아바타 얼굴을 고퀄리티로 realtime수준의 편집 및 랜더링하는 기법입니다.

mesh와 texture로 구성된 3D avatar face asset을 3D Gaussian Splatting로 모델링(GauFace)하고, 외부 조명 및 텍스처를 real-time으로 변경 할 수 있는 모델(TransGS)을 제안하고 있습니다.
기존 방법론 및 문제점
실제 사람과 같은 얼굴을 생성하는 production level의 workflow는 크게 모델링과 랜더링으로 나눌 수 있습니다.
- 모델링의 경우 face asset 생성, UV unrapping, physical기반 appearance(e.g diffuse albedo, specular inttensity, roughness, normal map, displacemnet)과 motion rig(=뼈대와 mesh붙이는작업)이 필요로 합니다.
- 랜더링의 경우 대부분 GPU기반의 rasterization pipeline을 사용하게 되며, 세부적으로 offline render와 online render로 나눌 수 있습니다.
- offline render는 Arnold, Cycles같은 툴을 사용하며, ray tracing 계산을 사용해서 현실감은 높이는 대신, 랜더링 속도가 느립니다. 영화에서 볼 수 있는 CG아바타 얼굴을 랜더링 할 때 사용되는 기법입니다.
- online render는 Unity, OpenGL 같은 툴을 사용하며, 실시간 랜더링이 가능하지만, 랜더링 퀄리티가 낮습니다. 게임에서 볼 수 있는 기법입니다.
최근에 발표되고 발전 중인 3D Gaussian Splatting(3DGS)의 경우 속도와 랜더링 퀄리티 면에서 우수하며, GPU기반의 rasterization pipeline에 통합이 용이하고, dynamic scene 확장하는 연구도 활발하게 진행되고 있습니다. 단점으로는, 얼굴 랜더링 및 편집에 쓰기엔 scene별 training이 필요로하며, CG face asset에 바로 적용해 렌더링 품질을 향상시키기 어려운 문제가 있으며, 데이터 준비와 최적화 과정이 interaction이 필요한 application이 실용적이지 않으며, 조명/온라인 편집/애니메이션 제어 지원이 어렵습니다.
본 논문에서는 3D Gaussian Splatting(3DGS)를 사용해서 아바타 얼굴을 고퀄리티로 생성하면서, 얼굴 모양 변경, light 환경에 따른 랜더링 등과 같은 편집을 빠르게 하는 방법에 대해서 제안하고 있습니다.
Overview

PBR facial Assets이 주어진다는 가정으로 시작합니다.
GauFace 모델에서는 주어진 asset을 Gaussian splatting model로 Rigging합니다. mesh와 3D Gaussian을 mapping한다고 생각하면 편할 것 같습니다. 이 과정중에 Dynamic shadow vector, pixel-aligned sampling, Deferred pruning 과 같은 기법들을 사용하게 됩니다.
TransGS 모델에서는 다양한 lightning condition 또는 texture 변화에 따라 아바타를 수정합니다.
학습 데이터셋
PBR(Physically-Based Rendering) Asset은 geometry mesh, image textures(=diffuse map, normal map, specular map), expression blendshapes로 구성되어 있습니다. mesh와 texture는 많이들어보셨을텐데, blendhshape라는 용어를 간단하게 설명하자면, 표준 얼굴을 기준으로 특정 계수(coefficient)를 조정해서 얼굴의 shape(생김새)을 바꾼다던가 expression(표정)을 바꿀 수 있게 만든 모델입니다. 논문에서는 이 Asset을 DreamFace(SIGGRAPH 2023)를 사용했다고 합니다.
facial asset은 143개입니다. 구체적으로 5개의 부위(foreface, backhead, teeth, lefteye, righteye)로 나뉘어져 있으며, 각 texture map은 4k resolution으로 구성되어 있습니다.
lighting condition의 경우 134개로 구성했으며, 조합해서 1023개로 만들었다고 합니다.
GauFace

각 아바타(=143개)는 각 lightning combination(=134개)별로 1개의 3DGS모델을 학습하게 됩니다. 이 때 표정은 153개를 사용하고 7개의 view point를 사용합니다. 때문에 1개 scene당 1071(=153x7)개 이미지로 3DGS모델을 학습합니다. 표정이 다른데 3DGS를 만들 수 있는가 의문이 들었는데, 이 부분은 Gaussian Splatting을 아래와 같이 설계했기 때문에 가능하게 됩니다.
3D mesh와 mapping되어 있는 2D texture uv map을 기준으로 모델링됩니다.

$\mu$는 texture map의 uv map 좌표입니다. u와 v로 구성되어 있습니다.
$d$는 해당 uv 좌표에 대응되는 mesh surface를 참조하여, 해당 mesh surface와 떨어진 거리입니다. mesh의 triangle에 수직인 normal 값에 곱해집니다.
$s, \theta$ 는 간단하게 3D gaussian의 scale과 rotation입니다. 논문에서는 좀 더 복잡하게 설명되어 있긴합니다.
$\sigma$는 3D gaussian의 opacity입니다.
$c$는 Spherical Harmonics로 표현된 color값입니다.
$l$은 dynamic shadow vector입니다. 그림자 변화를 blendshape로 만들어둔 vector값입니다.
uv map은 4K 해상도라고 했었는데, 이를 다 학습하는게 아니라, 일정 간격으로 point를 균등하게 사용했다고 합니다. foreface의 경우 10pixel간격, 그 외는 16pixel간격으로 사용했습니다. 그래서 228,083개의 일정 갯수의 3D gaussian 수를 유지 할 수 있었습니다.
이렇게 모델링이 되면 얼굴이 변화되더라도 특정 3D Gaussian은 mesh에 d거리만큼 떨어져있기 때문에 학습이 가능해지게 됩니다. 3DGS와 동일하게 30,000번 학습했다고하며, 1개 scene당 30분정도 소요됬다고 합니다.
이 과정을 아바타(=143개) x lightning combination(=134개) 만큼 반복해서 학습해서 GauFace Asset을 만들었습니다.
TransGS

Diffusion 모델을 기반으로 조명과 texture변화에 따라 3D모델을 변형하는 TransGS 기법을 제안하고 있습니다.
Stable Diffusion을 아는 분들은 위 그림보다 아래 그림으로 설명하는게 이해하는데 편할 것이라 생각됩니다.

x는 3D gaussian입니다. (추가적으로 얼굴의 geometry를 다루는 Geometry Code가 들어갑니다. 얼굴 형상을 나타내는 blend shape가 아닐까 싶습니다.) denosing process를 통해서 3D gaussian을 생성합니다.
condition은 texture map과 lightning입니다.
각각은 linear layer를 통해 encoding되어 token화되고 Transformer로 학습되게 됩니다. 이 모델이 학습이 되면, condition이 바뀌는 경우 condition에 따라 3D gaussian이 변형되어 생성되어지게 됩니다.
Diffusion 모델에 이미지 입/출력이면 모르겠는데 3D Gaussian을 어떻게 입력으로 넣었는가에 대해서 궁금증이 생기는데, 이부분을 저자는 또다시 texture map을 사용하고 있습니다. texture map을 overlap 없이 (1/256, 1/256) patch로 만들고, 각 patch에 mapping되는 3d gaussian들을 batch형태로 사용합니다. 이에 상응하는 texture map의 patch를 condition으로 넣고 있습니다. GauFace Asset에는 texture map과 3D mesh, 3D gaussian이 모두 mapping되어 있기에 가능합니다.
Loss
이 TransGS모델 학습시 랜덤하게 patch를 샘플링해서 사용하게 되며, Loss를 main stage, fine-tuning stage로 구분해서 사용하고 있습니다. main stage Loss는 입력 gaussian에 대해서 noising, denosing 후에 동일 여부를 체크하는 Loss입니다.

$A$는 입력 gaussian이고 $A^t$는 noising된 guassian, $M$은 denosing process에 해당합니다.
fine-tuning stage Loss에서는 생성한 이미지와 실제 이미지와의 Loss를 계산합니다.

$R$은 랜더링을 의미하며, *은 예측한 모델을 의미합니다. pixel간의 L1 Loss와 SSIM Loss를 계산하고 있습니다. main stage loss는 800epoch를 학습하고, finetune loss는 100epoch를 학습했습니다.
UV Positional Encoding
간단하게 생각해서 UV Map의 좌표를 NeRF의 Positional Encoding처럼 MLP입력 할 때 입력값의 feature를 늘여준다고 생각하면 됩니다. 이 부분은 u,v 좌표를 그대로 쓰지않고 patch단위로 patch의 시작점을 0,0으로 보고 좌표값을 계산하면서, relative positional encoding을 하고 있습니다.
학습 시간
학습시 diffusion step으로 100회로 두고, inference시 10회로 두었다고 합니다. 학습시엔 random patch로 샘플링 했지만, inference시엔 all patch를 사용했다고 합니다.
학습은 Foreface의 경우 8개 RTX4090으로 5일이 소요되었고 다른 얼굴 부위는 1개 RTX4090으로 하루 소요되었습니다.
실험결과
TransGS까지 적용된 GauFace 퀄리티입니다.

facial rendering하는 volume rendering pipeline을 적용한 최신 연구 Instant volumetric head avatars(2023)의 결과들과 비교하였습니다.
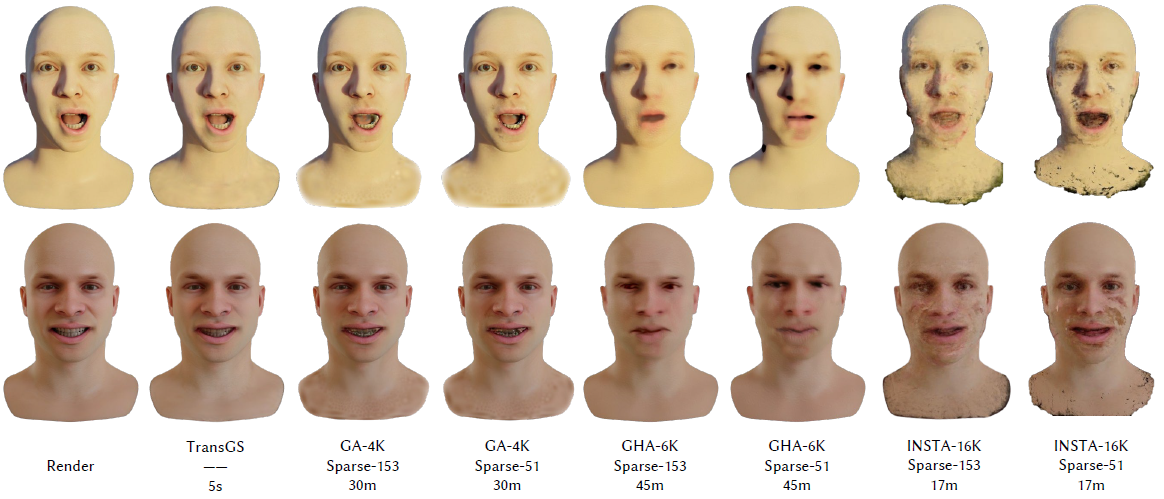
Blender, Unity3D에 내장된 rasterization기반 엔진보다 빠르게 랜더링하는 것을 보여줍니다.

그 외 실험결과는 https://dafei-qin.github.io/TransGS.github.io/ 에서 영상으로 보실 수 있습니다.
논문에서 언급된 속도에 관해서 정리해보자면, 이렇게 정리 될 수 있을 것 같습니다.
- mesh+texture asset 주어질 경우 3D Gaussian화(GauFace) 하는 속도 : 30분 (RTX4090 x1)
- 3D Gaussian Asset으로 3D Gaussian 변형하는 diffusin 모델 학습 속도 : 5일 (RTX4090 x8)
- 3D Gaussian Asset에 조명 변화, 텍스쳐 변화 속도 : 5초 (RTX4090 x1)
- 3D Gaussian Asset에 표정 변화 : 언급없음. blend shape만 변화하면 되므로 10ms이내?
- 표정/조명/텍스쳐 변화 완료된 상태에서 랜더링 : 100FPS이상
Closing..
PBR Asset 구축 전제 조건이 충족되어야 하는 연구이지만, 고퀄리티와 realtime랜더링이 된다면 많은 application에서 사용 될 수 있을 것 같네요. 3D Gaussian을 mesh로 만드는 연구들이 많았는데, mesh를 3D Gaussian으로 만드는 연구라 흥미가 있었습니다. 충분한 시간을 들여서 논문을 읽지 못해 잘못되거나 부족한 부분이 있을 수 있습니다. 알려주시면 보완하도록 하겠습니다.
'3D-GS' 카테고리의 다른 글
| [논문 리뷰] Long-LRM (arXiv 2024) : 3DGS 학습 1.3초 (0) | 2024.12.16 |
|---|---|
| [논문 리뷰] MesonGS (ECCV 2024) : 3D Gaussian 경량화 (1) | 2024.10.06 |
| [논문 리뷰] 3DGStream (CVPR 2024) : Free-view Video 생성 (0) | 2024.09.08 |
| [논문 리뷰] Scaffold-GS (CVPR 2024) : MLP기반 3DGS (4) | 2024.08.25 |
| [논문 리뷰] Grendel-GS (arXiv2024) : Multi GPU로 3DGS (0) | 2024.08.10 |




댓글