GAN, VAE 와 같은 생성 모델(Generative Model) 중 하나로써, 2022년에 이슈가 되었던 text-to-image 모델인 Stable-Diffusion, DALL-E-2, Imagen의 기반이 되는 모델입니다. 많은 논문에서 Diffusion Model이 인용되지만 수식이 어려워서 간단하게 개념을 이해하고 넘어가기가 어렵습니다. 때문에 필요에 따라 깊이 별로 내용을 파악 할 수 있도록 글을 써봤습니다.
Diffusion Model 이란?
입력 이미지에 (정규 분포를 가진) Noise를 여러 단계에 걸쳐 추가하고, 여러 단계에 걸쳐 (정규 분포를 가진) Noise를 제거함으로써, 입력 이미지와 유사한 확률 분포를 가진 결과 이미지를 생성하는 모델입니다. (그림 출처 : link1 , link2)


입력 이미지에서 Noise가 서서히 확산하기 때문에 Diffusion이라는 이름이 붙었다고 합니다.
Forward Diffusion Process에서는 이미지에 고정된(fixed) 정규 분포(=Gaussian분포)로 생성된 Noise가 더해지고,
Reverse Diffusion Process에서는 이미지를 학습된(learned) 정규 분포로 생성된 Noise이미지로 뺍니다.
Diffusion Model이 풀려고 하는 문제는, Forward -> Reverse 단계를 거친 '결과 이미지'를 '입력 이미지'의 확률 분포와 유사하게 만드는 것 입니다. 이를 위해 Reverse단계에서, Noise 생성 확률 분포 Parameter인 평균과 표준편차를 업데이트하며 학습이 진행됩니다.
- 1번째 그림은 최초 Diffusion Model(2015년)에 해당되며, Maximum Log-likelihood Estimation(MLE)을 사용했습니다.
- 2번째 그림은 후속 논문인 DDPM(2020년, Denosing Diffusion Probabilistic Model)에 해당되며, 이 부분을 CNN계열의 UNet모델을 사용했습니다.
그림에서 최종 입출력 이미지(x0)가 왜 같은지 의아하실텐데요. 설명을 위한 이미지일 뿐이며, 실제 Noise 생성시 가우시안 (확률) 분포에서 항상 다른 값이 샘플링 되므로, 생성되는 이미지는 계속적으로 바뀌게 됩니다. 그리고 학습 데이터에 따라 Reverse Diffusion Process로 부터 생성된 결과 이미지가 달라집니다.
다음 단계로 넘어가기 전에 아래 개념을 리마인드 바랍니다.
- Likelihood : link (수식이 나오기 전까지만 읽기를 권장 합니다.)
- Maximum Likelihood Estimation : link (상단 3줄만 읽기를 권장 합니다.)
- Markov Chain : link
- Bayesian Rule : link
- Gaussian Distribution : link
- KL-Divergence : link
Diffusion Model 알고리즘

현재 상태(t)는 이전 상태(t-1)에 의존한다는 마르코프(Markov) 특성을 가집니다. (현재 상태는 xt이지만 글 가독성을 위해 t로 표기하겠습니다.) (위 그림 출처 : link, 아래 그림 출처 : link)
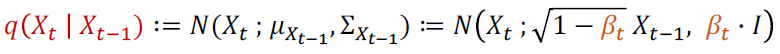

이전 상태(t-1)가 주어질 때 현재 상태(t)가 될 확률분포q는 평균(μ)과 분산(Σ)으로 구성된 Gaussian Distribution(=N= Normal Distribution)을 따릅니다. 이 식을 Noise 크기 parameter인 β를 포함하여 다르게 표현하면, 이전 상태(t-1)의 이미지가 β만큼 다른 pixel을 선택하게 하고, root(1-β)만큼 이전 pixel값을 선택하게 하는 식으로 정의 할 수 있습니다. t가 점점 증가함에 따라 β가 커짐으로써 Noise가 강해집니다.
Forward과정에서 β는 고정되어 있지만, 확률 분포를 따르기 때문에 마지막 상태(T)의 결과가 항상 다를 수 있습니다. 다음으로 Reverse과정에서 마지막 상태(T)를 반대로 최초 상태(0)로 만들고자 합니다. (위에서 빨간색으로 표시한) q식의 좌측항(posterior)과 우측항(prior)을 바꾼 조건부 확률 q(xt-1 | xt)을 알 수 있다면, 최초 상태(0)로 만들 수 있겠지만 이를 계산 할 수가 없습니다 (각 t시점에서 이미지의 확률 분포q(xt)를 알 수 없기 때문에 베이즈 정리에 의해 계산되지 않습니다). 때문에 확률분포 q가 주어졌을 때, 이 확률 분포를 가장 잘 모델링하는 확률 분포 pθ를 찾는 문제로 변환 합니다.

즉 확률분포 q에서 관측한 값으로 확률 분포 pθ의 likelihood를 구하였을 때, 그 likelihood값이 최대(Maximum)가 되는 확률분포를 찾는 Maximum Likelihood Estimation 문제입니다. -log를 붙이면 Negative Likelihood가 되고, 이를 최대화가 아닌 최소화하는 식으로 Loss를 설계 할 수 있습니다.

E는 확률 분포 q로 샘플링한 관측값에 대한 평균값(Expectation=기대값=적분값)을 의미합니다. 위 식을 전개 할 경우 아래 수식이 되며, 최초 Diffusion 논문(2015)에서는 Pθ가 가우시안 분포를 따른다고 가정하고 아래 수식이 0이 되도록 확률분포 parameter(θ)를 업데이트 합니다.
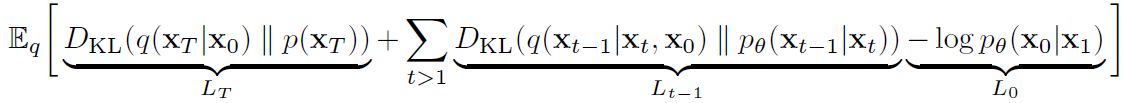
위 식을 다시 한번 더 정제한 DDPM(2020)에서는 아래 수식을 통해 Loss를 설계하여 UNet을 업데이트 하게 됩니다.

다음 단계에서는 위 수식이 무엇을 의미하는지 설명하고, 그 다음 단계에서는 위 수식 유도과정을 써보겠습니다.
Diffusion Model Loss
Loss를 설명하기 위해 위에서 언급된 전체 구조를 다르게 그려 봤습니다. (아래 그림 출처 : link )
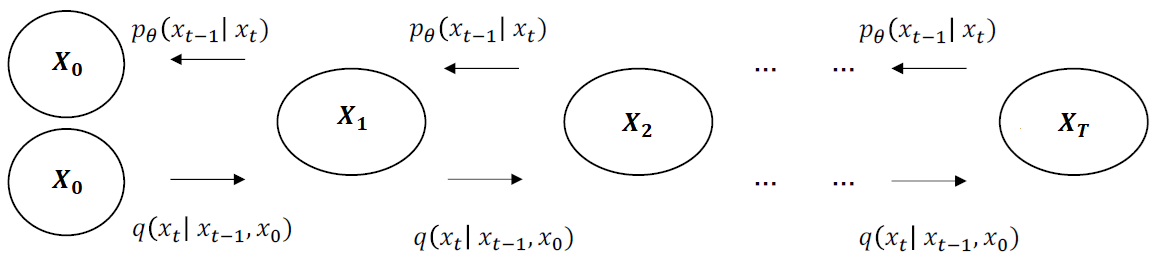
아래 수식은 최초 Diffusion Model(2015) 논문에서 언급된 보기 어려운 Loss 수식을 DDPM(2020)에서 깔끔하게 재정리한 수식입니다.
확률분포 q를 통해 샘플링 하였을 때, 위 수식의 평균값(=기대값=적분값)을 계산하는 수식으로 Loss가 설계되었으며, 위에서 설명하였듯이 이 값을 최소화 해야 합니다.
- LT : 마지막 상태(xT)에 대해, 확률분포 q와 p의 KL Divergence를 최소화하여, p와 q 확률분포 차이를 줄일 수 있습니다. Regularization Loss이라 불립니다.
- Lt-1 : 현재 상태(xt)가 주어질 때, 이전 상태(t-1)가 나올 확률 분포 q와 p의 KL Divergence를 최소화하여, p와 q 확률분포 차이를 줄일 수 있습니다. Denoising Process Loss라 불립니다.
- L0 : VAE(Varation Auto Encoder)Loss를 구성하는 Reconstruction Loss식 -log( p(x0|xT) )와 대응됩니다. 확률분포 q를 통해 샘플링하였을 때 - log( p(x0|x1) ) 에 대한 기대값을 최소화하여, p와 q 확률분포 차이를 줄일 수 있습니다.
다음으로 DDPM(2020)의 Loss 수식을 보겠습니다.

최초 상태(x0)로 부터 Step t가 경과되고, ϵθ네트워크가 Normalized Gaussian 분포 ϵ 를 따르도록, 기대값을 계산하는 수식이 Loss로 설계되었습니다. 이 값을 최소화 해야 합니다.
forward process수식을 다시 보겠습니다.
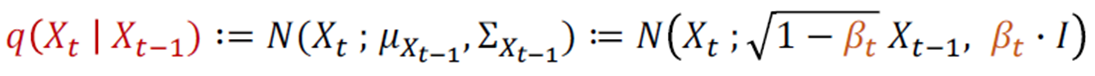
위의 수식은 prior가 xt-1이 아닌 아래와 같이 x0인 수식으로 변환 될 수 있습니다. (수식 유도 과정은 다음 섹션에서 언급하겠습니다.)
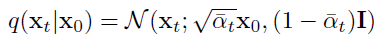

X가 Normal(=Gaussian) Distribution을 따를 때, 평균(μ) + 표준편차(σ) * Normalized 가우시안 분포(ϵ)의 식으로 나타낼 수 있는 아래 Reparameterization Trick을 사용해서, q(xt|x0)를 위 ϵθ 함수의 첫번째 인자로 바꿀 수 있습니다.

이제 DDPM(2020) Loss 수식의 의미를 보겠습니다. 앞에서 negative log-likelihood를 설명 할 때,
확률분포 q에서 관측한 값으로, 확률분포 pθ의 likelihood를 구하였을 때, 그 likelihood를 최대화시키는 확률 분포를 찾는 문제라고 언급했었습니다. 여기서는
t, x0, ϵ로 구성된 확률 분포에서 관측한 값으로, 확률분포를 모델링한 네트워크 ϵθ의 likelihood를 구하였을 때, 그 likelihood를 최대화시키는 확률 분포를 찾는 문제가 됩니다. (위 두 문단은 제 견해입니다. 잘못된 견해일 수 있습니다. 위의 표현을 인용하지 마시길 바랍니다... 해당 2문단에 대한 의견 주시면 감사하겠습니다.)
-log가 아닌, 네트워크 ϵθ와 Normalized Gaussian분포 ϵ가 같아지게하는 Squared Error에 대한 수식으로 바뀌었고
네트워크 ϵθ의 입력은 t, x0, ϵ으로 구성된 확률 분포를 Reparameterization Trick을 통해, 계산 가능한 수식으로 정의되었습니다.
위에 언급된 수식 유도 과정들은 분리해서 다음 글에서 다루겠습니다.
Experiments
βt 값에 의해 스케쥴링이 가능합니다. 최초 Diffusion 논문에서는 아래식을 사용했습니다.
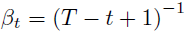
DDPM에서는 constant, linear, quadratic schedules을 실험했고 다른 결과를 보였습니다. β1 = 0.0001으로 βT = 0.02로 두고, linear schedule을 사용했습니다. (아래 그림 출처 : link )

T는 1000을 사용하였습니다.
최초 Diffusion 연구에서는 CIFAR-10, bark, dead leaves와 같은 natural image와 swis roll, binary sequence, MNIST 숫자를 사용하였고, DDPM에서는 CIFAR10만 실험했습니다.
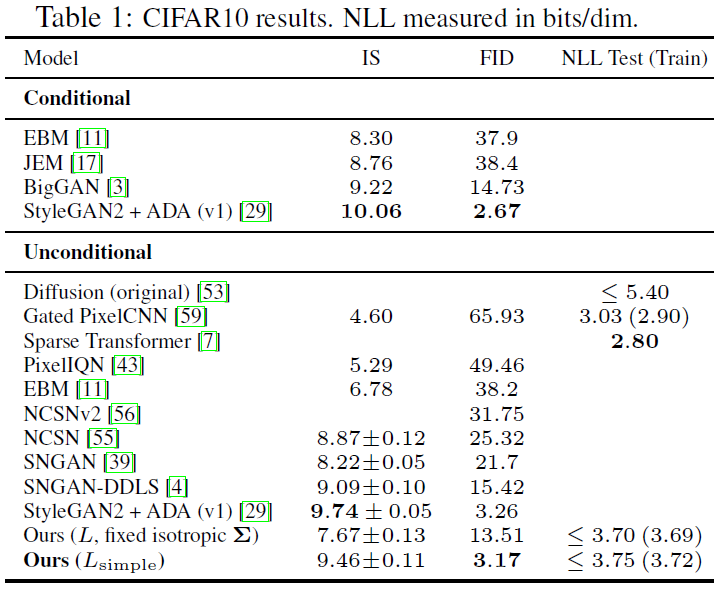
아래 DDPM의 Sample Quality결과를 표시하였습니다. CIFAR10 데이터셋을 갖고 Inception Score, FID Score, Negative Log Likelihood(NLL)로 측정하였고, DDPM이 가장 좋은 성능을 보였습니다.
다음 글에서 위에 언급된 수식 유도 과정들을 다뤄보겠습니다.
-> Diffusion Model 과 DDPM 수식 유도 과정 바로가기
출처
'Diffusion Model' 카테고리의 다른 글
| [개념 정리] Diffusion Model 과 DDPM 수식 유도 과정 (10) | 2023.04.01 |
|---|

댓글