일반적인 NeRF/3DGS계열 논문들은 Scene마다 Optimization이 필수적입니다. GPS-Gaussian에서는 Scene별 Optimization없이 8장의 이미지로 25FPS로 Novel-view Synthesis 연구에 대해 다룹니다. 다만 모든 Scene에 대해서 다루는게 아니라 아래 그림과 같이 고정된 카메라가 주어지고 사람이 중심에 위치한다는 제약을 두고 있습니다. (영상에서 16이라고 표현되어 있는데, 저자가 테스트를 위해 8개가 아닌 16개로 촬영한 것 입니다.)
Overview

사람을 구성하는 3D Gaussian parameter(3DGS 이전글)들을 찾는 것을 목표로 합니다.
- 주어진 novel camera pose와 인접한 2개 카메라를 선택해서, 해당 이미지에 대한 depth를 추정합니다. pixel마다 3D Gaussian을 만들게 되고, 획득한 depth로 해당 3D Gaussian의 position을 결정합니다.
- depth feature와 color feature를 MLP에 넣어 해당 3D Gaussian의 rotation, scale, opacity를 결정합니다.
View Selection
Overview의 상단왼쪽 이미지를 보면 45도 간격으로 8개의 카메라가 배치되어 있는 것을 볼 수 있습니다. 각 카메라 위치와 중심점(사람위치) 위치로 방향벡터 값을 계산해두고, Test시 novel view와 중심점에 대한 방향벡터를 구한 후, 벡터간의 내적을 구하여, 가장 2개 카메라 위치를 선택합니다.
학습시에는 Loss를 계산하기 위해 8개 중에 하나의 이미지를 GT로 선택 한 후 가장 가까운 좌/우 45도 각도에 있는 2개의 이미지를 입력 데이터로 사용합니다.
Depth Estimation
(2장의 이미지가 주어졌을 때 pixel당 변화량을 추정하는) optical-flow estimation 알고리즘의 용도를 바꾸어 depth estimation을 수행하고 있습니다. 이게 가능한 이유는 여기에선 2개 카메라간의 상대적인 rotation정보, translation정보가 주어지기 때문입니다. 추가적으로 수직방향의 변화량도 없도록 상황을 제약해두었습니다. (그림 출처 : link)

왼쪽 view에서 나무의 꼭대기점은 오른쪽 view에서의 변화량으로 정의 할 수 있습니다. 이 pixel 변화량을 disparity라 부르고 아래 수식으로 정의됩니다.

이 disparity를 계산하면 해당 pixel의 절대적인 depth를 계산 할 수 있게 됩니다. (그림 출처 : link)

이미지 한장으로는 각 pixel의 depth를 알 수 없지만, 다른 각도에서 촬영한 이미지의 촬영 위치와 각 pixel의 변화량을 알 수 있다면 가능한 부분입니다. 본 논문에서는 pixel마다 disparity 계산시, optical-flow estimation 알고리즘 중에 하나인 RAFT를 사용하고 있습니다(RAFT 설명글 : link). 본 논문의 Depth Estimation Module부분은 RAFT network와 동일하게 가져가는 것을 볼 수 있습니다.

Depth Estimation파트를 통해 Depth값은 각 pixel마다 3D Gaussian의 position으로 사용됩니다. 입력 이미지 pixel로는 3D Gaussian의 color값으로 획득합니다.
Pixel-wise Gaussian Parameter Prediction
Pixel마다 Gaussian의 rotation, scale, opacity를 획득하는 부분입니다. UNet의 Output으로 값을 획득합니다.
위 Network 이미지를 보면, Gaussian Parameter Prediction Module의 입력은 D(=depth map)으로 쓰이고, RGB를 encoding할 때 중간 layer의 feature를 UNet의 입력으로 사용하는 것을 볼 수 있습니다. 결과적으로 RGB와 Depth의 feature정보를 사용해서 backbone을 구성하게 됩니다.
그리고 rotation, scale, opacity를 각각 출력하기 위해, 각 2 layer MLP로 구성된 head를 붙이는 것을 볼 수 있습니다.

아래는 논문에 언급된 수식입니다.

이렇게 pixel마다 3D Gaussian parameter를 획득 할 수 있습니다. 다음으로 어떻게 학습하는지에 대해 다루겠습니다.
Joint Training
Depth Estimation과 Pixel-wise Gaussian Parameters Prediction 네트워크는 joint되어 동시에 업데이트 되어집니다. 논문에서는 크게 pixel기반의 render loss와 depth기반의 disparity loss로 나뉘어집니다.
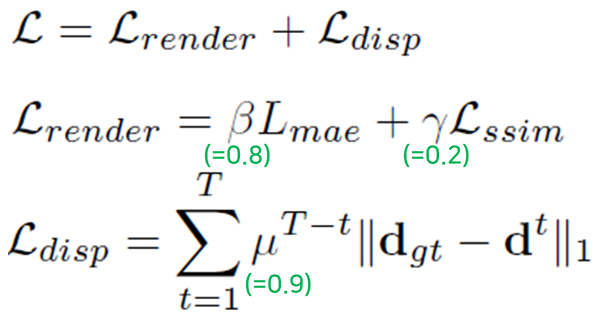
render loss는 L1 loss(=mae)와 SSIM loss로 구성되어 있습니다. disparity loss는 depth에 대한 정답값이 따로 주어지는 것으로 보여집니다. 초록색으로 표시한 부분은 실험부분에 있는 수치를 참조해서 제가 따로 적어넣은 부분입니다.
Experiments
실험 데이터는 아래와 같이 구성됩니다. Twindom, THuman2.0은 8개의 카메라로 구성되고, real-world는 저자가 촬영한 이미지로써 16개의 카메라로 구성됩니다.

Generalizable 모델에 대한 성능입니다. (각 지표의미는 PSNR/SSIM/LPIPS 이전글 참조 바랍니다.)

물론 3D-GS는 Generalizable모델이 아니며, scene마다 optimization이 필요하기 때문에 FPS를 /로 표현한 것으로 보입니다. 모두 RTX3090에서 측정되었으며, Training 시간은 약 15시간입니다. 기존 연구대비 높은 Quality를 보이고 있습니다.

Ablation Studies
카메라를 8개가 아닌 6개로 바꾸었을 경우 실험결과 입니다. 퀄리티가 약간씩은 떨어지지만, 여전히 다른 연구들대비 높은 퀄리티를 보이는 것을 볼 수 있습니다.

Joint Training을 제거하였을 경우, depth encoding feature를 사용하지 않았을 경우 성능입니다. Joint Training을 하지 않았을 경우 성능 하락이 큰 것을 볼 수 있습니다. 가장 오른쪽 열을 보면 depth값에 대한 성능평가도 같이 한 것을 볼 수 있습니다.

Closing..
연구 관점에서 per-scene optimization이 없다는 부분이 흥미로웠습니다. 서비스 관점에서는 쇼핑몰이나 영화 촬영시에 도움을 주는 Application으로 만들어지면 좋겠다는 생각이 드네요. AI모델을 그대로 서비스하기가 어렵기 때문에, 여러 제약을 가하게 되는데, 그 제약들을 잘 설정한 것 같습니다.
'3D-GS' 카테고리의 다른 글
| [논문 리뷰] RadSplat (arXiv2024) : lightweight & 랜더링 속도 향상 (0) | 2024.04.30 |
|---|---|
| [논문 리뷰] InstantSplat (arXiv 2024) : Pose-free GS (2) | 2024.04.24 |
| [정리] NeRF & 3D Gaussian Splatting 연구 주제 분류 (2) | 2024.02.08 |
| [논문 리뷰] TRIPS (arXiv2024) : 3D GS 퀄리티 향상 (0) | 2024.02.05 |
| [논문 리뷰] DISTWAR (arXiv2023) : 3D-GS 학습 속도 개선 (3) | 2024.01.27 |




댓글