Scaffold-GS: Structured 3D Gaussians for View-Adaptive Rendering, Tao Lu, CVPR 2024
3D Gaussian Splatting(3D-GS) 후속 논문들에서 많이 언급되는 논문입니다. 때문에 어떤 논문인지 빠르게 파악하길 원하는 분들을 위해서 정리해봤습니다. 이번 논문 리뷰는 원논문 흐름을 따르지 않고, 이해하기 편하게 내용을 재구성했습니다.
문제점
논문에서 언급하고 있는 기존 3D Gaussian Splatting(3D-GS) 문제점입니다.
- 과도하게 중복된 Gaussian을 생성합니다.
: 시점이나 거리에 관계없이 주어진 training 이미지를 모두 반영하기 위해, 과하게 중복된 gaussian을 생성합니다. - Multi Scale을 고려하지 못합니다.
: 고정된 크기의 Gaussian들이 생성되면서 여러 카메라 스케일에서 세밀하게 랜더링하지 못합니다. 예를 들어, 큰 scale의 scene에서 작은 scale의 세부 정보를 잘 처리하지 못합니다. - 보간능력을 갖지 못합니다.
: view 시점에 따라 고정된 색상값으로 만들어지기 때문에, 시점에 따른 보간(interpolation)능력이 부족합니다. 입력 카메라 포즈 변화가 크거나, 조명 효과가 있는 경우 일관된 결과를 만들 수 없습니다.
Overview
알고리즘은 크게 3가지 부분으로 나뉩니다.
- Anchor Point Initialization : scene을 $\epsilon$ 크기의 정육면체로 나누고, 해당 정육면체의 중심을 anchor point로 셋팅합니다.
- Neural Gaussian Derivation : anchor point를 기준으로 해서 주변 gaussian을 예측하는 MLP모델을 만듭니다.
- Anchor Points Refinement : 초기 Anchor는 COLMAP의 point cloud 기준으로 만들어지기 때문에, 학습 과정중에 필요하거나 불필요한 Anchor를 추가하거나 제거하게 됩니다.

Anchor Point Design
Point cloud P가 주어지면, $\epsilon$ 크기의 정육면체들로 구성된 Grid를 만듭니다. 이 정육면체를 cell이라 표현하면 좋을 것 같은데, 논문에서는 voxel로 부르고 있습니다. x,y,z좌표를 가진 point를 $\epsilon$ 으로 나누어 set자료형에 넣고 다시 $\epsilon$을 곱하는 형태의 수식으로 표현합니다.

voxel의 중심이 anchor point가 됩니다. 필요한 갯수만큼 voxel을 생성해주는 역할로 생각하면 될 것 같습니다.
Input/Output 설계
각 anchor point마다 k개(=10개)의 3D Gaussian을 만듭니다. Gaussian의 좌표 값인 mean(μ)의 경우엔, anchor point($x_v$)에 offset $O$와 scaling factor $l$로 구성됩니다.

다른 Parameter인 opacity, color, scale, quaternion는 MLP를 통해 출력하도록 설계됩니다.

다음은 MLP의 Input 부분에 대해 살펴보겠습니다. 32는 batch(=N)인 것으로 보이고, 36 dimension이 어떻게 구성되는지 보겠습니다.
Anchor Point Feature Structure
각 anchor point는 $ f_v \in \mathbb{R}^{32} $ 의 feature를 가집니다. 이 feature는 multi-resolution과 view-dependent한 특성을 갖게 하기 위해, 약간 복잡하게 integrated anchor feature $\hat{f}$ 라는 이름으로 바꿔서 사용됩니다. (위 input에서 파란색 사각형 부분입니다.)

$f_{v↓}$는 down-sample된 feature라고 하며, 32개의 feature를 합치는 형태로해서 만들어집니다. 이 부분이 multi-resolution을 고려한 부분이라 생각됩니다.

$w$의 경우엔 view-dependent를 고려하도록 설계됩니다.

$x_v$는 anchor point좌표이고, $x_c$는 카메라 좌표입니다. 거리와 방향 vector를 계산하게 됩니다. 이를 tiny한 다른 MLP $F_w$에 통과시켜 $w, w_1, w_2$를 획득합니다.

앞서 언급한 MLP 입력부분의 보라색 부분을 보면, $\delta_{vc}$와 $\vec{d}_{vc}$이 있습니다. 이 두개 값은 $\hat{f}$를 계산하는데도 쓰이면서, 별도 입력으로도 쓰이는 것을 볼 수 있습니다. 그만큼 중요한 factor로 작용하는 것으로 보입니다.
여기까지 내용이 논문에서 nchor Point Initialization과 Neural Gaussian Derivation로 구성된 Scaffold-GS로 소개하고 있습니다. 다음으론 어떻게 Anchor Point를 추가/삭제하는지에 대한 내용입니다.
Anchor Points Refinement
초기 Anchor point는 COLMAP결과로 만들어진 point로 초기화되기 때문에, SfM의 특성상 texture가 없는 영역과 관측이 적은 local 영역에서 문제가 됩니다. 때문에 Anchor point를 추가하게 되는데, N번(=100번)훈련 동안 변화된 Gaussian의 gradient값을 사용합니다. Voxel이 없는 영역에 포함된 gaussian들의 평균 gradient가 미리 정의된 Threshold $\tau_g$ (=64*$\epsilon$ or 12*$\epsilon$)이상일 경우, Anchor point를 생성(=Voxel을 생성)합니다. 아래 그림에서 흰배경 사각형은 기존 SfM으로 초기화된 voxel을 의미하고, 학습 과정중에서 색칠된 배경 사각형 공간으로 gaussian들이 이동되서 새로운 voxel을 생성해준 것으로 생각됩니다.
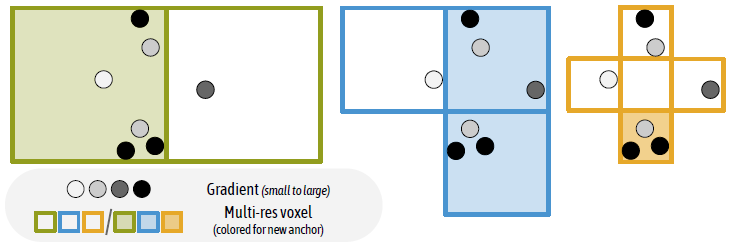
여기서 multi-resolution grid라는 개념이 같이 소개됩니다. voxel의 size $\epsilon_g^{(m)}$가 3개 level로 구분되는 grid입니다. m=1,2,3이며, threshold $\tau_g$는 scale에 따라 다른 값이 적용됩니다.

Anchor Point 초기화 할 땐 multi-resolution voxel이 언급이 없었는데, 초기화 할 때도 multi resoultion voxel형태가 되어 있어야 말이 될 것 같습니다.
여기까지가 anchor을 추가하는 growing operation에 대한 설명이며, anchor을 제거하는 pruning operation의 경우 짧게, N iteration동안 누적 opacity가 일정값 이하(=0.5)라면 제거한다고 되어 있습니다.
Loss Design
rendering한 pixel color 에 대해 학습 이미지에 대한 차이를 L1 Loss와 SSIM Loss 로 계산하고 추가적으로 volume regularization Loss를 사용하고 있습니다.

volume regularization loss의 경우, 각 gaussian의 scale이 중복이 되지 않고 커지지 않도록 해주는 Loss입니다.

각 scale vector값을 product연산하는게 전부입니다. loss weight parameter λ의 경우 ssim은 0.2, vol은 0.001을 사용했습니다.
Experiments
데이터셋별 퀄리티 평가입니다. 3D-GS와 소수점 단위의 차이를 보이기에 퀄리티 관점에서는 유사합니다.

랜더링 속도와 저장 용량의 차이입니다. 여기서는 확연하게 차이가 납니다.

MLP로 구성하기 때문에 저장하는 parameter가 적은 것을 볼 수 있습니다.
학습 속도 비교입니다. grid-based 기법으로 빠르게 converge하는 것을 볼 수 있습니다.

SfM point가 없는 Synthetic Blender 데이터셋의 경우, 100k개 anchor point로 시작해서 30k iteration 학습 한후에 anchor refinement 된 결과 anchor들로 scene을 초기화 한 후 다시 처음부터 학습시켰다고 합니다. (limitation으로 볼 수 있습니다.)
multi-scale 로 구성된 scene 인 BungeeNeRF 데이터셋과 VR-NeRF 데이터셋의 경우 3D-GS에 비해 높은 퀄리티 개선이 있었습니다.


글 처음에 언급한 3D-GS의 문제점으로 multi-scale training view에 과적합되고 과도하게 gaussian을 만든다고 했었습니다. 또한 3D-GS는 viewing angle과 distance에 대해 추론하는 능력이 없습니다. 그걸 보여주는 실험 결과이며, 본 논문 Scaffold-GS의 경우엔 local한 구조에 대해 Neural feature로 encoding해서 사용했기 때문에 rendering quality가 향상되고 converge speed가 빠르다고 소개하고 있습니다.
다음은 하나의 gaussian이 카메라 view에 따라 어떻게 바뀌는지에 대한 실험 내용입니다.

view-depedent하게 값이 바뀌는 것을 보여주면서, continuity를 가진다는 것을 보여줍니다.
다음으로 k의 변화(=anchor당 gaussian수)에 따른 실험입니다.

k를 다르게 시작 하더라도, anchor당 activated되는 gaussian의 갯수는 달라진다는 것을 보여주고 있습니다.
Ablation Studies
연산 효율성을 높은 filter에 대한 실험입니다.

view frustum에 포함되는 anchor만 계산하여 연산 효율성을 높였으며, 특정 opacity이하인 gaussian은 랜더링 하지 않았다고 합니다. 해당 내용이 본문에 언급되었지만, 개인적으로 너무 당연한 내용인 것 같아서 위에서 설명하지 않았습니다.
Anchor pruning과 growing에 관한 실험입니다. (vanila 3DGS의 denfication아닙니다.)

Pruning을 통해 연산량을 줄였으며, Growing은 texture가 없는 영역과 정교함이 필요한 영역에서 잘 작동했다고 합니다.
Limitations
SfM에 의존적이고, texture가 없는 영역이 많은 scene의 경우 문제가 된다고 소개하고 있습니다.
Closing..
해당 논문을 요약하자면 3DGS를 Neural Network 방식으로 해결했다고 볼 수 있습니다. 하지만 논문에서는 바로 파악하기가 어렵습니다. neural Gaussian이라고 표현하고 있지만, MLP를 사용한 것을 숨길려는 듯한 느낌을 받았습니다. 수렴속도가 빨라진다고는 언급되어 있지만, 1개 iteration마다 학습 속도가 느린지 빠른지 모르겠네요. 다른 논문보다가 학습 속도를 본 것 같은데, 그렇게 빠르지 않았던 것으로 기억합니다. 혹시 빌드해보시거나 아시는분 있으면 댓글 부탁드립니다. (해당 논문은 소스코드가 오픈되어 있습니다.)
'3D-GS' 카테고리의 다른 글
| [논문 리뷰] TransGS (arXiv 2024) : 실시간 얼굴 editing (0) | 2024.09.22 |
|---|---|
| [논문 리뷰] 3DGStream (CVPR 2024) : Free-view Video 생성 (1) | 2024.09.08 |
| [논문 리뷰] Grendel-GS (arXiv2024) : Multi GPU로 3DGS (0) | 2024.08.10 |
| [논문 리뷰] Mip-Splatting (CVPR2024) : Anti-aliasing 기법 (0) | 2024.07.28 |
| [논문 리뷰] PhysGaussian (CVPR 2024) : 물리 기반 변형 (3) | 2024.07.13 |




댓글