NeRF-Art: Text-Driven Neural Radiance Fields Stylization, Can Wang, arxiv2022
저는 2가지 관점에서 흥미로웠습니다.
1) NeRF로 생성한 Scene의 Style을 높은 퀄리티로 변형 할 수 있다는 점
2) 요즘 Text to Image가 대세인데, NeRF분야에서도 Text입력으로 Style을 변형했다라는 점
입니다.
논문 저자가 공유한 연구 결과입니다.
상당히 퀄리티가 높습니다.
전체적인 구조와 배경지식 먼저 설명드리고, 핵심 알고리즘, 알고리즘 설계 근거 순대로, 내용 깊이 별로 나눠 설명 드리겠습니다. 원하는 깊이까지 선택적으로 읽으시면 됩니다.
Overview

전체적인 구조입니다. 기존 NeRF모델을 완전히 학습(Reconstruction 파트)시킨 후, Stylization Network(Fsty)를 한번 더 추가로 학습(Stylization 파트)시킵니다.
Reconstruction파트는, 기존 NeRF모델 학습 방법(이전 포스트)을 그대로 사용합니다.
Stylization 파트에서는, 아래 5가지 값을 사용해서 Loss를 계산합니다.
- Reconstruction 결과 이미지 : Isrc
- Reconstruction 결과 이미지에 대한 Text : Tsrc
- Stylization 결과 이미지 : Itgt
- Stylization 결과 이미지에 대한 정답 Text : Ttgt
- Stylization 결과 이미지에 대한 오답 Text : Tneg
Image-Text관계모델인 CLIP과 위의 5가지 값들로 4가지 Loss를 만들어서, Contrastive Learning을 통해 Stylization Network인 Fsty를 학습하게 됩니다.
Background
CLIP모델에 대해서 별도의 글로 정리해두었습니다. CLIP 설명 참조 바랍니다.
NeRF-Art에서는 이렇게 Text Encoder, Image Encoder가 학습된 pretrained된 CLIP모델을 알고리즘에 활용하였습니다.
Algorithm
알고리즘의 시작은 NeRF로 1개 Scene을 생성한 후 부터 입니다. NeRF에 대한 설명은 NeRF 이전글 참조 바랍니다. NeRF-Art에서는 이 부분을 수식적으로 설명하고 있으며, NeRF와 동일한 수식임을 알 수 있습니다.

아래는 Overview에서 언급했던 전체 구조입니다. Reconstruction부분은 NeRF와 동일합니다. x는 ray 위의 3D 좌표, v는 view direction, σ는 view direction, c는 radiance입니다.
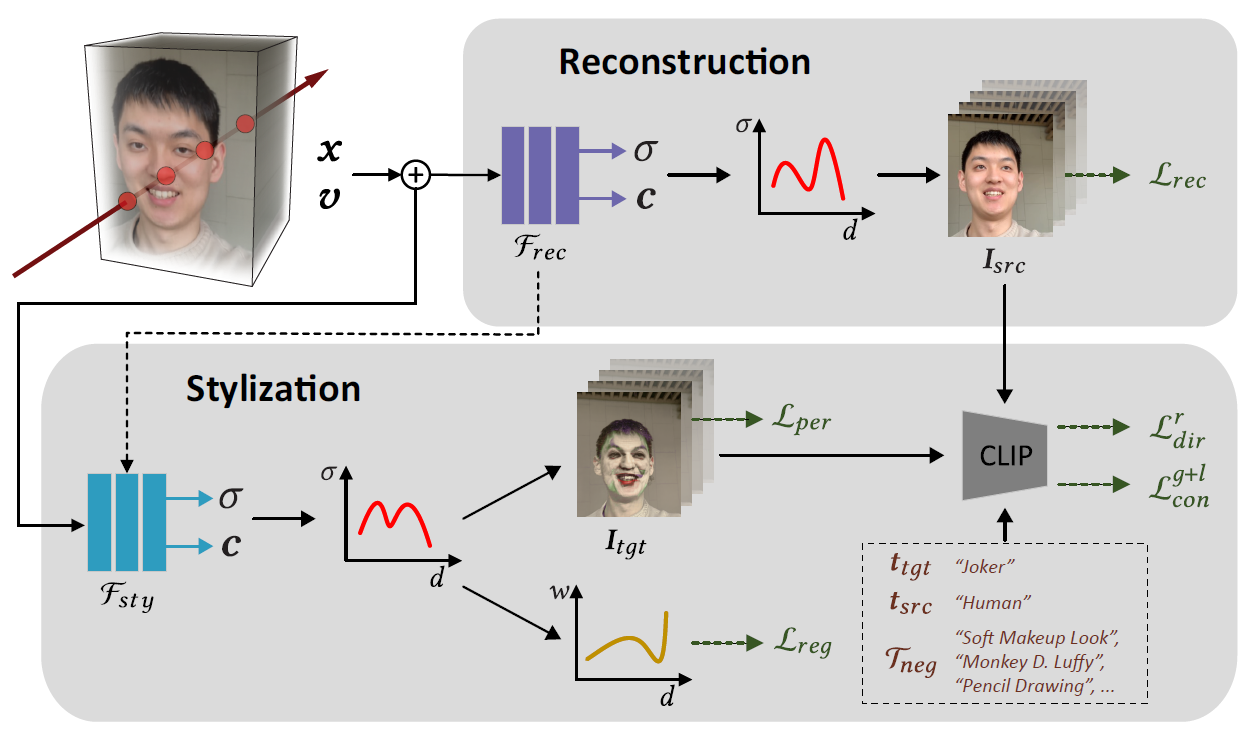
Stylization과정을 통해, Fsty 네트워크는 styling된 이미지를 만들도록 학습하게 됩니다.
Fsty는 Frec의 weight값으로 초기화됩니다. Fsty는 전체 Layer를 새로 학습 시키는 fine-tuning을 하게됩니다.
Fsty는 아래 4가지 Loss로 학습됩니다.

좌측부터 순서대로 나열하면 relative directional loss / global-local contrastive loss / regularization loss / perceptual loss 이며, 하나씩 살펴보겠습니다.
첫번째 두번째 Loss는 CLIP을 통해 계산됩니다.
Relative Directional Loss
CLIP의 입력값을 다시 보면서 설명을 덧붙여 보겠습니다.
- Reconstruction 결과 이미지 : Isrc -> Frec(=NeRF) 결과로써, 고정값
- Reconstruction 결과 이미지에 대한 Text : Tsrc -> "Human" 이라는 Text로써, 고정값
- Stylization 결과 이미지 : Itgt -> Fsty를 통해 생성될 변화값
- Stylization 결과 이미지에 대한 정답 Text : Ttgt -> Query Text로써, 고정값
- Stylization 결과 이미지에 대한 오답 Text : Tneg -> Query Text로써, 무작위값
Fsty를 학습시킬 때, 오답Text는 무작위로 선택되어지고, Stylization 결과 이미지를 제외하고 모두 고정된 값을 사용하게 됩니다. 위의 입력값들은 모두 이미 학습되어 있는 CLIP Image Encoder(εi)와 Text Encoder(εt)를 사용해서, Embedded 공간으로 변형됩니다. 그리고 Embedded 공간에서 Loss를 계산하게 됩니다.
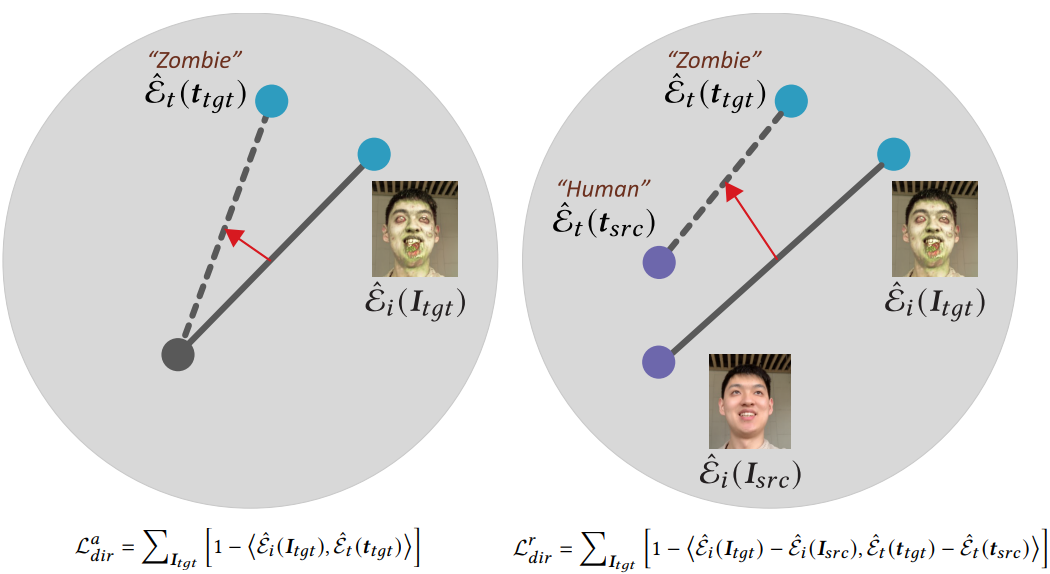
왼쪽은 CLIP(2021년)으로 Stylization을 시도한 선행 연구인 ClipNeRF(2021년)에서 사용한 Directional CLIP Loss이고, 오른쪽 식이 NeRF-Art loss입니다. <·,·> 는 cosine similiarity입니다.ClipNeRF에서는 Stylization 결과 이미지와 해당 Text간의 Cosine Similarity가 높아지도록 학습했습니다. StyleGAN-NADA(2021년)연구에서는 위와 같은 Global Loss를 사용할 경우, Generator가 다양한 이미지를 만들어내지 못하고 비슷한 이미지가 계속 생성되는 mode-collapse가 쉽게 될 수 있어, 다양한 스타일을 생성하는데 문제가 될 수 있다고 밝혔습니다.
이를 개선하기 위해, Embedded 공간 내에서 Reconstruction Text에서 Stylization Text로 Trajectory(경로)로 부터 guide하여 Reconstruction결과 이미지에서 Stylization 결과 이미지로 Transfer하는 Loss를 설계하였다고 합니다. 제 의견을 넣어서 좀 풀어서 쓰자면, 'Reconstruction Text에서 Stylization Text로 이동하는 Vector'와 'Reconstruction 이미지에서 Stylization 이미지로 이동하는 Vector'의 Cosine Similarity가 높아지도록 Loss가 설계되었습니다.
Global-Local Contrastive Loss

위 Relative Directional Loss는 Stylization Strength(스타일링 강도)를 적절히 유지하는 것이 어려웠다고 합니다. 이를 해결하기 위해서 Stylization Strength를 조절하는 Contrastive Learning 기법이 사용됩니다. 다음 설명을 이해하기 위해서는 해당 블로그 글 앞부분 Background 에서 소개한 Contrastive Learning 부분을 다시 한번 읽고오시길 바랍니다.
위 그림에 수식을 한줄씩 설명하겠습니다. [#]는 제가 설명을 위해 붙은 번호입니다.
[1] Global-Local Contrastive Loss는 Global Contrastive Loss, Local Constrastive Loss로 구분됩니다.
[2] 둘다 Contrastive Loss 중 (N+1)-Tuplet Loss를 기본 구조로 가집니다. τ(타우)는 0.07 상수값입니다.
[3] Global Contrastive Loss는
- query anchor(v)를 stylization 결과 이미지,
- postive sample(v+)을 Stylization 결과 이미지에 대한 정답 텍스트,
- negative sample(v-)를 오답 텍스트로 셋팅한 후
- 수식 [2]로 Loss를 계산 합니다.
- 이 Loss조차도 특정 부분에서 과도한 Stylization이 발생하고 불충분한 Stylization이 발생했습니다. 그래서 부분적으린 성능을 향상시키기 위해 시도한 것이 Local Contrastive Loss입니다.
[4] Local Contrastive Loss는 Stylization 결과 이미지를 random으로 patch를 조각내어 query anchor(v)로 구성합니다. v-, v+는 동일 합니다. 이 Loss는 PatchNCE Loss를 참고하였다고 합니다.
Regularization Loss
위의 2개 Loss로 Stylization을 하면 density가 수정되면서 camera가까이에서 cloud-like semi-transparent artifact가 발생하고 geometry noise가 발생 될 수도 있다고 합니다. 이 현상을 해결하기 위해서, weight regularization loss가 추가 되었습니다. geometric noise를 줄이고, Isrc(Reconstruction 결과 이미지)의 형상과 비슷하게 만들려고 하였습니다. mip-NeRF 360의 distortion loss와 유사하게 설계하였습니다. Loss의 Term을 이해하기 위해, 위에서 언급했던 NeRF수식을 다시 들고 왔습니다.

Stylization 결과 이미지(Itgt)의 모든 픽셀에 대한, 모든 ray r에 대한, 모든 k개 sampled point에 대한 summation식으로 구성됩니다. w는 ray위에 샘플링된 점의 앞뒤 간격만큼을 weight로 가지고 있는 volume density값입니다. mip-NeRF 360에서는 distance를 optimization했었지만, scattered large weight를 가진 sampled point 쌍에 대해 penalize했다고 합니다. 제 의견을 넣어 다르게 설명하자면, 모든 sampling point의 volume density가 너무 커지면 안되도록 설계한 것으로 보입니다.
Perceptual Loss
Isrc(Reconstruction 결과 이미지)와 Itgt(Stylization 결과 이미지) 가 비슷한 형상을 가질 수 있도록 pre-defined VGG를 통과시켜 feature의 차이 만큼을 Loss로 두었습니다. LPIPS를 Loss로 두었다고 보면 될 것 같습니다.

이상으로 4가지 Loss를 다뤄봤습니다.
Training
모든 ray에 대해 stylization 학습하면 memory 문제가 발생한다고 합니다. 그래서 coarse image 또는 patch를 얻기 위해 sparse ray를 샘플링하거나, low resolution으로 그린 후 upsampling하는 방법을 고려하였지만, coarse rendering or patchs는 style detail과 semantic 구조를 잃는다고 합니다.
그래서 논문에서는 forward 과정에서 임의의 view의 전체 이미지를 얻기 위해 모든 ray를 render하고, loss gradient를 계산 한 후에, patch level로 gradient를 back-propagate했다고 합니다. 이를 통해 memory consumption을 상당히 줄이고, high-resolution image를 만들 수 있었다고 합니다.
Experiments
3가지 데이터셋으로 테스트하였습니다.
첫번째 데이터는 직접 촬영하였습니다. 정면 카메라를 갖고 10초간 셀카 video를 6개 촬영하였고, 15fps를 가지는 FFmpeg사용해서 각 video마다 100 frame을 추출했습니다. 270x480으로 resize한 후에 COLMAP을 사용해서 camera pose를 추정했습니다. 같은 camera intrinsic값을 사용했습니다.
두번째 데이터는 H3DS 데이터셋에서 여자 1명을 reconstruct하였습니다. noise frame을 제거하고 31개 sparse view를 얻었습니다. 256x256의 이미지입니다.
세번째 데이터는 Local Light Field Fusion(LLFF) 데이터셋 입니다. non-face scene을 테스트하기 위함이고, 약 20-60개 이미지로 구성된 정면 scene 사진입니다.
정량적으로 측정한 실험 결과입니다.

기존의 여러 Stylization 연구인 StyleGAN-NADA, Text2Mesh, CLIP-NeRF, DreamField, AvatarCLIP 과 비교했습니다. 위의 표는 남자10, 여자13명의 테스터에게 충분한 시간을 주고, 각 비교 연구의 결과 1개와 NeRF-Art 결과 이미지 1개를 보여주고 어떤 이미지가 좋은 Stylization 결과인지를 선택하라고 했을 때의 결과라고 합니다. 5개의 연구와 비교하였고, 각 비교 연구마다 10번 보여줬기 때문에 1사람당 50번을 테스트했습니다. 모두 NeRF-Art가 좋은 결과라고 선택하였습니다.
그 외에는 정성적인 실험 결과들입니다. 눈으로 확인해보시길 바랍니다.






Closing..
어떤 상황에서 어떤게 문제였고, 이렇게 해결하였다라는 서술법이 명확해서 읽기 편한 논문이었습니다. 다만 대부분의 논문이 그러하듯 엄청난 양의 연구 결과들을 한 두 줄씩 표현하고 넘어가서, 그 의미를 파악하는데 어려웠구요. 이 글을 읽다보니 최근 Text to 3D 연구들인 Google의 DreamFusion, Nvidia의 Magic3D이 재밌어 보이네요. 가까운 시일에 정리해보도록 하겠습니다.
'NeRF' 카테고리의 다른 글
| [API 리뷰] NeRF Studio : NeRF 통합 Framework (10) | 2023.02.27 |
|---|---|
| [논문 리뷰] NICER-SLAM (3DV 2024) : NeRF접목 dense RGB SLAM (2) | 2023.02.15 |
| [논문 리뷰] RawNeRF (CVPR 2022) : HDR, Denoising, Defocus연구 (0) | 2023.01.29 |
| [논문 리뷰] iMap NeRF (ICCV 2021) : SLAM에 NeRF를 접목 (1) | 2023.01.06 |
| [논문 리뷰] DS-NeRF (CVPR 2022) : 적은 입력 + depth 추정 연구 (3) | 2022.12.25 |




댓글