On Scaling Up 3D Gaussian Splatting Training, Hexu Zhao, 26 Jun arXiv2024
Multi GPU를 사용해 3D Gaussian Splatting모델로 Large Scene Reconstruction을 구성하는 방법에 관한 연구입니다.

3D Gaussian Splatting(3DGS, 이전글)로 Large-scale 또는 High-resolution scene 학습시, Memory & computation bottleneck 발생하게 됩니다. 이를 어떻게 해결하는지에 대해 논문에서 소개되어 있습니다.
문제 정의
문제1)
1개 GPU로 Scene을 구성하는 Gaussian 갯수에 대한 제약이 있습니다. A100 40GB GPU로 Gaussian을 11.2M개까지 구성 할 수 있다고합니다. 위에 보이는 그림 Rubble 데이터셋과 MatrixCity데이터셋으로 3DGS를 구성할 경우에 Gaussian 갯수를 보면, 40K, 24K로 1개의 GPU로 Scene을 만들 수 없습니다. 때문에 다른 연구들에서는 모델 compression을 적용하거나 selective rendering(랜더링하는 Gaussian의 갯수를 제약)하는 기법을 사용했습니다. 하지만 3D Gaussian의 갯수가 줄어들면 랜더링 퀄리티가 줄어들게 됩니다.
문제2)
3DGS는 imbalance한 workload로 학습되므로 분산처리에 적합하지 않습니다. 3DGS는 gradient-based training을 하게되며, dynamic하게 3D Gaussian이 생성되고 카메라 포즈에 따라 다른 갯수의 3D Gaussian이 랜더링되기 때문에 imbalance한 workload를 가지게 됩니다. pixel에 대한 차이를 Adam optimizer를 사용해서 학습하게 되는데, 이와 유사한 프로세스를 가진 neural network-based training 프레임워크의 경우 consistent하고 balanced workload를 가지는 모델을 가정하기 때문에 활용 할 수 없습니다.
때문에 본 논문에서는 Multi GPU를 효율적으로 사용하는 방법에 대해서 제안하고 있습니다.
Overview

(a)는 single GPU를 사용하는 기존 3DGS모델입니다. 16x16 Tile단위로 분할 해서 Gaussian을 병렬처리하게 됩니다.
(b)는 제안하는 방식입니다. 크게 3가지 부분으로 구성되어 있습니다.
- Gaussian-wise Parallelism : individual 3D Gaussians을 balance하게 분산 처리
- Pixel-wise Parallelism : individual output pixels을 balance하게 분산 처리
- All-to-all Communication : Gaussian-wise 와 Pixel-wise 간의 switching 처리
논문에서 언급한 contribution으로는 1) 3DGS모델에 대해 Scalable, memory-efficient, adaptive distributed training system 을 구축했고 2) High-resolution, large scale scene rendering을 가능하게 했다는 점입니다.
3D Gaussian Splatting의 특징
특징1)
기존 3DGS는 Rendering 단계에서만 Parallel Computation을 수행합니다. Gaussian transformation 단계, loss calculation 단계에서도 Parallel 연산의 여지가 있습니다.
특징2)
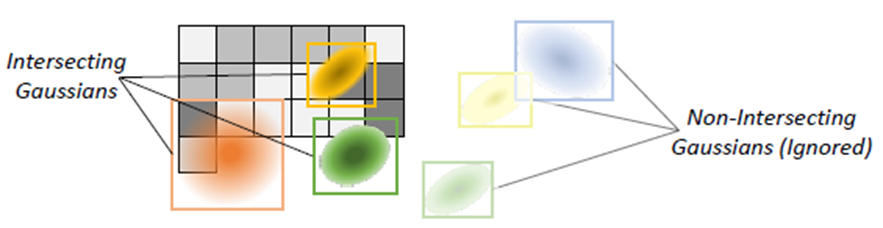
3D Gassian의 크기는 전체적으로 작습니다. image width의 2%보다 작은 반지름을 가진 3D Gaussian의 비율은 90%입니다.

x축은 Gaussian 반지름 나누기 이미지 너비이고, 이에 대한 누적 비율을 그린 그래프입니다. 이미지 width의 1%(=x축의 10^-2)의 약간 오른쪽에서 누적 비율이 90%(=y축0.9)인 것을 볼 수 있습니다. 때문에 3D Gaussian의 samll sbuset들로 하나의 pixel을 구성하게되며, 이로 인해 이웃 pixel의 gaussian간에 overlap이 많이 발생하게 됩니다.
특징3)
3D Gaussian의 개수는 영역마다 다르게 분포합니다. 일밙거으로 하늘 영역은 사람 영역보다 gaussian 갯수가 적게 되며, 이는 분산 처리시 computation workload imbalance가 발생하게 됩니다.
특징4)
기존 3DGS는 1번에 한개 이미지를 batch단위로 처리하게 됩니다. multi GPU사용시 parallel 연산에 효과적이지 못합니다.
제안하는 방법
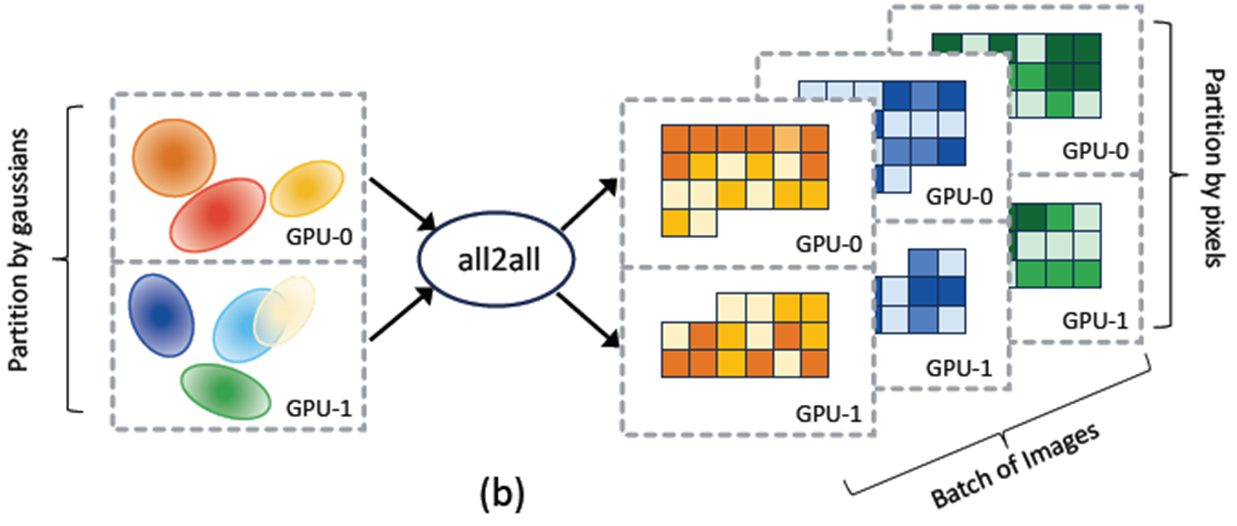
Gaussian-wise Distribution, all-to-all, Pixel-wise Distribution 그리고 Batched Training Hyperparameter 순서로 소개하겠습니다.
Gaussian-wise Distribution
Gaussian 단위로 분산처리는 간단하게 이뤄집니다. 일단 설계는 gaussian parameters와 optimizer states에 대해 partitioning을 합니다. 그리고 각 GPU에서 3D Gaussian transformation을 독립적으로 수행하게 했습니다. 단순히 Gaussian의 갯수단위로 uniform하게 분배를 하였고, computation unbalance는 발생하지 않았고 합니다. 그래서 GPU마다 할당가능한 최대 갯수를 적용 할 경우 학습속도가 linear하게 향상되었다고 합니다.
초기엔 3D Gaussian 갯수로 균등하게 분배를 하게 되고, 학습 과정중에는 Gaussian 갯수가 변하게되는 Densification 후에 재분배가 이뤄지게 됩니다.
Pixel-wise Distribution
rendering step과 loss computation step을 분산처리했습니다. 위에 언급한 3D Gaussian Splatting 특징2를 고려해서, GPU간에 transfer되는 gaussian의 개수를 줄이기 위해, 가능한 연속된 이미지 영역에 대해 동일한 GPU로 할당했다고 합니다. 16x16 pixel block읠 1개의 batch 단위로 두고, 아래에 알고리즘을 사용해서 여러 GPU로 Job을 할당했습니다.
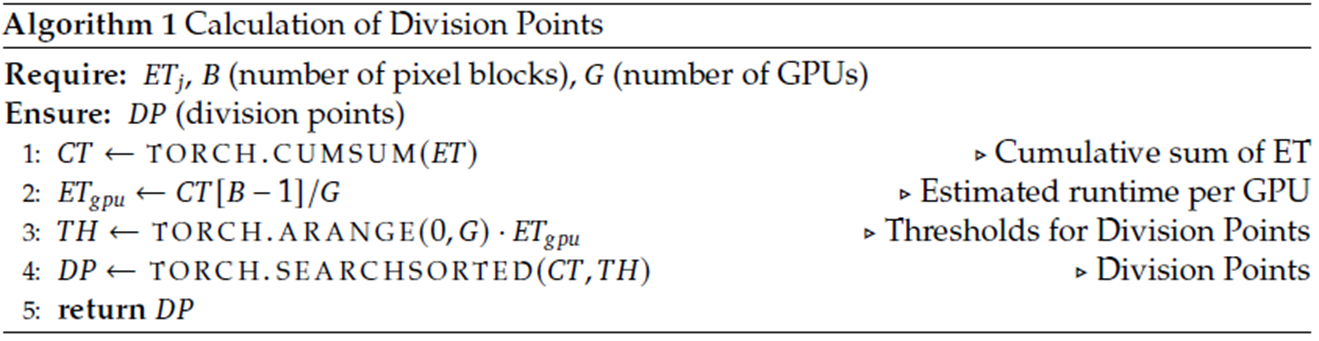
수도코드가 복잡하게 되어있는데, 한줄씩 설명하기 보다는 풀어서 설명하겠습니다. 이전 Epoch에서 각 GPU 수행시간을 기반으로 workload를 분배하는 방식입니다. 각 GPU마다 각 pixel에 대한 평균 연산시간을 계산하고, 모든 GPU의 pixel 평균 연산시간이 동일해지도록 재분배한다는 내용입니다.
Transferring Gaussians with sparse all-to-all communication
image pixel을 rendering하려면, pixel-wise process는 gaussian-wise process에 접근이 필요하게 됩니다. 학습 과정중에 3D Gaussian의 크기와 위치가 계속적으로 바뀌게 되므로 일정한 GPU로 할당 할 수가 없습니다. switching이 필요하며, 초기 학습단계와 gaussian transformation 후 단계에서 all-to-all communication을 수행합니다. 이 과정에서 속도를 향상시키기 위해 각 GPU는 intersect되는 Gaussian 집합을 미리 계산해둔다고 합니다.
Scaling Hyperparameters for Batched Training
3DGS는 Adam Optimizer를 1개의 batch로 사용하고 있습니다. 하지만 본 논문에서는 여러개의 batch형태가 됩니다.
1개의 batch를 사용하는 기존 방법과 동일하게 여러개 batch에서 Learning rate를 그대로 사용하면 unstable하고 inefficient하게 됩니다. 때문에 hyperparameter tuning이 필요로 하게됩니다. 이 값은 일반적으로 반복적으로 값을 바꾸면서 찾을 수 있는데 그러면 너무 시간이 오래걸립니다. 본 논문에서는 최근 연구를 바탕으로 수식화하게 됩니다.
이를 이해하기 위해 먼저 Adam Optimzer를 소개하겠습니다. ML분야에서 많이 사용하는 Optimizer입니다.
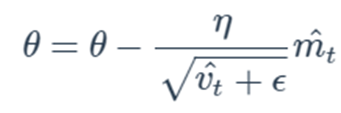
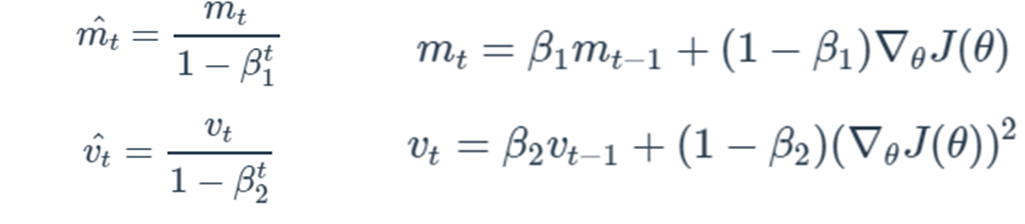
모델 parameter θ를 업데이트하는 수식은 learning rate η와 gradient ▽J(θ)에 대한 수식으로 이뤄져있으며, momentum m과 velocity v와 대해 지수이동 평균을 계산하는 형태로 되어 있습니다. 여기서 이전 momentun과 이전 velocity의 가중비율을 β1, β2로 조절하게 되어 있습니다. 여기서 η, β1, β2가 Adam optimizer의 hyperparameter에 해당하게 되며, 본 논문에서는 "Surge phenomenon in optimal learning rate and batch size scaling, arxiv2024" 연구를 참조해서 아래 수식으로 batch size에 따른 hyperparameter 선택을 제안하고 있습니다.
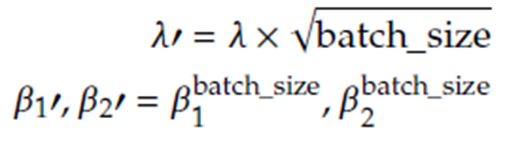
λ는 learning rate를 다르게 표현한 기호이고, β1'는 β1의 batch_size제곱입니다. 논문에서는 해당 수식에 대한 증명과정을 설명하고 있습니다. 그리고 실험으로 해당 수식에 대한 성능을 소개하고 있습니다.
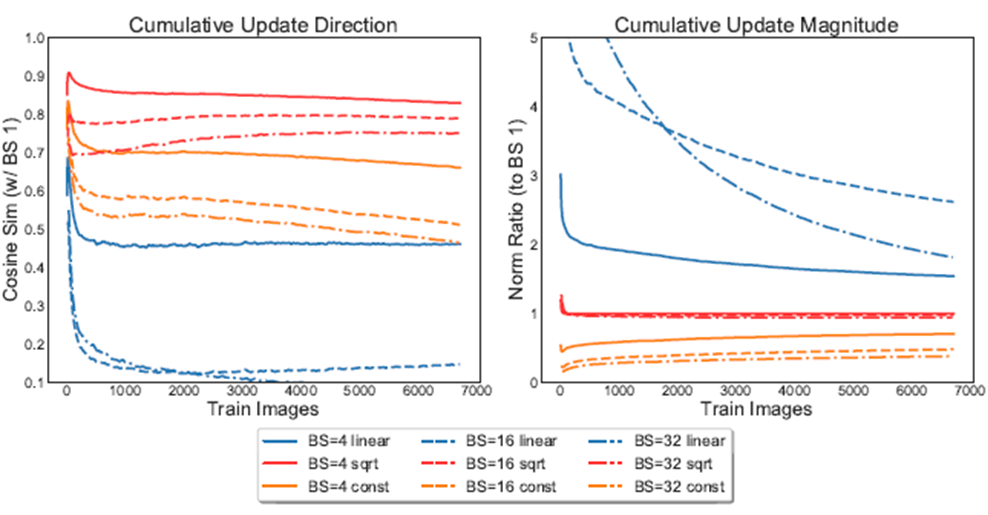
파란색은 learning rate를 batch size에 따라 leaner하게 증가 할 경우, 빨간색은 본 논문에 제안하는 방법으로 sqrt(batch_size)를 사용할 경우, 주황색은 그대로 사용할 경우로 나뉘어져 있으며, batch size가 1개 일 때 weight update 크기를 비교하였습니다. Cosine 유사도와 L2 norm을 계산하였으며, 값이 1일수록 기존의 기법과 유사하다는 뜻이며, 빨간색을 보면 iteration에 따라 일정하게 1로 유지되는 것을 볼 수 있습니다.
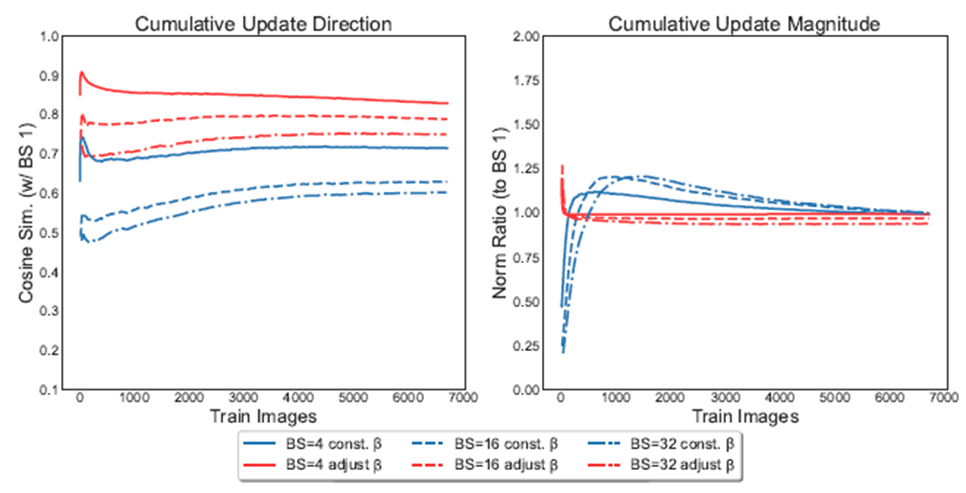
위 그래프는 β을 상수값으로 그대로 두었을 때 파란색과 batch size에 따라 변화 시켰을 때 빨간색에 대한 실험입니다. 이 또한 1에 가깝게 유지하는 것을 볼 수 있습니다.
Evaluation
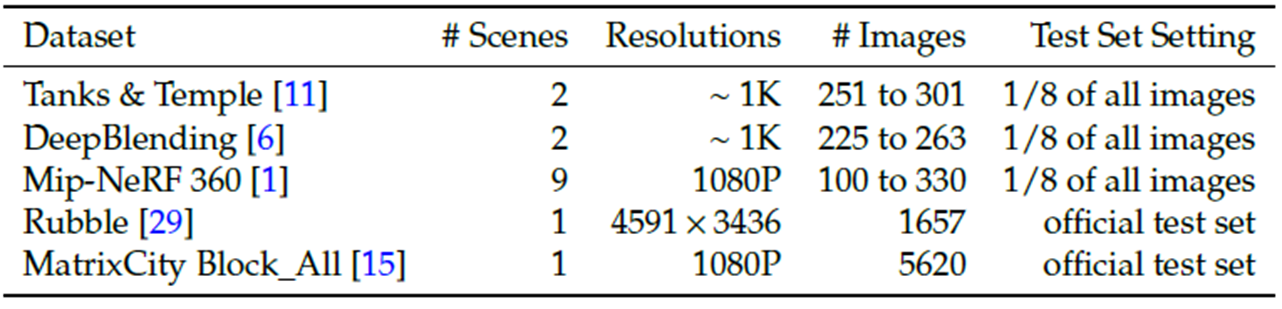
A100 GPU(40GB) x 4개를 NVLink(25GB/s)해서 5가지 데이터셋을 평가했습니다. Tanks & Temple, DeepBlending, Mip-NeRF360은 기존 NeRF, 3DGS에서 사용하는 작은 데이셋이며, Rubble, MatrixCity는 이미지수와 해상도가 높은 데이터셋입니다.
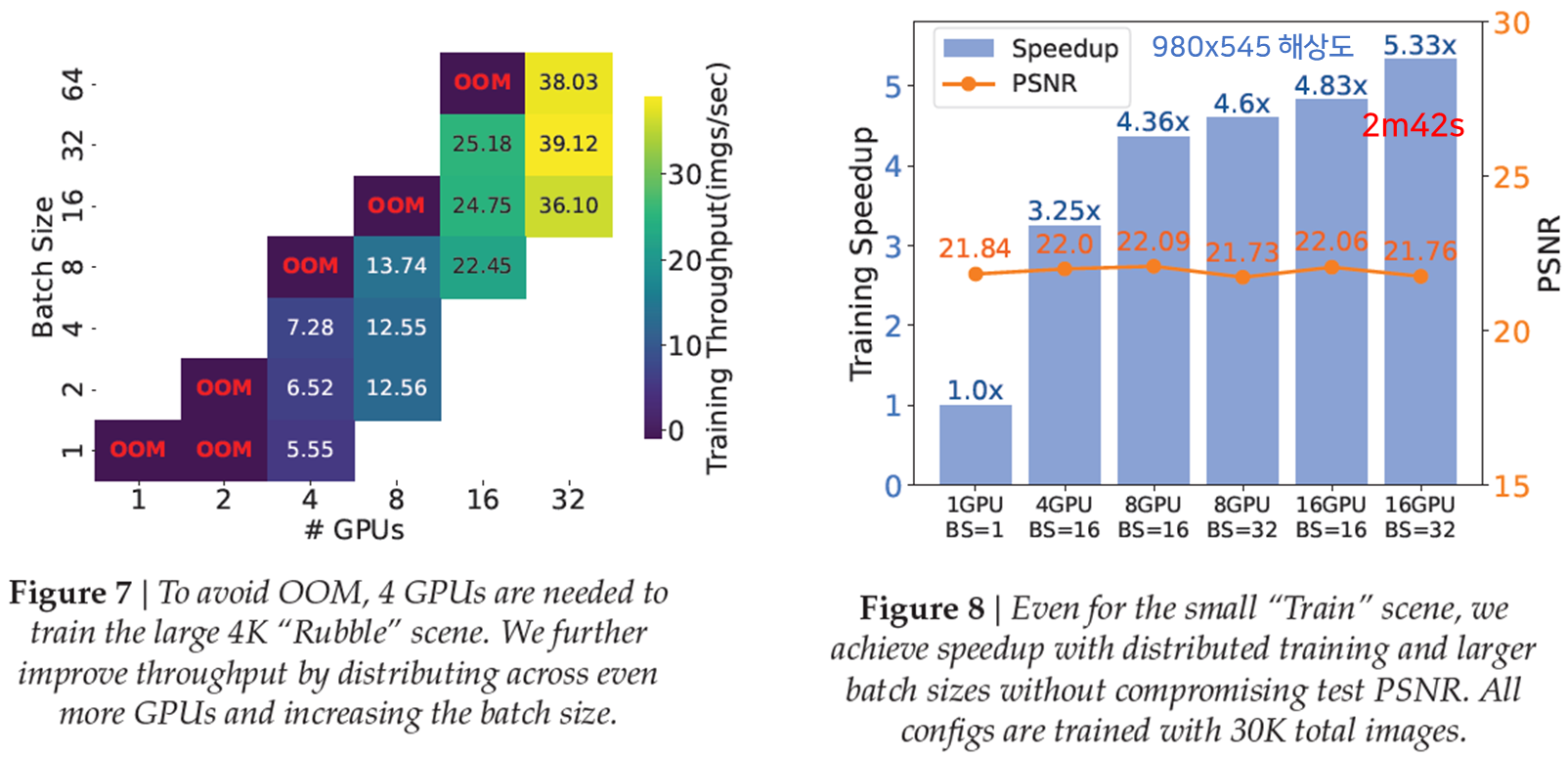
Fig7은 GPU갯수에 따른 최대 Batch Size수와 Throughput실험결과입니다. Rubble Scene에 대해서 학습시 GPU가 4개 이상이 있어야 학습이 가능했고, 초당 이미지 처리수는 batch size에 따라 증가하는 것을 볼 수 있습니다.
Fig8은 GPU 갯수, batch size에 따른 속도와 퀄리티입니다. 980x545해상도의 작은 데이터수인 "기차"데이터셋을 학습했으며, 4개 GPU로 16batch size를 가지게되면 3.25배 증가하고, 8개 GPU를 사용할 경우 4.35배 증가합니다. 그 후에 GPU와 batch size가 증가함에 따라 큰 차이는 없습니다. PSNR은 모든 경우에 큰 차이가 없습니다. 가장 오른쪽에 16GPU로 batch size가 32인 경우 속도가 2분42초로써 현재, 저자가 아는 범위내에선 발표된 기법 중에 가장 빠른 성능을 달성했다고 합니다.
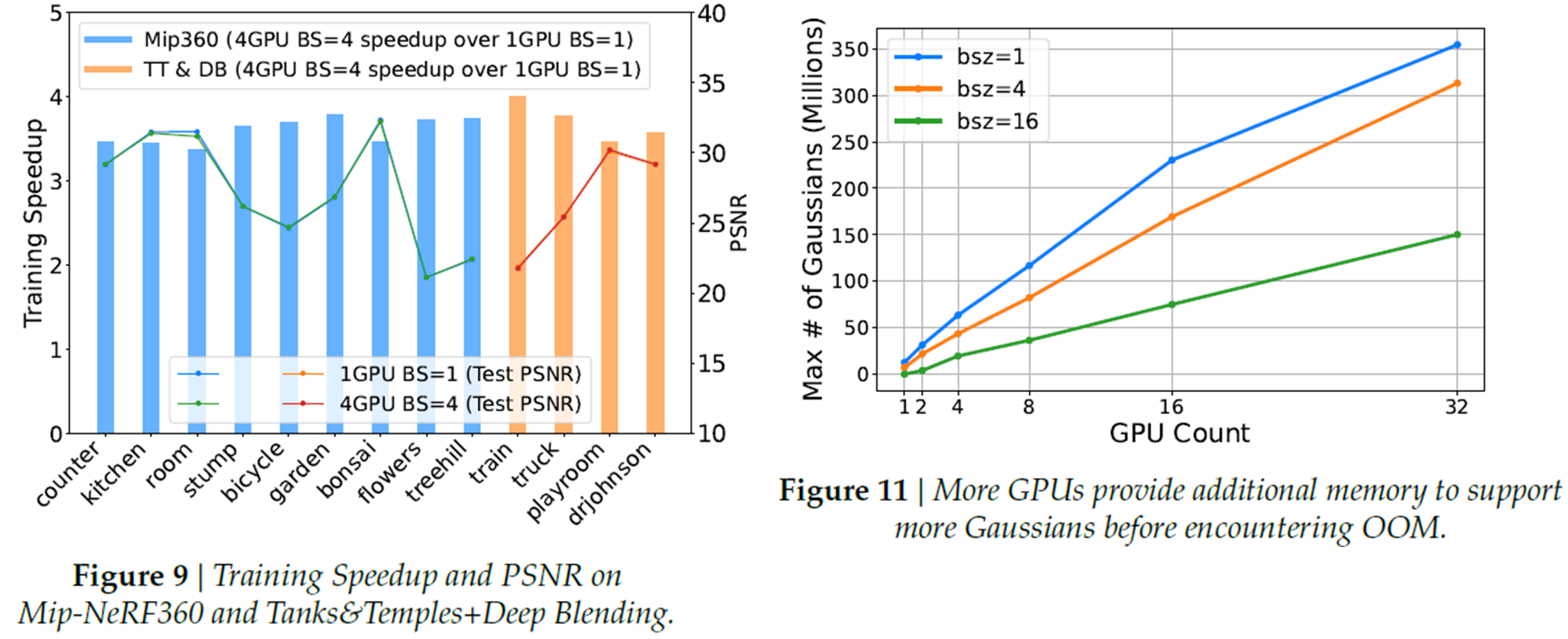
Fig9는 적은 이미지수를 가진 데이터셋에 대해, 1개 GPU로 1개 Batch size사용 대비 Multi GPU에서 4개 Batch size로 training한 성능 비교입니다. 속도가 4배로 증가함을 알 수 있습니다.
Fig11은 GPU갯수에 따라 최대 Gaussian 갯수를 측정한 것을 보여줍니다. linear하게 증가하는 것을 볼 수 있습니다.
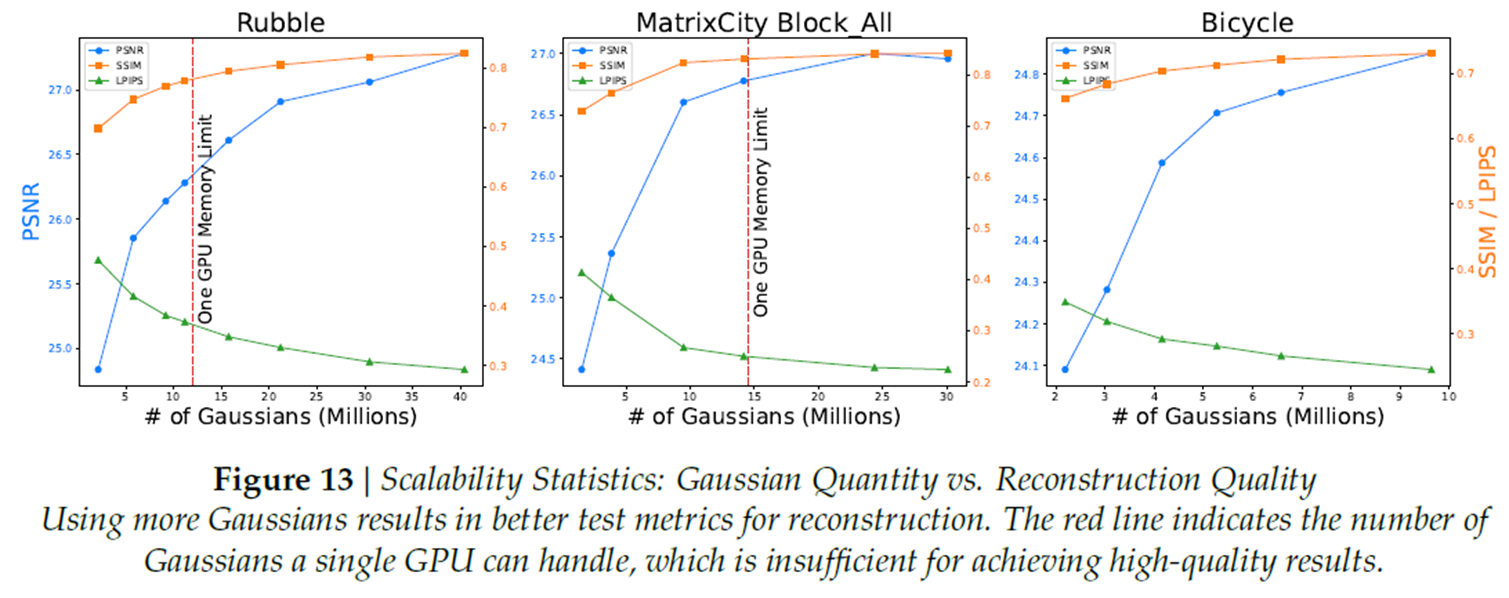
Fig13은 문제정의 부분에서 언급드렸던, 3D Gaussian 갯수 증가에 따른 PSNR 증가를 보여줍니다.
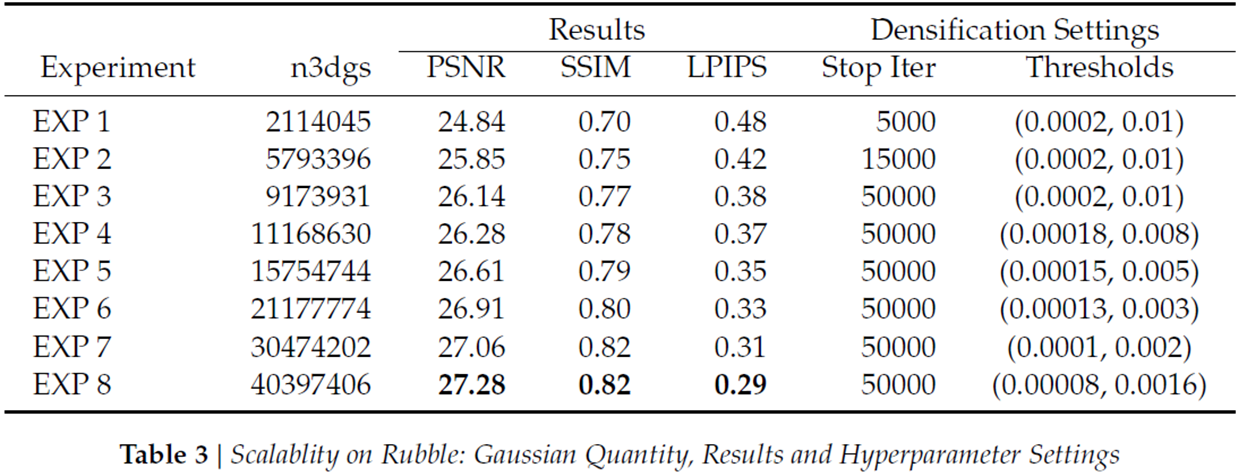
구체적으로 위 표를 보면, 3DGS갯수가 적고 많음에 따라 2.5정도의 PSNR차이가 발생함을 볼 수 있습니다.
Ablation Study
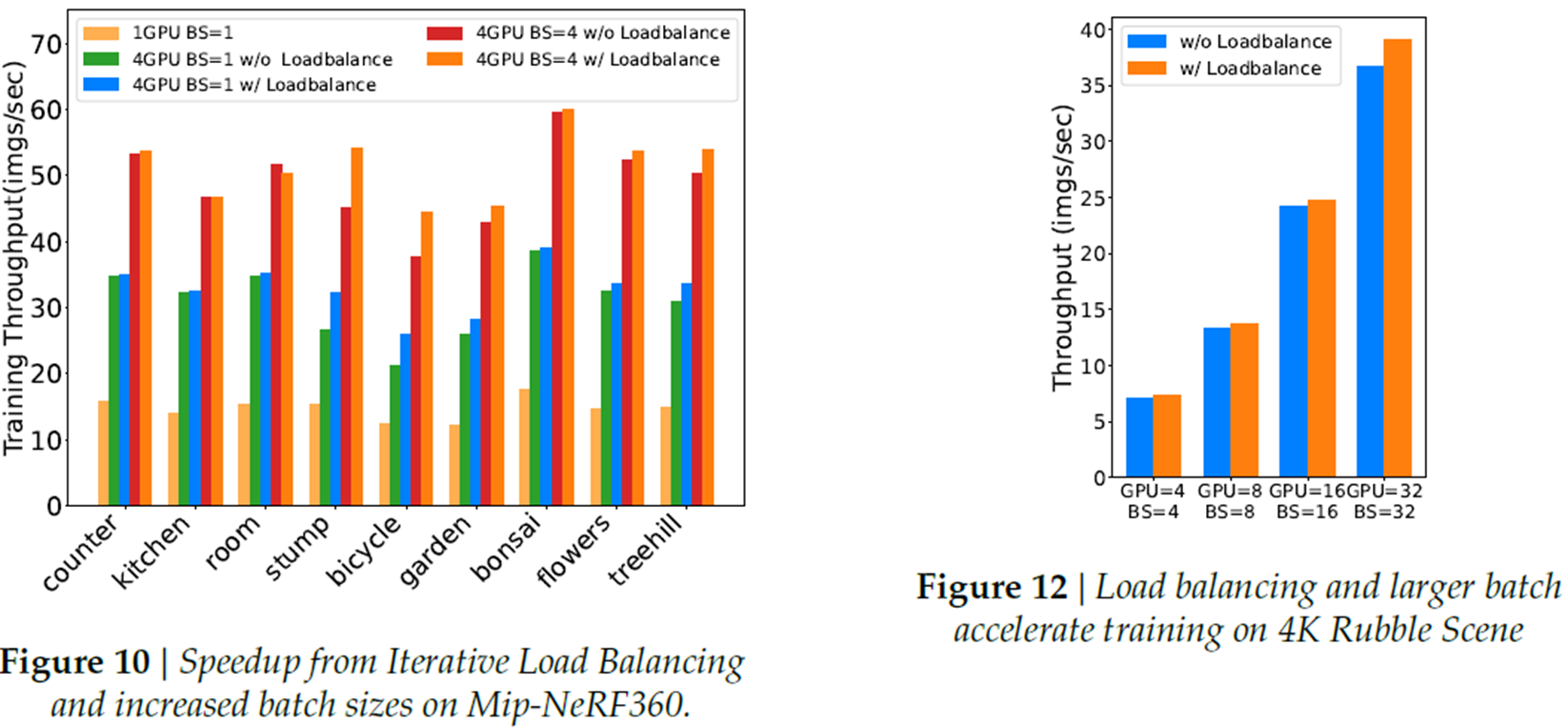
pixel-wise distribution에서 설명했던, 이전 epoch의 연산량을 재분배하는데 사용했다는 내용이 loadbalance에 해당합니다. 이부분에 대해선 실험적으로 약간의 성능 개선이 있었다고 합니다.
Closing..
GPU가 많아지면 그만큼 속도가 개선될 것이라 기대를 하게되는데, 3D Gaussian Splatting모델은 그렇지 않다는 것을 볼 수 있었습니다. 그리고 Multi GPU를 사용할 경우 문제점과 해결방안에 대해서도 알 수 있어, 3DGS모델을 좀 더 자세히 알아 보기에 좋은 논문이었다고 생각합니다. 논문 공개와 동시에 코드도 공개(code) 되어 있습니다.
'3D-GS' 카테고리의 다른 글
| [논문 리뷰] 3DGStream (CVPR 2024) : Free-view Video 생성 (0) | 2024.09.08 |
|---|---|
| [논문 리뷰] Scaffold-GS (CVPR 2024) : MLP기반 3DGS (4) | 2024.08.25 |
| [논문 리뷰] Mip-Splatting (CVPR2024) : Anti-aliasing 기법 (0) | 2024.07.28 |
| [논문 리뷰] PhysGaussian (CVPR 2024) : 물리 기반 변형 (3) | 2024.07.13 |
| [논문 리뷰] VastGaussian (CVPR 2024) : Large Scene (0) | 2024.06.17 |




댓글