iMAP: Implicit Mapping and Positioning in Real-Time, Edgar Sucar, ICCV2021
NeRF가 어떻게 확장 될 수 있을까요? 이번 논문은 Simultaneous Localisation and Mapping(SLAM)에 NeRF를 적용한 연구입니다. 논문 저자는 real-time SLAM분야에서 Scene Representation을 MLP로 적용한 최초의 논문이라고 소개하고 있습니다. SLAM분야에서 대단한 연구인 것 같은데, (이쪽 분야를 잘 알지 못해서) 부연 설명을 할 수가 없네요. 대신 NeRF관점에서 어떻게 SLAM분야로 적용하였는지에 대해 중점적으로 설명하겠습니다.
논문 저자의 소개 영상입니다.
RGB와 Depth이미지를 입력받아 실시간으로 Map을 형성합니다. 카메라는 Azure Kinect RGB-D를 사용하였다고 합니다.
iMap연구를 통해 만든 결과 Map입니다.

흰색이 현재 Frame이고 초록색이 KeyFrame, 노란색은 tracking경로입니다.
논문을 이해하기 위해 사전지식으로 SLAM 기초부터 다뤄보겠습니다.
SLAM
SLAM소개 블로그 에 잘 설명되어 있습니다. 아래 설명으로 부족하다면 해당 블로그 참고 바랍니다.
SLAM은 움직이는 로봇의 (동작) control센서값과 camera 센서값을 입력받아, 로봇의 (이동) Path를 추정하면서 동시에 Map을 구성하는 연구입니다. Control센서는 IMU가 될 수 있습니다.
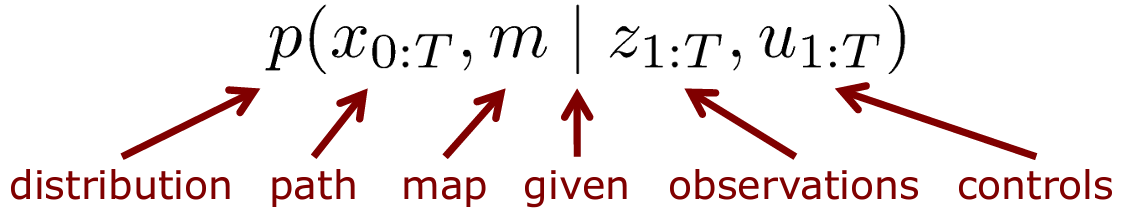
SLAM에서는 카메라 정보(observation), 로봇 Control정보(controls)가 주어질 때, 로봇의 위치(Path)와 주변 환경 지도(Map)의 분포(Distribution)를 표현하는 분야입니다.
크게 Tracking(Localization)을 통해 로봇의 위치를 추정하고, Mapping을 통해 Map을 구성합니다.
Tracking과정에서는 Landmark정보로 로봇의 위치를 업데이트 합니다. 별표는 Landmark, 흰색원은 이상적인 로봇 위치, 회색원은 실제 로봇 위치를 나타냅니다.

Mapping과정에서는 로봇 위치정보로 Map을 업데이트 합니다. 노란별표는 실제 Map, 회색별표는 추정한 Map, 흰색원은 이상적인 로봇 위치입니다.

Tracking과 Mapping을 동시에 해야 현실과 동일한 Map을 생성 할 수 있으며, Control센서, Camera센서 모두 Noise가 있을 수 있기에 어려운 분야입니다. Noise에 대한 예시로, 바닥에 장애물이 있을 경우 control 센서에 Noise가 발생 할 수 있고, 움직일 경우 블러가 생기면서 camera센서에도 noise가 발생 할 수 있습니다.
논문에 언급된 Keyframe Selection은 SALM분야 중 하나인 PTAM연구에서 나온 개념으로, 이전 Scene들에 대한 정보를 잃어버리지 않도록, 중요한 frame들을 저장해놓고 재사용하는 방법론 입니다. tracking을 하다가 위치를 놓쳤을 경우 keyframe을 사용하기도 합니다.
SLAM의 분류는 'Sparse한 Map'을 만들지 'Dense한 Map'을 만들지 나뉘고
모든 센서 값을 사용하는 'Full SLAM'인지 실시간 센서값으로 생성하는 'Online SLAM'인지에 따라 나뉩니다.
iMap에서는 Dense Map에 Online으로 Map을 생성합니다.
iMap Overall Architecture

실시간으로 RGB-D카메라로 RGB이미지 I와 Depth이미지 D를 획득하면서 모든 과정이 처리됩니다. 최초 Frame을 Keyframe(학습할 Target Frame)으로 정하고, World Coordinate의 정점으로 사용합니다. 최초 Frame으로 카메라 Pose값인 T를 초기화합니다. T는 Camera 좌표계를 World좌표계로 변환하는 Matrix인 Camera Extrinsic Matrix의 역함수로 구성되어 있습니다. (카메라 Intrinsic Parameter, Extrinsic Parameter 개념 이전포스트 참조) 수식은 아래와 같으며, Rc는 카메라의 Rotation Matrix이고 C는 카메라의 Position입니다. T는 SLAM개념 설명에서 언급한 로봇위치(Path)에 해당합니다.
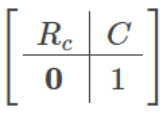
keyframe으로 Joint Optimization을 하게 되는데, 이 과정은 NeRF모델과 카메라 Pose를 동시에 업데이트하는 단계에 해당합니다. 등록된 Keyframe의 특정 Pixel좌표에 대해 NeRF모델로 Inference하여 RGB값과 Depth값을 계산하고, 실제값과 예측값의 차이(Loss)를 계산하여 NeRF 모델을 업데이트 합니다. NeRF모델로 Voxel좌표를 inference한 color값과 volume density값은 SLAM에서의 Map에 해당됩니다. NeRF모델과 카메라 Pose parameter를 업데이트 하면 위에서 설명한 Map 업데이트에 해당하게 됩니다.
이렇게 계산한 NeRF모델과 카메라 Pose T가 업데이트 된 상태에서, 새로운 RGB-D신호가 들어왔을 때, NeRF모델의 weight parameter를 고정하고, 같은 Loss로 카메라 Pose인 Inverse Extrinsic Matrix T만을 업데이트합니다. 이는 SALM이론상 Traking과정에 해당합니다.
추가로 SLAM 소개에 언급한 control값은 주어지지 않는 것 같습니다. 손으로 들고 촬영하였다고 하는데, 이동에 관한 sensor값에 대해 명시되어 있지 않습니다.
다음으로 세부 과정을 하나씩 소개하겠습니다. Map을 그리는 Rendering부분, Model Weight Update부분, 연산량을 줄이기 위한 Point Sampling 부분으로 나누어 설명하겠습니다.
Map Rendering
NeRF (최초 NeRF 이전포스트 참조)와 비교하면 모델의 구조는 단순합니다.

iMap은 NeRF에서 View Direction(θ,Φ) 를 입력으로 받는 것만 사라지고, 다른 부분은 동일합니다. voxel좌표(x,y,z)에 대한 color를 계산하는 공식이 달라보이지만, 자세하게 보면 같은 수식임을 알 수 있습니다. depth에 대해서 NeRF논문에서는 언급안됬지만 소스코드 (NeRF 소스코드 분석 이전 포스트 참조)에 보면 Depth를 계산하는 수식이 있습니다. color대신에 카메라 시점에서 Point가 떨어진 거리 만큼을 di로 쓰고, 이 di값을 ci값 대신 사용해서 Depth를 계산합니다.
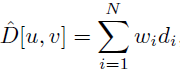
Ray위에 있는 점을 Sampling하는 방식은 NeRF의 stratified and hierarchical volume sampling을 그대로 사용 하였습니다 (최초 NeRF 이전포스트 참조). 3D 좌표 Encoding에 관련해서는 NeRF의 Positional Encoding을 사용하지 않고, Fourier Feature Network를 사용하였습니다. normal distribution으로 nx3 matrix B를 구성하고, 3D 좌표 p에 대해 sin(Bp)값을 계산하는 방식입니다. n은 dimension의 크기입니다. SIREN방식을 적용하여 single FC layer로 matrix B를 optimization을 했다고 논문에 표현되어 있는데, normal distribution에서 standard devication σ값을 업데이트 하지 않았을까 생각됩니다. (아닐 수 있습니다. 자세한건 SIREN논문을 봐야합니다.)
이를 통해, 특정 Keyframe에서의 color와 depth를 위의 수식으로 계산하게 됩니다.
Model Weight Update
Keyframe에 RGB-D 영상은 Ground Truth값에 해당합니다. 이 GT값으로 NeRF모델 Parameter과 Camera Pose Parameter를 업데이트 합니다. Loss는 둘다 동일하게 사용합니다.

실제 논문에서는 다른 Numbering으로 되어 있습니다. 설명을 위해 따로 붙였습니다.
(1)는 전체 Loss입니다. geometric loss Lg, Loss 중요도 상수 λ, photometric loss Lp로 구성되어 있습니다.
(2)는 (1)의 세부수식으로써, i번째 keyframe에서 추출한 sample pixel각각에 대해, 실제값과 예측값의 L1-norm Loss들의 합으로 계산됩니다. W는 Keyframe의 갯수, M은 pixel의 갯수입니다. geometric loss에서는 분모에 예측값에 대한 분산(variation)값을 넣어줬는데, 예측한 값이 입력 depth값인 di와 차이가 클 경우에 uncertain(불확실성)이 높다고 판단하고 Loss를 줄여서 사용했습니다.
위 Loss는 Mapping과정 Tracking과정에서 NeRF모델, Camera Pose Parameter를 업데이트 할 때 사용됩니다. Tracking과정에서는 NeRF모델의 Parameter는 고정이 됩니다.
Point Sampling
실시간 처리를 위해서 Loss 계산할 Frame(=Keyframe)수를 4개로 제약하고, 4개 Keyframe에서도 sampling하는 pixel 갯수를 200개로 제약하였습니다. Keyframe은 한 개 Scene당 10~14개정도로 셋팅하며, 무수한 RGB-D입력 이미지 중에서 Keyframe을 선택하는 알고리즘과 선택된 keyframe중에서 Loss를 계산할 Keyframe을 선택하는 알고리즘으로 나뉘어져 있습니다.
Keyframe를 선택하는 알고리즘

1개 frame에서 s개의 2D sampling point에 대해, Depth GT값(D)과 prediction값(^D)의 오차를 계산하여, tD(=0.1)이하인 것의 비율이 0.65보다 적을 경우 해당 frame을 keyframe으로 선택합니다. 다르게 설명하자면, Depth Prediction의 오차가 큰 sample이 100개 중 65개 보다 많을 경우 keyframe을 선택합니다. 오차를 계산 할 때, 분모에 GT D가 있는데 해당 수식을 통해 물체가 카메라로부터 근접할 때 high precision 이미지를 얻게 합니다. 저자 영상을 보면 카메라가 물체 가까이에 있을 경우 Keyframe이 획득되는 것 을 볼 수 있습니다.
Loss를 계산할 Keyframe을 선택하는 알고리즘

각 keyframe마다 Loss Distribution을 구하고, Loss Distribution이 가장 높은 3개의 keyframe과 현재 frame을 Loss를 계산할 keyframe으로 선정하게 됩니다. 전체적으로 항상 Loss가 큰 frame을 선택함으로써, 적은 iteration으로 효과적으로 학습하게끔 설계가 되었습니다. Loss Distribution계산 방법은 Point Sampling에서 설명하겠습니다.
각 Keyframe마다 10~20번의 iteration의 joint optimisation을 했다고 합니다.
다음으로 각 frame마다 point를 sampling하는 알고리즘을 소개하겠습니다. 논문에서는 Active Sampling이라고 표현하고 있습니다.
Active Sampling
두 단계의 sampling으로 나누어집니다. keyframe에서 랜덤하게 균일하게 point를 뽑습니다. 그리고 8x8 grid로 영역을 나누고, 각 영역에 대해 Loss를 구합니다.

i는 keyframe번호, j는 영역번호입니다. rj는 j영역의 smapling pxiel갯수입니다. 위 수식을 토대로 영역에 대한 Loss의 확률분포값을 계산합니다.
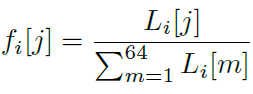
전체 에러 대비 j번째 영역의 에러비율을 알 수 있습니다.
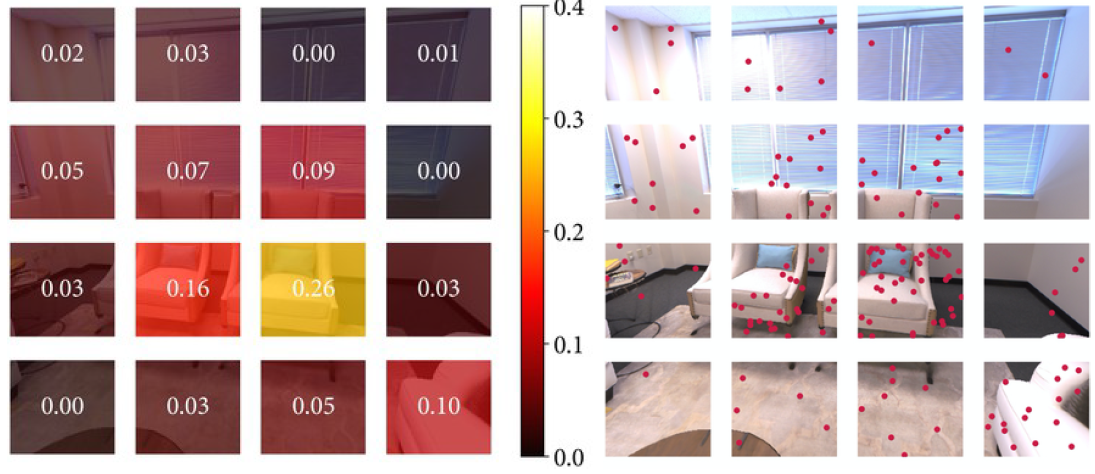
그리고 각 영역에 대해 아래 수식으로 point갯수를 계산 한 후, 해당 갯수만큼 point를 영역내에서 랜덤 sampling합니다.
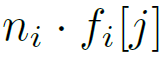
ni는 i번째 keyframe의 전체 sampling point 갯수입니다. 위의 왼쪽 이미지는 영역에 대한 Loss distribution을 계산한 것이고, 오른쪽 이미지는 위 수식을 대입하여 영역마다 랜덤 sampling한 결과를 보여줍니다.
이러한 설계를 통해, 높은 Loss를 가진 sample을 찾아내서 학습하고, detail한 영역에 대해 좀 더 학습하도록 가이드 하게 됩니다.
Key frame선택시 Loss Distribution계산도 이와 같은 방법으로 계산되었습니다.
Experiments
실험 데이터로는 5개 office와 3개 아파트 room을 스캔하였고, Azure Kinect를 손으로 들고 촬영하여, 각 Scene마다 RGB-D의 2000 frame을 획득하였다고 합니다.
평가는 200,000개의 point를 sampling하여 Accuracy와 Completion을 계산하였습니다.
Accuracy는 predict된 mesh에서 sampling한 point와 GT에서 가장 가까운 point 사이의 평균 거리를 측정하였습니다.
Completion은 GT에서 sampling한 point와 predict된 mesh에서 가장 가까운 point사이의 평균거리를 측정하였습니다.
Completion Ratio(<5cm %) 은 다른 평가 지표로써, Completion이 5cm이하인 point의 비율을 측정 하였습니다.
비교군은 Dense SLAM기반의 TSDF Fusion이라는 논문입니다.


iMAP이 TSDF에 비해, Completion기반 평가에서 더 좋은 수치를 보이는 것을 볼 수 있습니다. 생성된 Map을 보면, iMAP은 관측하지 않은 영역도 plausible(있음직하게) 채워지는 것을 볼 수 있습니다. watertight geometry estimiation이라고 표현하네요. watertight 라는 단어가 사전적의미로 물이 새지 않는, 빈틈없는이라고 되어 있네요. NeRF모델을 사용한 장점이라고 생각됩니다.
iMAP은 기존 연구보다 메모리를 적게 사용한다고 합니다. iMap은 network width를 사용하고, TSDF는 Voxel Resolution을 사용하여 비교하였는데, TSDF를 몰라서 적절한 비교방법인지 모르겠습니다.

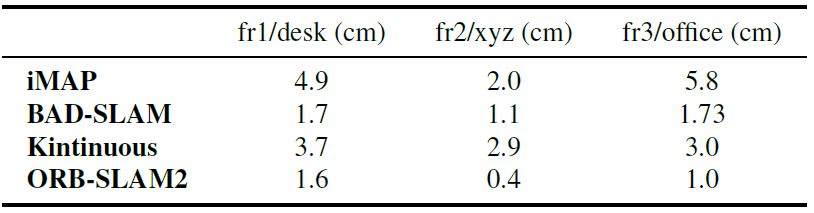
Camera Pose 추정 정확도에서는 좋지 않습니다. TUM RGB-D dataset으로 pose 오차를 측정하였을 때, 기존 연구보다 많은 오차를 갖고 있었습니다. 그래도 저자는 2~5.8cm정도의 오차라며 competitive한 성능이라고 말하고 있습니다.
다음으로 속도입니다. network width 256, window size 5, keyframe당 sample수 200개를 Default값으로 하여 설계하였을 때, GPU에서 Tracking에서는 101ms, Joint Optimisation에서는 448ms를 보였습니다. (GPU 성능이 표기 안되어 있네요..)아래 표는 다양하게 변수를 조절 했을 때의 결과 값입니다. W는 loss distribution을 계산하기 위해 선택되는 current frame을 제외한 keyframe의 갯수입니다.
마지막으로 Active Sampling의 효과입니다. Active Sampling을 하였을 때 Training time이 줄었다는 실험 결과입니다.

Closing..
작년쯤에 SLAM에 Neural Network가 들어갔다라는 소문만 들었는데, 이렇게 적용을 했다니 읽는 내내 신기했네요. View Direction을 입력값으로 사용하지 않아 View Direction에 따른 Radiance가 계산하지 않고, 3D 좌표에 대해 반복 최적화를 통해 Map을 생성한 것으로 보입니다. Point를 200개만 Sampling하여 Loss를 구하였지만, 이미지 한장을 다 그릴려면, 기존 NeRF와 랜더링 시간이 비슷할 것 같네요. NeRF를 이용한 실시간 Map생성 재밌게 읽었습니다. 후속 논문들도 기대됩니다.
'NeRF' 카테고리의 다른 글
| [논문 리뷰] NeRF-Art (arXiv 2022) : Text 입력 Style 변형 연구 (0) | 2023.02.11 |
|---|---|
| [논문 리뷰] RawNeRF (CVPR 2022) : HDR, Denoising, Defocus연구 (0) | 2023.01.29 |
| [논문 리뷰] DS-NeRF (CVPR 2022) : 적은 입력 + depth 추정 연구 (3) | 2022.12.25 |
| [논문 리뷰] NeRF-W (CVPR 2021) : Uncertainty 접목 연구 (0) | 2022.12.13 |
| [논문 리뷰] Mip-NeRF (CVPR 2021) : Anti-Aliasing 연구 (2) | 2022.12.04 |




댓글