천장의 이미지는 days or weeks로 적혀있습니다.
그 외, Novel View Synthesis관점에서, Sparse-view 연구들은 실용적이지 못한 시나리오를 갖고 있습니다. COLMAP으로 많은 수의 이미지들의 camera parameter를 획득한 후에 적은 수의 이미지들의 camera parameter를 사용하는 방식을 쓰기 때문입니다.
- 대표적으로 Sparse한 이미지를 고려한 연구들로 Reg-NeRF, Sparse-NeRF, Free-NeRF이 있습니다.
- 모델의 초기값을 COLMAP을 사용하는 방법론으로 Depth-NeRF와 3D Gaussian Splatting이 있습니다.
- Monocular depth estimation를 함께 활용한 방법론으로 SparseNeRF, SparseGS, FGGS가 있습니다.
Image matching를 함께 활용한 방법론으로 CorresNeRF, Sparf 이 있습니다.
COLMAP 의존성을 벗어나기 위해 NoPe-NeRF와 Colamp-free 3DGS연구가 제안되었지만, 실제로 카메라 intrinsic가 주어진다는 전제가 깔려있기에 이 또한 실용적이지 못하다고 합니다.
3D Gaussian Splatting

이전글을 토대로 필요한 부분만 정리해보겠습니다.
- 여러개의 이미지가 주어지면, COLMAP을 통해 이미지에 대한 카메라 intrinsic/extrinsic parameter 와 point cloud를 만듭니다. 해당 point cloud로 3D Gaussian의 위치를 초기화 합니다.
- mean(=position), covariance(=scale과 rotation), color, opacity로 이루어진 3D Gaussian들을 2D Plane으로 projection(=Tile Rasterizer)하고 pixel과 주어진 이미지들의 pixel들의 차이로 최적화 합니다.
- 매 iteration마다 3D Gaussian parameter를 업데이트하고, 100 iteration마다 Densification(=Clone/Split/Remove Gaussian)을 수행하고, 3000 iteration마다 Opacity를 Reset(=alpha값을 0으로 초기화)합니다.
- iteration수에 따라 7K iteration모델, 30K iteration모델로 구분하여 성능을 평가하였으며, 7K는 빠른 속도, 30K는 높은 퀄리티를 특징으로 합니다.
DUSt3R
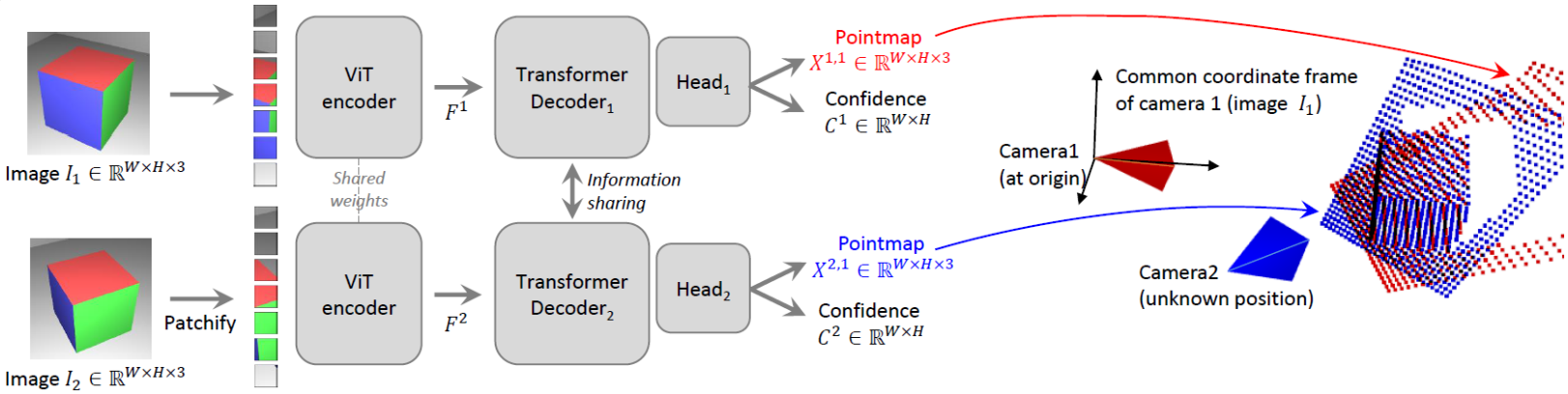
동일하게 이전글을 토대로 필요한 부분만 정리했습니다.
- 이미지 2장-3D point묶음으로 8.2M개의 데이터를 학습하여, 2개 이미지를 입력으로 각각의 pointmap, confidence score를 출력하는 네트워크를 학습합니다. 이 네트워크를 DUSt3R모델이라고 합니다.
- Camera 좌표계에서 원점에서 1만큼 떨어진 이미지 plane와 예측한 Pointmap(=P)을 projection(=x,y값을 z값으로 나누고 focal length(=f)를 곱하여 계산)한 값이 최소화되도록 하는 아래 수식을 통해, intrinsic parameter인 focal length값을 찾습니다.
$$ f^* = \arg \min_f \sum_{i=0}^{W} \sum_{j=0}^{H} O_{i,j} \left\| (i', j') - f \frac{(P_{i,j,0}, P_{i,j,1})}{P_{i,j,2}} \right\| $$ - 3장 이상의 이미지가 주어질 경우, 이미지들에 대해 Global Alignment를 수행합니다. 인접한 이미지 쌍을 Graph관계로 정의하고, 모든 쌍의 pointmap, confidence score를 계산한 후에, World 좌표계에서의 3D point좌표(=P), 각 이미지의 Transformation Matrix(=T), scaling factor(=σ)을 아래 최적화 공식을 통해 찾습니다.
$$ \hat{P}^* = \arg \min_{P, T, \sigma} \sum_{e \in E} \sum_{v \in V} \sum_{i=1}^{HW} O_{v,e} \left\| \hat{P}_v^i - \sigma_e T_e P_v^i \right\| $$
InstantSplat 알고리즘

Global Alginments
DUSt3R 모델을 바탕으로 intrinsic parameter인 focal length를 찾고, Global Alignments를 먼저 수행합니다.
3D Gaussian Initializations
3D GS에서는 3D Gaussian의 초기 위치값으로 SfM points로 사용했지만, InstantSplat에서는 DUSt3R의 global alginment된 3D points를 사용합니다. 이 방법은 2가지 이점이 있습니다.
- training view수가 sparse 할 때(=진동수의 2배에 해당하는 빈도로 일정 간격으로 샘플링하면 원래 신호로 복원할 수 있다는 나이퀴스트 샘플링 비율이 적은 상황일 때)도, 3D points를 획득 할 수 있습니다.
- 3DGS에서는 3D Gaussian의 stability와 quality를 위해서 Densification기법을 사용했지만, 초기화한 3D points값이 정확하기 때문에, 3D GS의 핵심이라고 볼 수 있는 Densification, Opacity Reset을 사용하지 않습니다. 이 덕분에 적은 수의 step인 1,000 iteration만으로 충분한 학습이 가능하게 됩니다. 3DGS에서는 7K, 30K iteration모델로 평가하였지만, InstantSplat에서는 공통적으로 1K iteration모델로 평가합니다.
Jointly Optimizing Poses and Attributes
DUSt3R은 2개 이미지에 특화된 모델입니다. 때문에 two-view가 아닌 multi-view에 대해 global alignments할 때 일관되지 않은 scale이 문제가 됩니다. 이는 predicted points와 confidence map이 부정확할 때 발생하는 ambiguity 때문이며, 다양한 illumination(=조명)이나 손으로 촬영할 때 생기는 motion blur까지 모두 커버 할 수 없기 때문입니다.
그래서 InstantSplat 저자는 representive model인 3D Gaussian을 최적화하면서 3D Gaussians의 특성에 따라 카메라 parameter를 동시에 최적화하는 방법을 사용하게 됩니다. 아래는 이 때 사용되는 최적화 공식입니다.
$$ S^*, T^* = \arg \min_{S,T} \sum_{v \in N} \sum_{i=1}^{HW} \left\| \tilde{C}_v^i (S, T) - C_v^i (S, T) \right\| + \lambda \cdot \left\| T - T_0 \right\|. $$
$ S $ 는 3D Gaussian
$ T $ 는 camera extrinsic, $ T0 $ 는 DUSt3R의 global alignment부터 계산한 initial extrinsics
$ C_v^i $ 는 rendering 함수. $\tilde{C}$는 예측 pxiel값, $C는 GT pixel값
$ T-T0 $ 는 초기 DUSt3R의 camera extrinsic 값을 과도하게 벗어나지 않도록 constraint를 주는 부분입니다.
$ λ $ 는 비율 조절 상수
Algining Camera Poses on Test Views
기존에 방법론들은 text view에 대한 정확한 카메라 pose값을 안다는 전제가 되어 있습니다. 하지만 InstantSplat에서는 카메라 포즈는 추정한 값이기 때문에, 마이너한 camera pose오차가 발생하게 됩니다.
때문에 test view에 대해 랜더링하기 전에 alignment가 필요로 하게 되며, training view로 학습된 3DGS모델은 frozen하고 test view에 대해 camera pose를 optimization하는 과정을 거쳤습니다. 이는 NeRFmm 방식을 차용한 부분이라고 하며, 이를 통해 좀더 정밀한 alignment와 rendering을 할 수 있었다고 합니다.
Experiments
Tanks and Temples 데이터셋(참고글)의 5가지 scene(=Barn,Family, Francies, Horse, Ignatius)과 MVImgNet 데이터셋의 7가지 scene(=Car, Suv, ... , Table) 대해서 평가하였습니다. Sparse-view setting을 위해 기존 scene마다 120~200개 정도의 이미지가 있었는데 그중에서 12개의 view를 균일하게 선택했다고 합니다. 또한 당연하게도 학습시 Camera Pose를 주지 않습니다. 그리고 A100 GPU을 사용했다고 합니다.
Rendering Evaluation


이미지 퀄리티에 대해서는 PSNR / SSIM / LPIPS(이전글)로 평가하였습니다. CF-3DGS는 앞에서 언급한 Colmap-Free 3D Gaussian Splatting입니다. NeRFmm은 조금전에 살짝 언급한 NeRF와 camera parameter를 동시에 optimization하는 연구입니다. 퀄리티관점에서 InstantSplat이 모든 Scene에 대해 높은 성능을 가짐을 볼 수 있습니다.

Camera Pose Evaluation


카메라 포즈에 관련해서는 ATE(Absolute Trajectory Error), RPE(Relative Pose Error) (이전글)로 평가하였습니다. 여기서도 압도적으로 높은 성능을 보이고 있습니다.

Ablation Studies
Effect of Averaging Focal Length
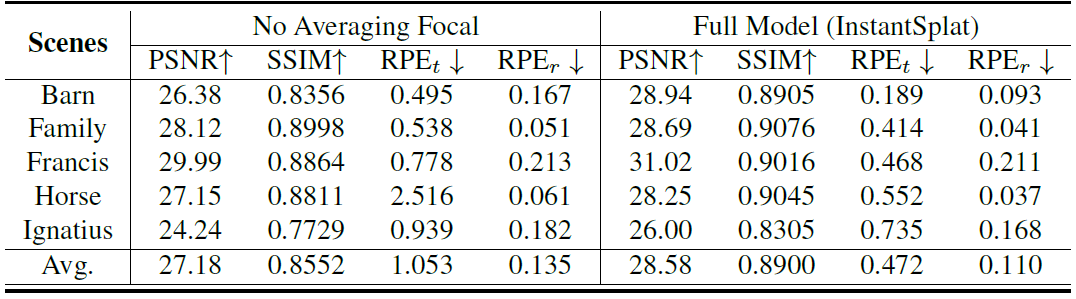
부정확한 focal length값은 전체적인 성능에 영향을 미치게됩니다. focal length를 최적화 하지 않는 경우 많은 성능저하가 생기는 것을 볼 수 있습니다.
Effect of Joint Optimization
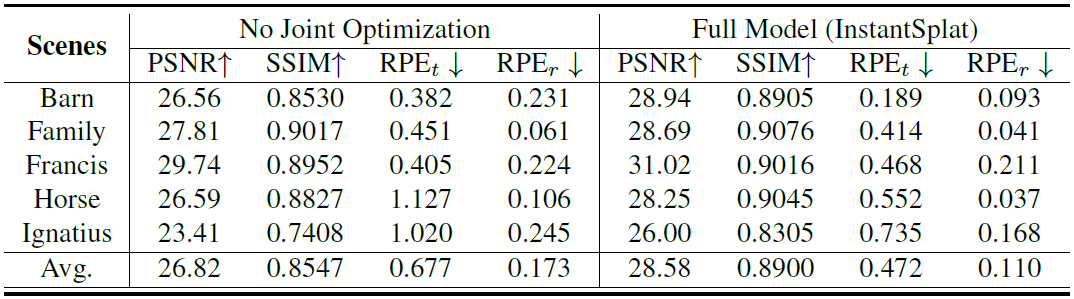
초기 global alignment값은 부정확합니다. 위에서 설명하였듯이, artifact가 존재 할 경우 각 view에 대한 scale을 값을 정확한 값을 찾을 수 없어 정확한 extrinsic값을 알 수 없습니다. 이를 해결하기 위해, 카메라 Pose와 3D gaussian을 동시에 최적화하는 Joint Optimzation 기법을 사용했었고, 위 표는 이 기법을 적용하지 않았을 경우와 비교하였습니다. 확실히 성능 차이가 발생함을 볼 수 있습니다.
Effect of View Number and Efficiency Analysis

학습 이미지수에 따른 퀄리티를 비교하는 표입니다. 모든 Case에서 InstnatSplat이 높은 퀄리티를 보이는 것을 볼 수 있습니다. 특히 논문에서 12view 학습에 대한 속도를 언급하였는데, 초기 Global Alignment는 20.6초 소요되었고, 3D Gaussian을 1000 iteration 학습하는데는 16.67초가 소요되었다고 합니다.
Closing..
논문 리뷰를 마쳤지만, 너무 성능이 좋으니 궁금증이 많이 생기는 논문입니다. DUSt3R의 결과물이 dense한 point cloud형태로 나올텐데, point들이 너무 많지 않은가? 초기 point들이 너무 몰려있지 않은가? 3DGS의 Densification없이도 가능한가? 1,000 iteration으로 정말로 학습이 가능한가? 100개 training view가 주어지면 수행 시간은? Pose가 주어진 3D-GS와 성능와 퀄리티를 비교한다면 어떤가? Test Camera Pose 추정이 거의 정답에 가까워야 하는데 그게 정말 가능한가? 에 대한 답을 알고 싶네요. 12 view이하로 제한한 것으로 봐선, view가 많아질 경우 최적화하는데 시간이 exponential하게 오래 소요되거나 정확하지 않을 것 같다는 생각도 듭니다.
'3D-GS' 카테고리의 다른 글
| [논문 리뷰] Style Gaussian (arXiv 2024) : 3DGS 스타일 변경 (0) | 2024.05.20 |
|---|---|
| [논문 리뷰] RadSplat (arXiv2024) : lightweight & 랜더링 속도 향상 (0) | 2024.04.30 |
| [논문 리뷰] GPS-Gaussian (CVPR 2024) : Generalizable 모델 (1) | 2024.03.17 |
| [정리] NeRF & 3D Gaussian Splatting 연구 주제 분류 (2) | 2024.02.08 |
| [논문 리뷰] TRIPS (arXiv2024) : 3D GS 퀄리티 향상 (0) | 2024.02.05 |




댓글