Zero-1-to-3: Zero-shot One Image to 3D Object, Ruoshi Liu, ICCV2023
1장의 이미지로 3D모델을 생성하는 연구중에 하나입니다. Zero123 라고도 불립니다. Image-to-3D 최신 연구들과 서비스에서 많이 언급되어서 정리하게 됬습니다. 이번 논문 리뷰는 상세 리뷰보다는 다른 논문을 읽다가 Reference논문으로 언급되어져서 간단하게 내용 파악하실 분들을 위해 적어보았습니다.
Related Works
NeRF와 Diffusion모델을 접목하여 Reconstruction하는 연구들이 있었습니다.
- NeRDi: Single-view NeRF synthesis with languageguided diffusion as general image priors. (Dec 2022)
- RealFusion: 360° Reconstruction of Any Object from a Single Image (Feb 2023)
- NeuralLift-360: Lifting an in-thewild 2D photo to a 3D object with 360 views (Nov 2022, CVPR2023)
따로 해당 논문들의 문제점은 제시하지 않고 있습니다. 기존 방법론들과 다르게 Zero123는 viewpoints를 control한다고만 언급되어 있습니다.
View-Conditioned Diffusion
1장의 이미지와 카메라 상대 포즈(R:Rotation, T:Translation)를 입력으로 주면, 카메라 상대 포즈에 해당하는 이미지를 생성하는 Diffusion 모델을 제시합니다.
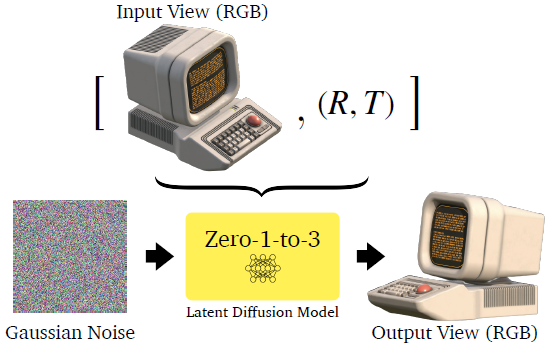
논문에서는 camera viewpoint를 입력으로해서 이미지를 합성하는 것을 하나의 큰 contribution으로 보고 있습니다. 아래는 논문 첫페이지 그림입니다.

Diffusion Model 모델 학습 방법은 다음과 같습니다.
- Diffusion Model은 Stable Diffusion을 사용하며 fine-tuning됩니다. allenai-github 체크포인트를 사용했다고 합니다.
- 데이터셋은 800K의 3D model로 구성된 고해상도의 Objaverse 데이터셋을 사용합니다.
- 물체의 중심을 바라보는 12개의 random camera viewpoint로 image를 rendering하고, 이미지 pair 2장씩 선택하여 Relative viewpoint(상대 카메라포즈)인 R,T를 만듭니다.
- Input view의 이미지는 CLIP모델(이전글 참조)로 임베딩(768 dimension)되고 Pose는 vector(4 dimension) 형태로 Diffusion Model의 Condition으로 입력하여 fine-tuning합니다.
- 8개의 A100 GPU로 7일 학습했습니다.
3D Reconstruction
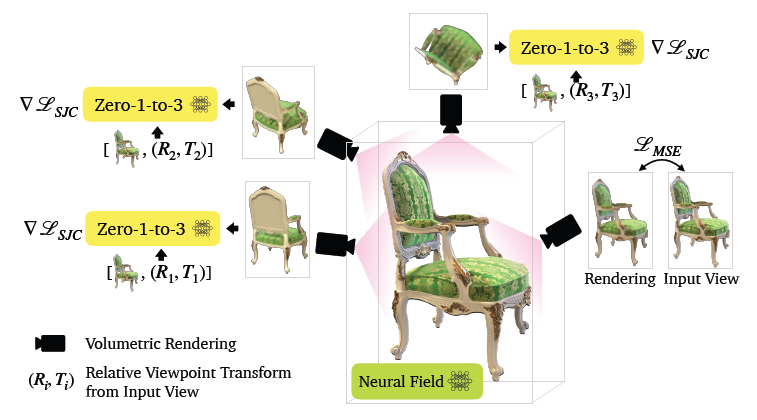
이전 섹션에서 설명하였던 View-Conditioned Diffusion 모델로 카메라 포즈에 따른 이미지를 합성하고, NeRF로 Reconstruction합니다. 이 부분은 SJC방식(이전글)을 따르고 있습니다. 때문에 NeRF모델은 TensoRF(이전글) 또는 Plenoxel(이전글)을 사용한 것으로 보입니다.
NeRF모델의 Parameter를 update하기 위한 DreamFusion방식과 Zero-1-to-3방식이 다르며 이를 비교해보았습니다. Diffusion 모델은 학습되어 있고 weight는 fix된다고 전제합니다.

Zero 1-to-3는 DreamFusion에서 초록색 Reference Image부분이 추가되고 Prompot Text도 바뀝니다.
- DreamFusion은 Condition으로, 설명하는 Text가 Prompt Text로 사용됬지만,
- Zero 1-to-3에서는 Condition으로, Pose값이 Prompt Text로 쓰여지고 Reference Image가 사용됩니다.
Loss도 달라집니다. Loss는 Diffusion Model의 Denosing Score를 사용하게 되는데, DreamFusion의 방식을 개선한 SJC방식을 사용하고 있습니다. 더 깊게 파악하고 싶다면, Denoising Score이 어떻게 개선됬는지 SJC 이전글 참조 바랍니다.
추가적인 Optimization Loss로는 pixel간의 차이를 계산하는 MSE Loss, Depth Smoothness Loss, 가까운 view간의 apperance 변화를 regularize하는 near-view consistency Loss를 사용합니다.
학습된 NeRF모델은 Marching Cube 알고리즘(이전글)을 사용해서 3D 모델로 생성합니다.
Experiments
논문에 첨부된 사진은 굉장히 높은 퀄리티로 만든 것 같은데,

프로젝트 페이지에 올린 영상을 보면 그렇진 않습니다.

하지만 이전 연구에 비해서는 확실히 좋은 성능을 보입니다.

GSO(Google Scanned Objects) 데이터셋으로 정량적 평가도 진행 하였습니다. 자세한 설명은 생략하겠습니다.

Text로 생성한 이미지로 3D를 만든 결과입니다. Text to Image to 3D로 보면 되겠습니다.

후속 연구엔 DreamGaussian(이전글)에 의하면 Zero 1-to-3의 Inference시간은 20분이라고 되어 있습니다.
Closing
Zero 1-to-3는 추후 높은 퀄리티를 보이는 Image-to-3D, Text-to-3D연구들의 Base로 사용하게 됩니다. 이 연구를 Base로 2023년에 Text-to-3D, Image-to-3D 분야가 엄청 성장하게 됩니다. 2023년에 Diffusion Model이 급격하게 발전하고 NeRF분야도 같이 성장하면서 퀄리티가 논문들이 계속적으로 나오고있습니다. 빠르게 이쪽 트렌드를 따라 잡아야겠다고 생각되네요.
'NeRF' 카테고리의 다른 글
| [코드 빌드] Stable Zero123 : Text-to-3D (4) | 2023.12.28 |
|---|---|
| [논문 리뷰] Score Jacobian Chaining (CVPR 2023) : Text to 3D (0) | 2023.12.24 |
| [논문 리뷰] One-2-3-45++ (arXiv 2023) : Image-to-3D 속도/퀄리티 개선 (0) | 2023.12.08 |
| [논문 리뷰] Tri-MipRF (ICCV 2023) : 속도/퀄리티/메모리 개선 (0) | 2023.08.16 |
| [논문 리뷰] GeoNeRF (CVPR 2022) : 적은 입력 + 일반화 모델 (0) | 2023.08.11 |




댓글