[논문 리뷰] 3D Gaussian Splatting (SIGGRAPH 2023) 에서 언급된 3D Gaussian의 Rasterizer함수에 관한 설명글입니다. 3D Gaussain들로 구성된 3D Model이 존재 할 때, 특정 camera pose에서 그려질 2D 이미지 랜더링 방법에 관한 알고리즘을 소개하겠습니다.

입력 변수는 다음과 같습니다.
w,h : 이미지의 width, height / M,S : World좌표계에서 3D Gaussian의 평균, 공분산
C,A : 3D Gaussian의 color와 opacity(투명도) / V : 이미지에 대한 camera pose
Cull Gaussian : 주어진 camera view에서 관측 될 수 있는 3DGaussian들만 선택합니다. 카메라 중점에서 절두체(View Frustum)를 그리고, 필요없는 것은 제거(culling)하기 때문에Frustum Culling이라고 하는 것 같습니다.
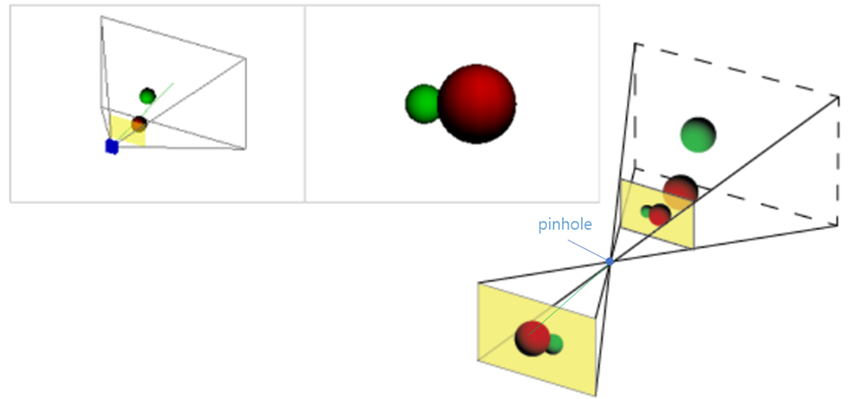
99%의 confidence를 가지는 Gaussian을 유지한다고 합니다. 2D covariance를 계산하는 것이 stable하지 못하기 때문에, Image plane에서 아주 가까우면서 view frustum에서 멀리 떨어진 extreme한 position들을 개별적으로 제거하는 guard band라는 개념을 사용합니다.
Screen space Gaussian : 3D Gaussian을 Image Plane으로 Projection하여 2D Gaussian을 만듭니다. 3D Gaussian의 Covariance는 아래와 같이 Scale Matrix S와 Rotation Matrix R로 구성된 Σ로 정의됩니다. 수식에 대한 세부설명은 [논문 리뷰] 3D Gaussian Splatting 참조 바랍니다.

2D로의 Projection은 아래 수식을 따릅니다.
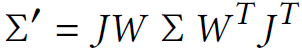
- Projective Transformation (Camera좌표계 -> Image 좌표계 변환 matrix)의 Jacobian(각 축으로 편미분한 Matrix) J
- Viewing Transformation (World좌표계 -> Camera 좌표계 변환 matrix) W
- World좌표계에서의 Covariance Matrix Σ / Image좌표계에서의 Covariance Matrix Σ'
세부적인 설명은 [개념 정리] 3D Gaussian과 2D Projection에 정리해두었습니다.
Create Tiles : width, height인 이미지를 16x16 pixel의 Tile들로 작게 나눕니다. CUDA에서 병렬로 처리하기 위한 것으로 보입니다.

Duplicate With Keys : 각 2D Gaussian이 Overlap되는 tile 수만큼 instance화 됩니다. CUDA에서 병렬적으로 Threading하기 때문에 1개의 Gaussian이 여러 Tile로 복제되는 것으로 보입니다. 각 instance들은 View space depth와 tile ID로 조합하여 (dictionary) key K로 만들게 됩니다. 총 64 bit 길이의 Key로 설계되며, 앞쪽 32bit는 depth 정보가 encoding되어지고, 뒤쪽 32bit는 overlap되는 tile의 index가 encoding됩니다. index의 정확한 크기는 이미지 해상도에 관한 tile의 갯수에 따르게 됩니다.
Sort By Keys : Key로 Sorting을 수행합니다. Single GPU Radix Sort (기수 정렬 : 낮은 자리수부터 비교해서 정렬: link ) 를 병렬적으로 수행하여, Tile마다 모든 splat들에 대해 Depth Ordering(정렬)을 수행합니다. 이를 통해 Blend In Order단계에서 key를 기반으로 카메라와 가까운 Gaussian을 먼저 그릴 수 있게 됩니다. Tile안에서 작은 pixel크기를 차지하는 gaussian들이 무시될 수 있었지만, artifact가 적어지고 수렴이 잘 되었다고 합니다.
기존 기법들은 Pixel마다 정렬이 필요해서 연산량이 높았는데, 해당 방법으로 효율성을 높일 수 있었다고 합니다. 또한 GPU Raidx sort를 사용함으로써, high parallelism과 amortized(분할상환)이 가능하다고 되어 있으며, 이를 통해 3D Gaussian 갯수를 늘릴 수 있다고 합니다.
Identify Tile Ranges : 같은 Tile id를 가진 시작과 끝 Gaussian을 식별(identify)하여 Tile별 Gaussian list를 효율적으로 관리합니다.
Get Tile Range : 이미지의 모든 tile 각각에 대해 Range r을 읽어옵니다.
Blend In Order : Tile마다 개별 CUDA Thread block으로 실행되어, 주어진 하나의 pixel에 대해 앞에서 뒤로 순차적으로 color와 alpha(=투명도)값을 accumulate 합니다. data loading/sharing/processing을 모두 병렬적으로 수행하여 이점을 최대화합니다. 하나의 pixel에 대한 알파값이 목표 saturation에 도달 했을 때, 해당 thread는 중지됩니다.
이전 연구와 다르게, gradient update를 받는 Gaussian의 갯수를 제한하지 않았습니다. Depth Complexity를 다양화하고 이를 학습시키는 과정을 통해, scene에 따른 hyperparameter tunning없이 임의의 Scene을 커버 할 수 있게 했습니다.
그 외 추가적으로 언급된 내용입니다.
Pulsar: Efficient Sphere-based Neural Rendering, CVPR 2021 에 언급된 pixel마다의 고비용의 sorting을 피하기 위해, 가장 작은 원소(primitives)를 미리 정렬(pre-sort)하는 rasterization 기법을 차용했습니다. 임의 갯수의 Gaussian이 섞인 scene에서 효율적인 backpropagation이 가능합니다. 적은 메모리 사용량과 pixel마다 상수시간만큼 소요됩니다. 미분가능하고 2D로 projection이 가능한 특징을 갖기에 anisotropic splat을 rasterize할 수 있습니다.
Backward 단계 진행시, forward 단계에서 처리된 pixel마다 blended point들에 대해 recover가 필요했습니다. global memory에 pixel마다 blended된 points list 저장하는 방법론(Point-Based Neural Rendering with Per-View Optimization, 2021)이 해결법이 될 수 있지만, dynamic memory 관리에 부하가 오는 것을 피하기 위해, Tile 마다 point list를 탐색하는 것을 사용했습니다. Tile Range와 정렬된 Gaussian 배열을 재사용 했습니다. Gradient Update시에는 Tile Range에서 Gaussian을 뒤에서 앞으로 탐색하게 됩니다.
Backward 단계 진행시, 각 Gaussian 투명도에 의해 accumulated된 opacity가 반복적으로 나눠지기 때문에, graident 계산을 위한 중간 opacity 값을 구성했습니다. 나이브한 구현에서, 0으로 나눠지는 겨우가 발생하였씁니다. 이걸 다루기 위해서, forward/bacwork둘 다, 알파값이 1/255보다 작을 때 blending update를 하지 않았습니다. rasterization 단계전에 이러한 경우가 발생하는지를 파악하기 위해 accumulated opacity를 계산하였고, rasterization중에 blending값이 0.9999를 초과하기전에 stop하였다고 합니다.
'Terminology' 카테고리의 다른 글
| [개념 정리] TV Loss (Total Variation Loss) (2) | 2023.10.24 |
|---|---|
| [개념 정리] SDS(Score Distillation Sampling) Loss : Text-to-3D Loss (0) | 2023.10.12 |
| [개념 정리] Graphics에서 Spherical Harmonics (4) | 2023.09.20 |
| [개념 정리] Marching Cube : 3D Point to Mesh생성 알고리즘 (1) | 2023.08.21 |
| [평가 지표] ATE(Absolute Trajectory Error), RPE(Relative Pose Error) (1) | 2023.05.18 |




댓글