[논문 리뷰] DiffusionGS (arXiv 2024) : Single Image-to-3D
이미지 1장으로 3D를 6초만에 모델링하는 연구에 관한 내용입니다. 기존 연구 대비 퀄리티가 상당합니다.
아래 그림은 Prompt View 이미지 1장으로 3D 모델을 생성한 예시입니다. Novel View1, 2는 생성된 3D모델에 카메라 포즈를 바꿔 랜더링한 이미지입니다. 프로젝트 페이지(link)에서 입체적으로 더 다양한 예시를 보고 오시길 바랍니다.

Scene입력도 가능합니다. 위에 작은 이미지는 입력 이미지이고 아래 큰 이미지는 3D로 모델링된 결과물입니다.

본 논문의 이름 DiffusionGS는 제목 그대로 Diffusion Model과 3D Gaussian Splatting(3DGS)를 사용하여 Single Image-to-3D모델을 제안하고 있습니다. 어떤 원리로 만들어졌는지 하나씩 알아가보겠습니다.
Overview
본 논문의 핵심은 image-to-3D에서 일반적으로 사용하는 diffusion 모델로 noise를 예측하는 방법이 아닌, view consistency를 높이기 위해 diffusion 모델로 3D gaussian을 예측하도록 설계했다는 점입니다. diffusion denosier는 각 pixel마다 3D Gaussian을 직접적으로 예측합니다.

Train시 1개의 clean view와 N개의 noisy view를 사용합니다. novel view는 사용하지 않습니다.
Inference시 1개 clean view는 diffusion모델의 condition으로 사용되어 1장의 입력으로 임의 N개 카메라 포즈의 noisy view를 통해 3D Gaussian을 예측하여 scene을 구성합니다. 그리고 novel view 카메라 포즈에서 랜더링합니다.
Related Works
Diffusion 모델로 3D 모델을 생성하는 4가지 방법과 문제점을 언급하고 있습니다.
- point cloud 또는 mesh형태의 3D model를 supervision(지도 학습)
→ 현실 데이터 획득이 어려움 - 3D모델을 2D diffusion으로 distill하기 위해 SDS Loss(이전글)를 사용 (DreamGS 이전글)
→ scene마다 optimization하기에 많은 시간이 소요 - 2D diffusion모델에 condition으로 camera pose를 추가해서 사용 (12345++ 이전글)
→ 3D consistency(일관성)을 보장하기 어렵고, query camera pose변화시 collapse발생(=퀄리티 감소) - 2D diffusion이 아닌 3D diffusion model을 학습
→ 3차원 학습으로 인해 volume rendering 속도가 느림
그 외 현재 연구들의 학습 데이터 문제도 지적하고 있습니다.
- 배경이 없고 사물에 중심에 위치해있는 object-centric dataset을 사용
→ generalization ability(=학습에 사용되지 않는 도메인을 처리 능력)감소
→ larger-scale scene generation 퀄리티 감소 - 적은 viewpoint change(=카메라 pose 차이)로 구성됨
→ geometry를 표현하기에 충분치 않음 - 대부분 합성한 데이터
→ 현실을 잘 모델링하지 못함
Input/Output Design

$\mathbf{x}_{con}$은 clean view의 이미지를 나타내고, $\mathbf{v}_{con}$은 clean view의 카메라 pose를 나타냅니다. $\mathbf{x}_0^{(1)}$는 $ \mathbf{x}_{con}$과 다른 view point에서 clean한 view를 나타내며 차원은 동일합니다. diffusion process를 t번 수행하면 $\mathbf{x}_t^{(1)}$가 됩니다. 이 noisy view가 N개 만큼을 집합 $\mathcal{X}_t$로 표현했습니다. 이에 상응하는 view point는 $\mathcal{V}$입니다.
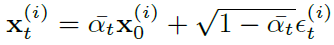
위는 diffusion forward process 기본 수식(이전글)입니다. alpha는 0~1사이의 hyper-parameter이고 ${\epsilon}_t^{(i)} \sim \mathcal{N}(0, \mathbf{I})$는 noise이며 일반적으로 diffusion의 denoiser는 ${\epsilon}$을 예측해서 2D image인 $\mathbf{x}_0$를 생성하지만, 여기선 2D image가 아닌 3D Gaussians을 예측하게합니다.
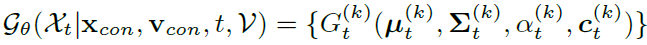
$\mathbf{x}_{\text{con}}, \mathbf{v}_{\text{con}}, t, \mathcal{V}$가 주어질 때, noisy한 $\mathcal{X}_t$을 만들어내는 모델은 각 pixel마다 Gausian $G_t^{(k)}$의 집합을 생성합니다.
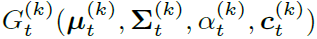
3D Gaussian(이전글)의 4개의 parameter는 각각 gaussin의 중심 position, 모양에 관한 covariance, transmittance, RGB color으로 구성됩니다.
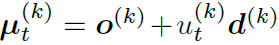
o는 카메라의 중점, d는 방향을 나타내는 direction, u는 깊이를 나타냅니다. 다시 u는 hyper-parameter near, far에 대한 weight w로 구성됩니다.
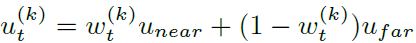
결론적으로 $\boldsymbol{\mu}_t^{(k)}$는 ${w}_t^{(k)}$를 제외하곤 고정된 값이기 때문에, ${w}_t^{(k)}$를 예측하는 모델로 보면됩니다. covariance와 transmittance는 기존 3DGS와 동일하고, color의 경우 SH efficient가 아닌 RGB채널별로 예측하는 모델이 됩니다.
Denoiser Architecture
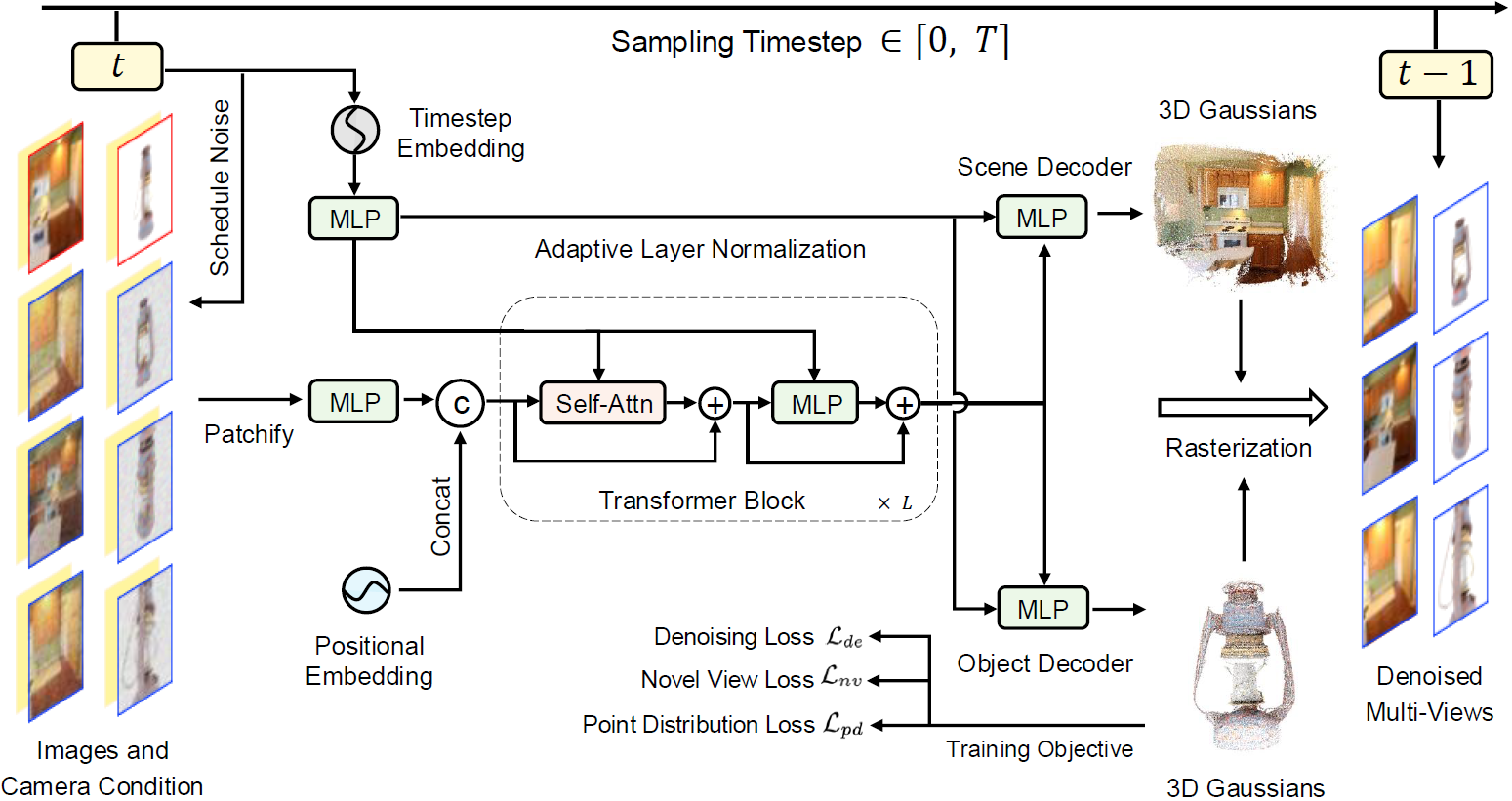
빨간색은 clean한 condition image이고, 파란색은 timestep t까지 noise가 주입된 image입니다. 각 이미지 뒤에 노란색은 카메라 pose를 나타내는 viewpoint position입니다.
backbone은 Vision Transformer 아키텍처를 따릅니다. 1개의 이미지를 일정 크기의 grid형태로 나누는 patchify를 진행한 후에 MLP를 거쳐 token화 시켜줍니다. grid내 이미지의 position 정보를 전달해주기 위해 positional embedding 값을 concat해주게 되며 추가적으로 timestep도 embedding하여 Transformer block의 입력으로 넣어주게됩니다.
transformer의 결과값은 MLP형태의 (Scene, Object) Decoder를 거쳐 3D Gaussian의 parameter를 생성합니다. 그리고 3D Gaussian Rasterization을 통해 랜더링한 image를 만듭니다.
Train시에는 결과값과 noise를 넣기전의 원본 image간의 rendering loss를 계산하여 denoiser의 weight를 update합니다. Inference시에는 빨간색은 한장의 clean한 query image가 되고 파란색 부분은 임의의 포즈를 가정한 noisy한 image가 됩니다.
아래는 Train시 사용되는 visual loss입니다.
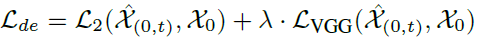
정리하자면, 앞에서 언급하였던데로 기존 diffusion 모델의 denoiser는 noise image를 직접적으로 clean한 image로 만드는 pixel의 차이값을 예측하는 모델이었다면, 해당 논문의 diffusion 모델의 denoiser는 noise image를 3D Gaussian으로 랜더링한 image를 만들기 위해 3D Gaussian을 예측하게끔 만들었습니다.
Scene-Object Mixed Training Strategy
Scene과 Object를 적절히 혼합하면서 training 방법을 소개하고 있습니다. 위 related work에 언급한 기존 데이터의 문제점을 해결하기 위해, scene level 데이터셋을 사용했습니다. scene level 데이터셋은 range와 depth가 폭 넓고 camera viewpoint의 분포가 연속성인 궤적을 만들게 됩니다. 예를 들어 물체를 중심으로 앞/뒤 또는 좌/우 panning하여 움직입니다. 데이터셋마다 다른 viewpoint를 가지기 때문에 논문에서는 viewpoint의 분포를 제약하는 전략을 취하고 있습니다. 아래 좌하단 view distribution 부분이 제약된 카메라 view를 나타내는 것으로 보입니다.
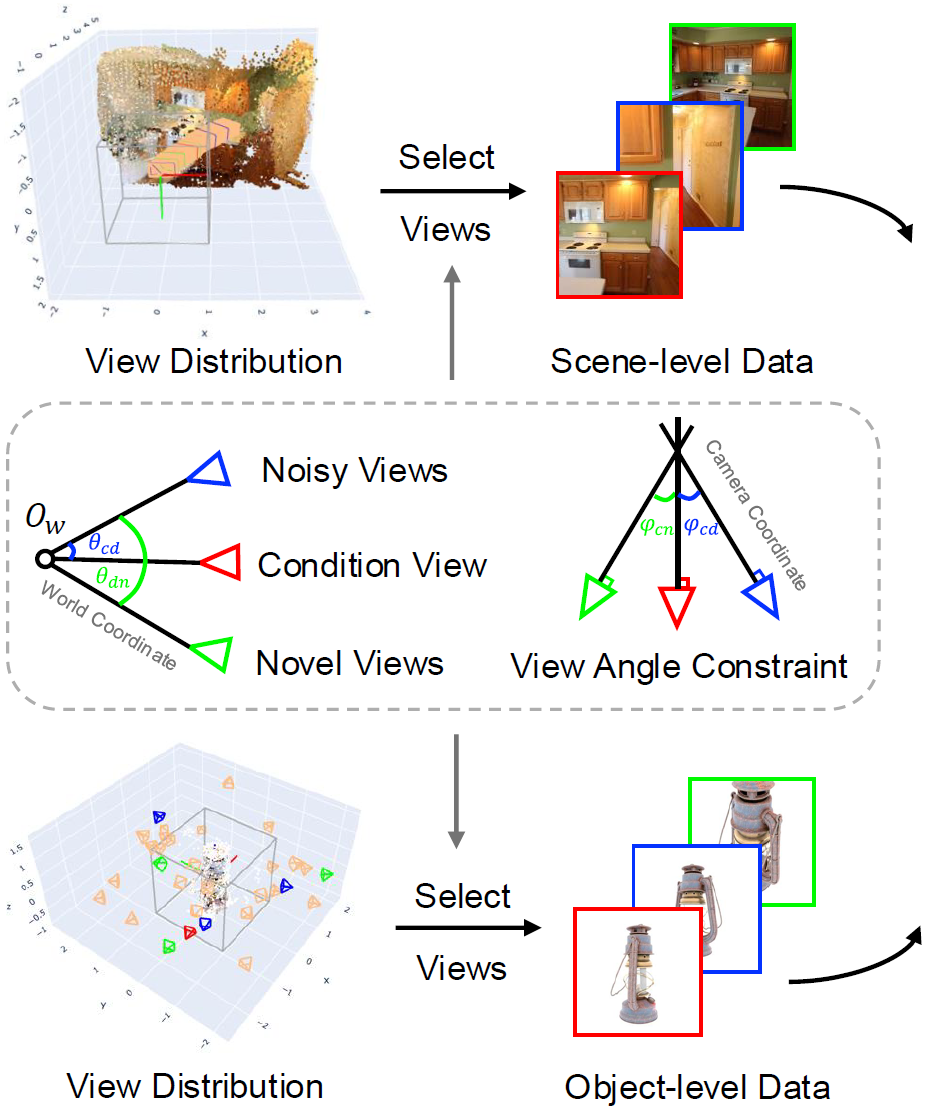
Viewpoint Selecting
점선 사각형 부분을 보겠습니다. 앞서 overview에서 설명했던데로 condition view는 clean한 1장의 이미지이고 noisy view는 다른 카메라 포즈를 가정한 noise가 주입된 이미지입니다. novel view는 noisy view와 condition view로 만들어진 3D Gaussian들을 바라보는 새로운 카메라 pose로 랜더링된 이미지로 생각하면 되겠습니다.
학습시 빠른 수렴을 위해, camera 위치와 방향을 제약합니다. noisy view에서 부분적인 정보를 제공할 수 있기 때문에, noisy view를 기준으로 condition view와 novel view에 대한 위치를 특정 각도 이하로 제한합니다.
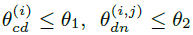
그리고 camera가 바라보는 방향인 orientation을 특정 각도 이상으로 제약합니다.
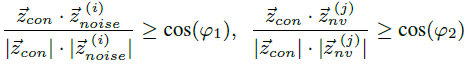
위 수식에서 con,noise,nv는 각각 condition, noise, novel view의 forward direction vector를 의미합니다.
Reference-Point Plucker Coordinate
camera pose condition을 제약하기 위해, 이전에 연구들은 pixel과 align된 ray embedding인 plucker coordinates를 사용했다고 합니다(아래 (a)에 해당합니다.) plucker coordinates(이전글)는 두개 점으로 직선을 표현하는 방법중에 하나입니다.
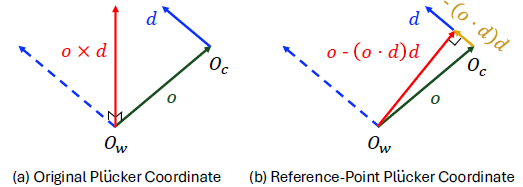
Ow는 world coordinate 좌표고, Oc는 camera coordinate 좌표입니다. o는 카메라의 위치를 나타내는 vector입니다. d는 카메라로 들어오는 ray의 방향(direction) vector입니다. o와 d가 같은 평면에 있을 때, o와 d의 외적인 o x d는 해당평면에 수직인 vector입니다. 카메라로 들어오는 ray d를 plucker coordinates로 표시하면, $$r = (o {\times} d, d)$$ 입니다. 이 표기법으로는 Oc카메라를 중심으로 상대적인 depth와 geometry의 변화를 인식하기가 어렵다고 합니다. (이유가 정확히 이해가 되진 않습니다.)
그래서 이 표기법을 customizing하여 Reference-Point Plücker coordinates(RPPC) 표기법을 제안하고 있습니다. 모멘트 벡터(o x d)를 world 좌표계의 원점과 가장 가까운 ray위의 point로 대체하는 방식입니다. $$r = (o − (o · d)d, d)$$ 이 방식은 ray의 위치와 상대 depth에 대한 더 많은 정보를 제공 할 수 있고, 3D scene과 object의 기하 구조를 포착하는데 있어 diffusion 모델에 적합하다고 합니다.
Dual Gaussian Decoder
object-level dataset과 scene-level dataset의 depth range가 다르다는 점에 착안하여, 사물의 near, far 범위를 구분하여 object-level을 다루는 MLP Gaussian decoder와 scene-level을 다루는 MLP Gaussian decoder로 구성하였습니다. object-level의 경우 [0.1, 4.2]의 범위로 두고 ${[-1,1]}^3$으로 clip합니다. scene-level의 경우 [0,500]으로 near,far을 설정하였습니다. 두개의 decoder를 동시에 학습한 후에, 추가적인 finetuning phase를 진행하면서 하나의 decoder만 사용하고 다른 decoder는 제거해서 사용합니다.
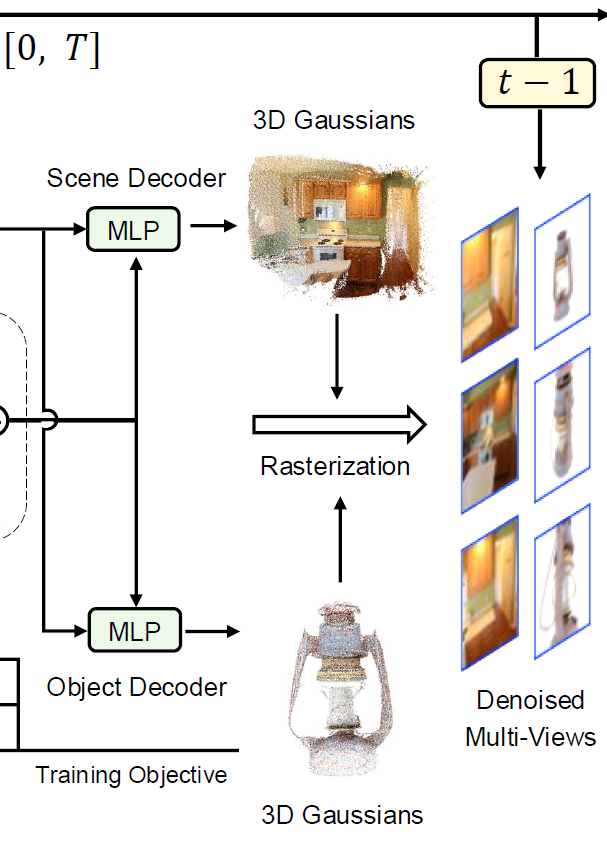
위 그림은 architecture 이미지의 일부분입니다. 오른쪽 이미지를 보면 scene과 obejct가 분리되서 랜더링 된 것을 볼 수 있습니다.
Overall Training Objective
Denoiser Architecture에서 언급한 visual Loss와 별도로, object-centric generation인 경우 3D point clouds의 분포가 더 집중되도록 하기 위해 학습 warm-up단계에서 point distribution loss를 설계했습니다.
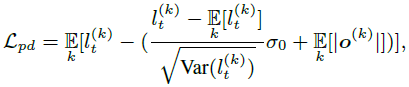
$l_k$는 distance와 direction의 곱으로 계산되는 깊이 값입니다. 시그마는 0.5로 셋팅했습니다. 정확한 설명이 나와 있지 않은데 point들이 더 멀어지지 않도록 해주는 Loss인 것으로 보입니다. 최종적인 Loss입니다.
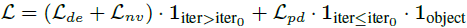
iteration이 1이상일 때, 앞서 설명한 noisy view로 계산한 visual loss인 $L_{de}$와 novel view로 계산한 visual loss인 $L_{nv}$ ($L_{nv}$설명은 안나와 있어 추측입니다.)를 사용하고, iteration 0일 경우 object-level에 대해서만 point distribution loss를 사용했습니다. iteration의 기준은 임의의 상수값이라 생각됩니다.
Experiments
Object 학습데이터
- Objaverse데이터셋에서 730K개 scene을 MVImgNet데이터셋에서 220K개 scene을 사용했습니다.
- center중심으로 x,y,z축을 -1,1 scale로 변형하고, 50 FOV로 32개의 랜덤이미지를 선택했습니다.
Object 평가데이터
- ABO, GSO데이터셋에서 1개 input view와 10개 test view를 사용했습니다.
Scene-level 학습/평가데이터
- RealEstate10K에서 실내/실외 80K video clips을 사용하고, DL3DV10K에선 96개 카테고리의 6.8K의 real-world 시나리오 scene을 사용했습니다.
- DL3DV10K의 나머지 데이터를 평가데이터로 사용했습니다.
Implementation Details
- 32개 A100 GPU를 사용하였고, GPU메모리를 줄이기 위해 16bit로 mixed-precision 학습을 수행했습니다.
- Object/Scene 학습데이터셋을 mixed해서(섞어서), 각 scene마다 각 GPU를 16개의 batch size로 셋팅하여 40K iteration학습했습니다.
- object-level, scene-level 데이터셋 각각에 대해, 64개의 A100 GPU로 finetune합니다.
각GPU마다 object-level은 8개 batch size로 80K iteration만큼 수행했습니다.
각GPU마다 scene-level은 16개 batch size로 54K iteration만큼 수행했습니다. - 256x256 해상도에서 시작해서 512x512로 scale up하면서 mixed training을 하고, 20K iteration으로 finetune했습니다.
실험 결과
Object-level Generation
one-stage 3D diffusion 모델인 DMV3D와 2D multi-view diffusion기반 모델인 LGM, CRM, 12345++ 그리고 SDS-based 모델 DreamGS와 비교하였습니다.

이전의 방법들은 over-smooth되거나 3D geometry가 distort(왜곡)되는 것을 볼 수 있습니다. multi-vew image가 unaligned될 때 crack, artifacts, blur가 발생하는 것을 확인했다고 합니다. 반면 본 논문에서 제안한 방식은 어떤 direction이든 novel view에서 깔끔하고 perfect한 3D geometry를 보입니다. 특히나 첫번째 행에 fine-grained detail로 생성하는 것을 볼 수 있습니다.

14개의 object에 대해 25명에게 3D gemotry, texture quality, alignment에 대해 1(worst)~6(best)점범위로 visual quality 주관적 평가를 진행을 했었고 본 논문 DiffusionGS가 가장 높은 점수를 받았습니다.
Runtime부분에서도 빠른 속도를 보였습니다. 256x256 size 이미지 생성 시간을 측정하였으며, DiffusionGS가 상대적으로 빠른 성능을 보였습니다. GPU에 대한 언급이 없는데 A100 1개를 사용하지 않았을까합니다.
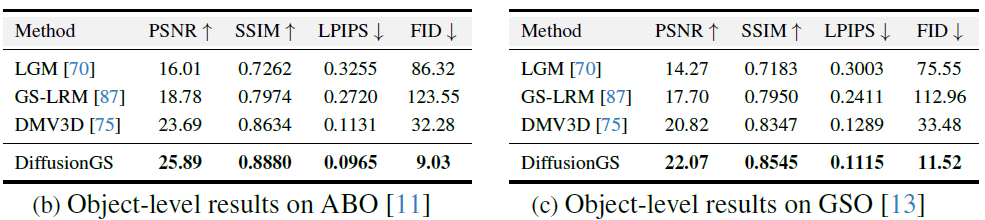
GT가 주어진 데이터셋으로 평가했을 때의 정량적인 평가값(이전글)입니다. 높은 점수를 갖는 것을 볼 수 있습니다.
text를 입력으로 stable diffusion 또는 FLUX로 생성한 이미지로 생성한 결과입니다.
높은 퀄리티를 보이는 것을 볼 수 있습니다.
Scene-level Generation
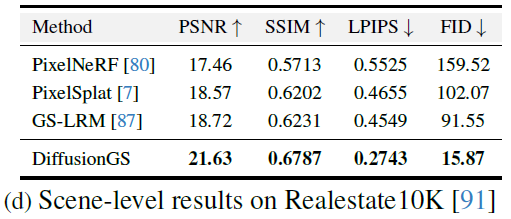
한장의 이미지로 3D모델을 생성하는 많은 연구들이 object-level를 다루고 있고 scene-level은 적게 다루고 있습니다. 그중 SOTA연구인 PixelNeRF, PixelSplat, GS-LRM를 갖고 퀄리티를 비교했고, DiffusionGS가 높은 퀄리티로 3D 모델을 생성하는 것을 볼 수 있습니다.
아래 이미지를 보면 blurry한 이전 연구들에 비해, DiffusionGS는 장애물 뒤에 있는 물체도 detail하게 모델링하고, 주어진 Scene밖에 있는 공간에 대해서도 높은 퀄리티로 생성하는 것을 볼 수 있습니다. 특정 domain에 제한되어 있지않고 Indoor/Outdoor scene 모두 잘 생성하는 것을 볼 수 있습니다.

아래는 Sora에 text를 입력해서 만들어진 영상 중 1개 프레임으로 3D Scene을 구성한 결과물입니다.

Ablation Study
Break-down Ablation
정량적 평가는 GSO데이터셋으로 GSO모델을 baseline으로 설정하여, 논문에서 제안하는 각 component들과 비교하고 있습니다.
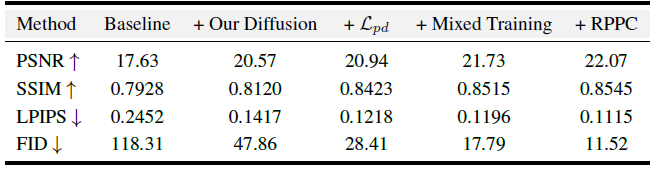
GSO모델에 DiffusionGS에서 제안하는 diffusion framework를 추가하였을 때, PSNR이 상당히 향상되는 것을 볼 수 있습니다. 그리고 각 component들 하나하나가 퀄리티를 향상시키는데 일조하고 있음을 볼 수 있습니다.
Analysis of Mixed Training
아래 그림은 object-level, scene-level을 mix해서 학습하는 mixed training에 대한 비교 자료입니다.

object-level, scene-level에 상관없이 mixed training을 할 경우 좀 더 clear하고 realistic하고 artifact가 적은 것을 볼 수 있습니다. 이는 mixed training 할 경우 3D geometry를 잘 capture하고 structural contents(=창문)을 잘 생성하는 것을 볼 수 있습니다.
Analysis of Generation Diversity
diffusion model기반이기 때문에 똑같은 3D모델을 생성하진 않습니다.

random seed가 변화함에 따라서 3D모델을 다르게 생성하는 것을 볼 수 있습니다.
Closing...
작년에도 이맘때(2023년 11-12월) single image로 3D모델를 생성하는 연구들이 쏟아졌는데, 이번에도 비슷하게 나왔네요. 앞모습으로 뒷모습을 모델링 하는게 불가능하다고 생각했는데, diffusion 모델과 3DGS를 이렇게 배치해서 높은 퀄리티의 결과물을 만들어내는게 신기하기만 합니다. 3D 콘텐츠가 쏟아져 나올 날이 멀지 않았다고 생각되게 하는 논문이었습니다.