Depth-supervised NeRF: Fewer Views and Faster Training for Free, Kangle Deng, CVPR2022
최초 NeRF(논문 리뷰 바로가기)에서는 Scene마다 적은 수의 학습 데이터를 사용 할 경우 성능이 좋지 않습니다.
이를 개선한 논문으로 적은 수(1장 or 3장)의 이미지로도 학습이 가능한 PixelNeRF(논문 리뷰 바로가기), MVSNeRF(논문 리뷰 바로가기), MetaNeRF들이 공개되었습니다. 이 논문들에서는 Training Scene에서 Train data에 대한 공통 Feature extraction 부분을 학습해놓고, Target Scene에서 적은 수 이미지로 Rendering 부분을 학습하는 방식으로 해결하였습니다. 때문에 이전 연구들에서는 Train set과 Test set의 Distribution이 비슷해야 했었고, 다를 경우 성능이 좋지 않을 것이라 생각됩니다.
DS-NeRF에서는 Point Cloud정보를 추가로 활용합니다. 그러면 Depth 카메라를 써야 되고, 실용성이 떨어질 것이라 생각이 드는데요. 최초 NeRF에서 데이터셋을 만들 때, SFM(structure-from-motion)기반인 COLMAP을 사용해서 촬영한 이미지들로 카메라 Parameter를 만들었습니다. COLMAP에서는 카메라 Pose 이외에도 3D Point Clouds를 추정합니다. DS-NeRF에서는 이 3D Point Clouds 정보를 사용하여, Sparse View 문제를 해결하고, Depth Map 퀄리티를 개선하고, 학습 속도까지 개선하였습니다.
Overall Structure
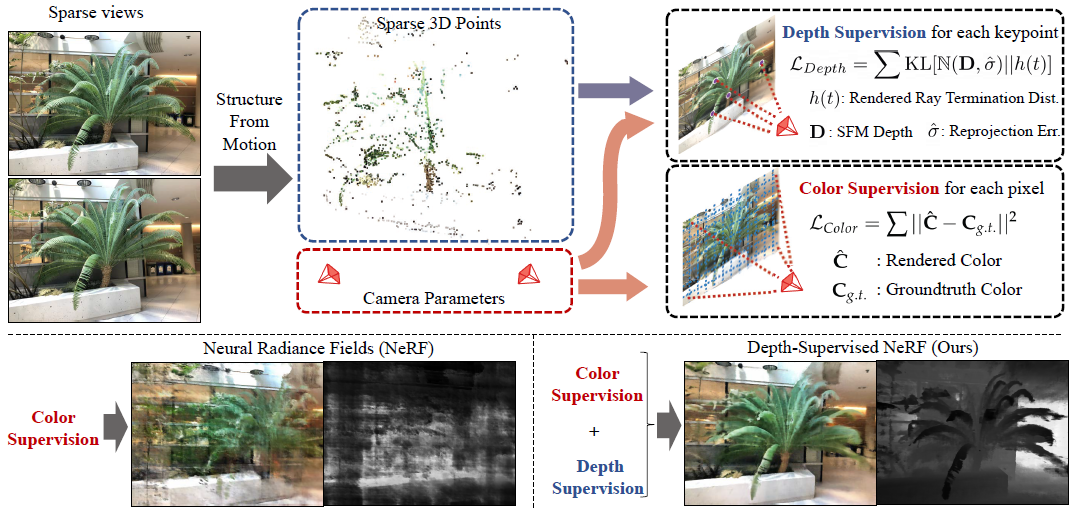
이미지를 입력으로 Structure From Motion(아래 설명)을 사용해서 3D Point Cloud와 Camera Pose인 Camera Paramter를 계산합니다. 3D Point Cloud값을 사용한 Depth Supervision Loss와 기존 NeRF와 동일한 Color Loss를 사용해서 학습합니다.
아래 왼쪽 그림은 Sparse Views(2~10개)에 대해 Color Loss만 사용한 NeRF의 Rendering결과와 Depth Map 결과를 나타내고, 아래 오른쪽 그림은 같은 데이터셋에 대해 Depth Loss를 추가로 사용할 경우 결과를 보여줍니다.
SFM(Structure From Motion)
논문에서 가장 많은 역할을 하는 SFM에 대한 알고리즘에 대해 간략하게 소개하겠습니다.
https://woochan-autobiography.tistory.com/944 에 SFM에 대해 잘 소개되어 있습니다.
여러 이미지를 입력으로 받아서, Pose와 3D Point Cloud를 추정하는 알고리즘이고 아래와 같은 단계로 이루어져있습니다.
1. 이미지를 입력으로 SIFT를 사용해서 특징점을 검출
2. Epipolar Geometry로 feature의 correspondence 추정하고 카메라 pose를 대략적으로 추정
3. Triangulation(삼각법)으로 3D Point Cloud를 대략적으로 추정
4. Bundle Adjustment 으로 3D Point Cloud와 카메라 pose를 보정
이 알고리즘을 구현하여 오픈소스로 활용한 것이 COLMAP입니다.
Loss Function
DS-NeRF의 알고리즘은 입/출력 부분 이해와 Loss Fuction이 전부인 것 같습니다.
Loss Fuction은 Color Supervision Loss와 Depth Supervision Loss로 이루어져있습니다. λD는 상수입니다.

먼저 익숙한 NeRF의 Color Supervision Loss는 아래와 같습니다. (추가 설명은 이전 포스트 참고 바랍니다.)

논문에서는 Depth Supervision Loss를 설계하게 된 배경을 먼저 설명하고 있습니다.

그림(b)의 빨간색 지점으로 Ray를 그려보면, Ray위에 여러object가 있으므로 깊이 t의 voxel에 대한 volume density σ(t)는 (a)1그림와 같이 그려지게 됩니다. Volume Rendering 공식에 의해 깊이 t까지의 투명도를 나타내는 T(t)와 ray의 volume density인 σ(t)를 곱하면 h(t)가 계산되고, (a)4그림과 같이 됩니다. peak가 한개있는 unimodal 형태이며, NeRF에서는 학습 데이터가 충분히 많아질 경우에 나타내는 그래프라고 합니다. 논문저자는 이 h(t)값을 실제 depth의 distribution인 (b)1 분포와 비슷하게 만들고자 하였습니다. NeRF에서는 (b)2그림 처럼 Multi-modal형태의 그래프가 그려지게 됩니다.
DS-NeRF에서는 (b)2 와 같은 분포를 (b)3 분포로 표현하기 위해, 3D Point Cloud 정보로 Depth Supervision Loss를 설계하였습니다.

j번째 이미지의 i번째 3D keypoint들과 ray sampling 깊이 t가 변수로 주어집니다. 왼쪽항은 Expection(기대값)이고, 오른쪽항은 계산 할 수 있도록 풀어서 근사한 식입니다. 왼쪽항부터 보면, 'Surface와 가장 근접한 깊이D'와 'sampling한 깊이 t'간의 차이에 대한 distribution δ이 'inference한 h함수'에 대한 distribution과 유사하게 하고자 합니다. 이를 계산이 가능한 Normal distribution함수로 표현하면 오른쪽 수식이 됩니다. 'COLMAP으로 관측한 깊이 D에대한 distribution'과 'inference한 h함수'에 대한 KL Divergence를 최소화하도록 Loss를 설계하였습니다.
다르게 설명 해보겠습니다. COLMAP결과로 object surface부근에 1개 임의의 3D Key Point를 estimation 했다고 가정해봅시다. 그 Point에 서로 다른 view direction에서 ray가 그려지게 됩니다. 임의의 1개 ray에서 '기대하는 깊이D'와 '(NeRF기법으로)샘플링한 깊이t'간의 차이에 관한 Distribution은 COLMAP에서 관측한 깊이D에 대한 Normal Distribution으로 표현 할 수 있습니다.
KL Divergence는 두 확률분포(p,q)의 차이를 계산하는데 사용하는 함수로, 다음과 같은 수식입니다.
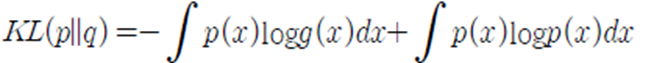
여기서 p는 COLMAP이 추정한 깊이D에 대한 normal distribution이고, q는 rendered ray distribution h(t)입니다. KL divergence를 Loss로 사용할 것이므로, 오른쪽 항의 변수는 p(x)만 있으므로 상수취급하여 없앱니다. normal distribution에 대한 일반적인 수식은 아래와 같습니다.
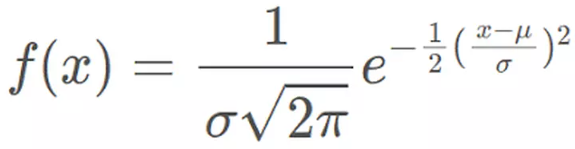
exp의 앞부분도 상수로 취급하여 없앱니다. 그렇게 나온 수식이 아래식입니다.
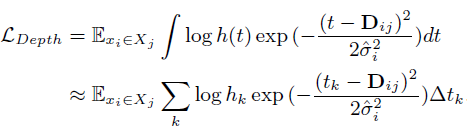
위 식은 continuous한 공간에서의 수식이며, 아래는 NeRF와 같은 Discrete한 공간에 대한 수식입니다.
눈문저자가 공개한 코드(https://github.com/dunbar12138/DSNeRF)의 Loss는 아래와 같습니다.
loss = -torch.log(weights) * torch.exp(-(z_vals - depths[:,None]) ** 2 / (2 * err)) * dists해당 Loss로 학습하여 h(t)가 update 될 수 있도록 합니다. (+ 코드에서 표준편차는 err로 되어 있는데 항상 1의 값으로 초기화 되어 있네요.)
Depth supervision Loss 부분에 대한 수식과 코드는 그대로 들고 왔지만, 이에 대한 의미 해석은 틀릴 수 있으니 참고만 하시길 바랍니다.
Experiments
DTU Dataset Evaluation

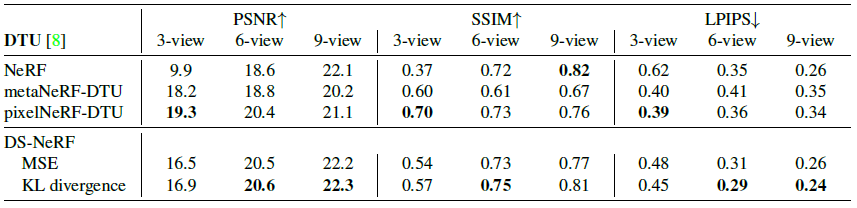
학습 데이터가 3개의 이미지가 주어지는 3-view에서는 PixelNeRF가 더 좋은 성능을 보이고, 6-view / 9-view에서는 DS-NeRF가 더 좋은 성능을 보입니다. PixelNeRF에서는 다른 Scene들로 Feature Extraction부분을 학습하기 때문에 실제적으로 학습데이터가 더 많다고 생각 할 수 있습니다. Prior 학습이 없는 DS-NeRF에서는 3-view에서 충분한 정보가 없기 때문에 성능이 낮게 나오고, 6-view부터 성능이 좋습니다.
NeRF Real Dataset Evaluation


metaNeRF, pixelNeRF는 DTU데이터로 piror를 학습하였기 때문에 위 NeRF Real데이터셋의 도메인 차이가 있어, 성능이 좋지 않은 것을 볼 수 있습니다. (DTU데이터는 미니어처 모형을 비슷한 거리에서 비슷한 view direction으로 촬영하였지만, NerF Real 데이터셋은 멀리 떨어진 사물의 앞부분을 카메라로 촬영합니다.) 위 표에서 finetuned는 priror를 해당 Scene의 2개 데이터로 feature extraction network 부분을 추가로 학습 하는 것을 의미합니다. 때문에 pixelNeRF, MVSNeRF는 좀 더 성능이 향상됩니다. finetuned w/ DS는 Depth Supervision Loss를 사용하였을 때의 결과입니다. 성능이 물론 올라가지만, DS-NeRF의 성능이 더 좋은 것을 볼 수 있습니다.
RedWood Dataset Evaluation
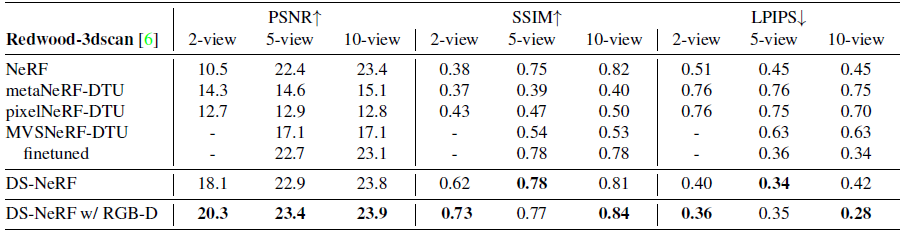
NeRF Real과 비슷한 양상을 보입니다. RedWood Dataset에서는 Depth Map 정보도 같이 제공되는데, 이 Depth Map을 COLMAP 대신에 사용하여 성능을 좀 더 향상하였습니다. (마지막 행)
Depth Evaluation

DS-NeRF는 이전 연구 보다 좀 더 높은 퀄리티의 Depth Map을 생성하는 것을 볼 수 있습니다. NeRF Real 데이터셋 테스트셋 평가에 그림을 참고하길 바랍니다. RedWood데이터셋에서 제공하는 Depth 정보를 입력으로 하여 학습을 할 경우 Depth Map 생성 결과가 더 좋은 것을 확인 할 수 있습니다.
Speed Evaluation

5-view/10-view인 경우 DS-NeRF는 NeRF보다 2~3배 수렴속도가 빠른 것을 확인 할 수 있습니다.
RTX A5000에서 DS-NeRF는 iteration당 362.4ms 이고 NeRF는 359.8ms가 소요되었습니다.
5-view기준으로 NeRF가 Peak 성능을 가지는 100,000 iteration의 성능을 DS-NeRF는 13시간 더 빠르게 도달 하였습니다.
Closing..
COLMAP을 이미지 2장으로 할 경우에도 Point Cloud가 잘 추출 될까 싶네요. COLMAP 속도도 빠를지 궁금하구요. SFM 관련 논문을 읽어봐야겠다는 이런 궁금증이 풀릴 것 같습니다. few image 입력을 처리하는 관점에서 PixelNeRF와 MetaNeRF에서는 Target Domain관련 데이터로 학습 해야 하는데, DS-NeRF에서는 이를 하지 않아도 된다는 장점이 있습니다. 반면에 Train / Inference을 실시간으로 하기엔 부족해서 Application으로는 만들려면 다른 기법들이 추가되어야 할 것 같습니다.
'NeRF' 카테고리의 다른 글
| [논문 리뷰] RawNeRF (CVPR 2022) : HDR, Denoising, Defocus연구 (0) | 2023.01.29 |
|---|---|
| [논문 리뷰] iMap NeRF (ICCV 2021) : SLAM에 NeRF를 접목 (1) | 2023.01.06 |
| [논문 리뷰] NeRF-W (CVPR 2021) : Uncertainty 접목 연구 (0) | 2022.12.13 |
| [논문 리뷰] Mip-NeRF (CVPR 2021) : Anti-Aliasing 연구 (2) | 2022.12.04 |
| [소스코드 분석] NeRF (ECCV 2020) (3) | 2022.11.26 |




댓글