SfM of COLMAP 1부에선 SfM의 기본 개념과 역사에 대해서 다뤘습니다.
[개념 정리] SfM(Structure from Motion) of COLMAP - 1부
COLMAP은 SfM(Structure from Motion)과 MVS(Multi-View Stereo)를 범용적으로 사용 할 수 있게 만든 라이브러리입니다.SfM은 이미지들을 입력으로 받아 Camera Parameter와 Point Cloud를 생성하고MVS는 'SfM 결과값'을 입
xoft.tistory.com
이번글 2부에선 논문에서 제시하고 있는 핵심 내용에 대해서 다뤄보고자 합니다. 전체적으로 생소한 용어를 사용합니다. 아래 글을 읽다가 이해 안되는 용어에 대해선 1부 내용을 (ctrl+f로) 참고 바랍니다.
본 글은 COLMAP 논문인 Structure-from-Motion Revisited (CVPR 2016) 상세 리뷰입니다.
해결하고자 하는 문제
이전 SfM연구들에선 large-scale의 인터넷 사진들을 처리 했지만, 이미지 registeration을 전혀 못하거나 잘못하거나 drift(=누적오차)가 발생하면서, completeness(완성도)와 robustness(견고성) 측면에서 좋은 결과물을 만들 수 없었습니다. 그 이유는 크게 2가지로 볼 수 있습니다.
- correspondence search 단계에서 incomplete한 scene graph를 만들면서 발생할 수 있습니다. 예를 들어 matching approximation 근사치를 사용하면 reliable estimation을 위한 필수적인 이미지 connectivity를 형성하지 못하거나 충분한 redundancy(중복)영역을 만들지 못한 경우입니다.
- reconstruction 단계에서 scene structure의 누락이나 부정확성 때문에 image를 regiser하지 못하기 때문에 발생할 수 있습니다. 이미지 registeration과 triangulation은 의존 관계를 갖고 있습니다. 이미지는 형성된 scene structure에만 registeration 할 수 있고, scene structure는 registered된 이미지로부터 triangulation 할 수 있기 때문입니다.
본 논문에선 SfM성능을 향상시키기 위해, 방금 언급한 correspondence search 단계, reconstruction 단계에서 accuracy와 complemeness를 최대화하는 전략을 제안하고 있습니다.
Contributions
SfM을 개선하기 위한 총 5가지 방법을 제안합니다.
- geometric verification 전략
: scene graph를 강화하는 정보를 추가하여 initialization단계와 triangulation 단계에서의 robustness를 향상합니다. - next best view selection 전략
: incremental reconstruction방법론의 robustness과 accuracy를 최대화합니다. - robust triangulation 전략
: 계산 비용을 줄이면서도 SoTA방법보다 훨씬 더 complete한 장면 구조를 생성합니다. - 반복적인 BA(bundle adjustment), retriangulation, outlier filtering(이상치 필터링) 전략
: drift효과를 완화하여 완성도와 정확성을 크게 향상합니다. - efficient BA parameterization 전략
: 중복된 뷰를 탐색함으로써 대규모 사진 컬렉션에서 효율성을 높입니다.
위 5가지는 COLMAP 기술에 대한 목차로 볼 수 있습니다. 하나씩 풀어보겠습니다.
1. Scene Graph Augmentation

적절한 geometric relation을 갖도록 scene graph를 확장하기 위해, 여러 모델로 geometric 검증 전략을 제안합니다.
1) 이미지 쌍에서 fundamental matrix(이전글)를 추정한 후, 최소 $N_F$개의 inlier(=매칭되는 점)를 찾으면 해당 이미지 쌍을 기하학적으로 검증된 것으로 간주합니다.
해당 이미지 쌍에서 동일하게 움직이는 inlier $N_H$개를 분류합니다. (GRIC과 같은) 모델 selection 방법과 유사한 방법을 적용하기 위해, hyperparmeter $\epsilon_{HF}$를 사용해서 $N_H/N_F<\epsilon_{HF}$일 경우, 일반적인 상황에서 움직이는 카메라로 간주합니다.
2) calibration된(intrinsic,extrinsic parameter로 보정된) 이미지의 경우, fundamental matrix가 아닌 essential matrix와 inlier개수$N_E$를 추정합니다. $N_E/N_F>\epsilon_{EF}$일 경우 정확한 calibration이 됬다고 간주합니다.
이 두가지 경우로 판정된 경우, essential matrix를 사용해서 triangulate합니다(= inlier에 해당하는 3d point를 추정합니다.) 그리고 삼각 측량의 중앙값 $\alpha_m$값을 계산하여, pure 회전(=panoramic) 과 평면 scene(=planar)을 구별합니다.
3) 인터넷 사진들에 존재하는 WTFs(Watermark, Time, Frame=테두리)를 찾는 과정을 거칩니다. 이미지 가장자리에 유사한 transformation inlier $N_S$개를 찾아 그러한 종류의 이미지를 detection합니다. 구체적으로 $N_S/N_F>\epsilon_{SF}$ V $N_S/N_E>\epsilon_{SE}$인 경우 WTF로 간주하고 scene graph에 포함하지 않았습니다.
4) valid한 이미지 쌍의 경우, scene graph를 모델 유형(general, panoramic, planar)과 가장 많은 인라이어 모델($N_H, N_E, N_F$)로 라벨링했습니다. 모델의 유형은 reconstruction을 initialization시에 사용하게 되는데, panoramic이 아닌 쌍이고 calibration된 이미지 쌍을 우선적으로 사용했습니다. 또한 모델 유형은 이미 scene graph가 만들어져 있는 경우, (새로운 이미지 registration시) 강인한 reconstruction process를 위해 optimal한 initialization(=registration 위치)를 효과적으로 찾을 수 있게 합니다.
5) panorama 이미지쌍에선 degenrated된 point가 만들어 질 수 있기 때문에 triangulation을 수행하지 않음으로써, 이미지 registeration의 robustness를 향상시켰습니다.
2. Next Best View Selection

registration할 대상 이미지를 찾는 view selection은 reconstruction 오차를 최소화하는데 중요합니다. 잘못된 view selection 하나가 연쇄적으로 잘못된 camera registration과 triangulation을 만들 수 있기에 중요합니다. robust한 reconstruction을 위해 uncertainty-driven(불확실성 기반) view selection 방법을 제안하고 있습니다.
기존 접근 방식
- 일반적으로 triangulation된 point가 가장 많이 보이는 이미지를 선택해서 카메라 resection(=parameter 추정)의 uncertainty를 최소화하는 방식을 사용합니다.
- Lepetit 연구에서는 PnP를 사용한 camera pose 정확도는 관찰된 point 갯수와 분포에 달려있다고 보여줬습니다. 많은 2D-3D correspondence가 있을 경우 중복 영역이 많아지게 되고, 균등한 point분포의 경우 잘못된 구성을 방지하게 되면서 신뢰있는 intrinsic parameter추정이 가능했다고 합니다.
- selection 될 view 후보는 단순히 triangulated한 point 갯수가 hyper-parameter $N_t$ 이상인 경우가 됩니다.
- 이미지를 효율적으로 관리하기 위해 feature track 그래프를 사용하게 됩니다.
- 인터넷 이미지 경우 동일한 구조를 볼 수 있어 매우 그래프의 밀도가 매우 높아지게 되면서 선택 가능한 후보 view가 많아지게 됩니다. Haner가 제안한 covariance propagation 방식은 모든 후보에 대해 covariance를 계산해야하므로 현실적이지 못합니다.
제안하는 방법
- multi-resolution(해상도) 분석을 통해 기존 uncertainty 기반 방식과 유사한 결과를 만듭니다.
- visible한 point 갯수와 각 view 후보의 분포를 동시에 추적합니다. 많은 visible point갯수를 가지면서 uniform한 분포를 가진 이미지의 경우 높은 점수를 부여하고, 가장 우선적으로 registration합니다.
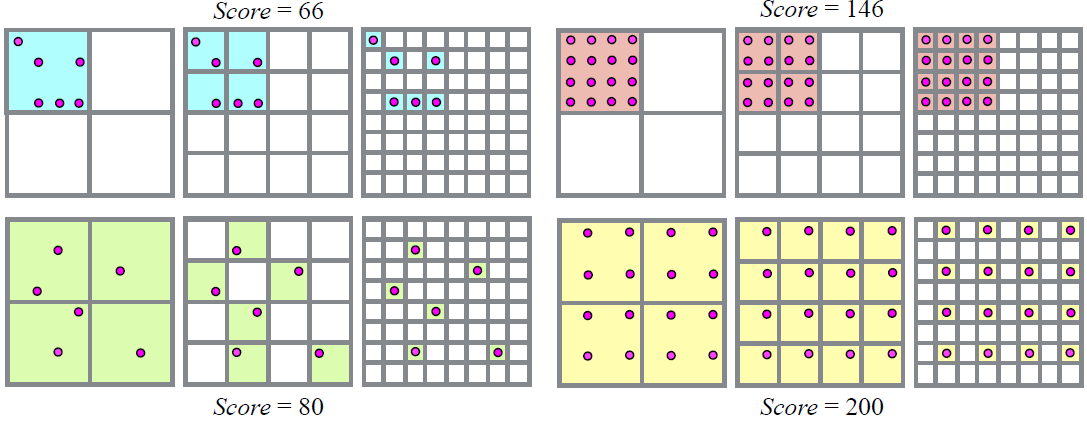
- 구체적으로 이미지를 고정된 size로 나눠 $K_l^2$개 cell로 분리된 grid를 만듭니다. 각 cell은 empty와 full 이라는 state중 한개로 설정합니다. reconstruction중에 empty state cell내 1개 point가 visible하게 될 때, 해당 cell은 full state로 바뀌고 이미지의 score는 weight $w_l$만큼 증가합니다. 이러한 방식으로 visible point 갯수 뿐만 아니라 full state갯수로 point가 균등하게 분포되었는지를 알 수 있습니다.
- 하지만 visible point 갯수 $N_t$가 cell의 갯수 $K_l^2$보다 훨씬 적다면, point 분포를 알기가 어려울 수 있습니다. 때문에 grid를 나누는 갯수를 $K_l = 2^l$로 두고 level l을 1부터 정수 L 증가시키면서 이미지를 서로 다른 크기의 cell로 나누는 방법을 사용했습니다. 이를 multi-resolution 기법이라고 하며, 모든 level의 score값을 더해서 visible point가 얼마나 분포 됬는지를 수치적으로 효율적으로 계산 할 수 있게 했습니다. 아래는 예시입니다.
3. Robust and Efficient Triangulation

희소하게 일치하는 이미지 집합이 주어질 때, transitive correspondences를 활용하면 completeness와 robustness를 향상 시킬 수 있습니다. transitive correspondence란 A↔B 와 B↔C correspondece pair가 주어질 경우, A↔C의 correspondence를 만들 수 있다는 의미입니다. appearance로 correspondence를 만들기 때문에, A↔B 와 B↔C 각각의 pair는 짧은 길이의 baseline (개념참조)을 찾을 수 있습니다. transitive correspondences를 사용해서 A↔C관계를 만들면 긴 길이의 baseline을 찾을 수 있게되고, 이를 통해 더 정확한 triangulation이 가능해집니다. 이는 feature track 형성을 통해 가능합니다.
문제 정의
feature track에서는 geometric verification단계에서 이미지쌍의 모호한 epipolar line으로 인해 outlier(이상치 point수)가 높은 비율로 발생 할 수 있습니다. 예를 들어, 잘못된 이미지 1쌍이 다른 3개 이미지쌍과 결합하면서, outlier는 75%비율로 발생 할 수 있습니다. 때문에 multi-view refinement를 수행하기 전에 신뢰있는 이미지 쌍 집합을 찾거나 recursive triangulation 방법이 필요로 합니다.
기존 접근 방식
Bundler기법은 feature track내 모든 이미지쌍을 샘플링하고, triangulation angle이 특정 각도를 넘는 case가 있는지를 탐색합니다. 모든 관찰치가 cheriality 제약(=point가 카메라 앞에 위치함)을 만족하면 신뢰있는 이미지쌍으로 정의합니다. 이 방법의 문제점은 잘못 병합된 point를 복구할 수가 없고, 모든 쌍을 계산하기 때문에 계산 비용이 큽니다.
제안하는 방법
RANSAC(Random Sample Consensus=랜덤하게 샘플링 방식)를 사용하여 multi-view triangulation 문제를 해결했습니다.
1) feature track을 이미지 $\bar{\mathbf{x}} \in \mathbb{R}^{2} $ 와 카메라 포즈 $P_n \in SE(3)$로 구성합니다.
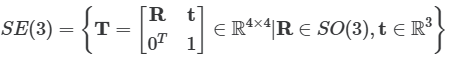
2-view triangulation함수 $\tau$를 아래와 같이 정의하여, 카메라 포즈 $P_n$을 최적화하여 값을 찾습니다. 본 연구에서 $\tau$는 DLT를 사용했다고 합니다.
2) panoramic 이미지 쌍에 대해서는 에러가 발생 할 수 있기에 triangulation을 수행하지 않았습니다.
3) 카메라 중심점 3차원 위치($t_a$, $t_b$)와 triangulated 3D point($X_{ab}$)에 대해서 hyper-parameter 각도 $\alpha$를 유지하는지 확인하고, 3D point가 카메라 앞에 위치하는지 거리 d값을 통해 판별하였습니다. $p_{3#}$은 카메라 포즈 $P_n$ 행렬에서 카메라 중심점 위치에 관한 parameter입니다.

d는 0이상이 되어야 합니다.
4) 3D point를 2D로 투영해서 에러를 계산합니다.

5) 이미지 minimal set 크기를 최소 2로 설정하여 무작위로 샘플링하면서 위 에러를 계산합니다. 이를 K번 반복적으로 수행합니다. 중복 샘플링이 되지 않도록 처리합니다. 초기엔 K를 작게 설정하고, 에러가 충분히 작은 consensus set(=모델과 일치하는 데이터 점들의 집합)을 찾으면 K값을 조정합니다.
6) 여러개의 독립적인 point들이 포함 될 수 있기 때문에 consensus set을 찾게 되면, 이 집합을 데이터에서 제거하고 나머지 데이터에 대해 동일 과정(샘플링>triangulation>error계산을 K번 반복)을 반복합니다. 반복(←K번 아님)은 consensus set의 크기가 3보다 작아질 때 종료합니다.
최대한 풀어서 쓰려고 하는데도 딱딱한 감이 있네요. 3부에 이어서 남은 Bundle Adjustment기법과 Redundant View Mining 기법에 대해 소개하겠습니다.
'Camera Model' 카테고리의 다른 글
| [개념 정리] SfM(Structure from Motion) of COLMAP - 3부 (1) | 2025.01.18 |
|---|---|
| [개념 정리] Quaternion (쿼터니언) 회전 (0) | 2024.12.23 |
| [개념 정리] Rotation Matrix (회전 행렬) (1) | 2024.12.21 |
| [논문 리뷰] MASt3R (arXiv2024) : 3D기반 Image Matching 기법 (5) | 2024.06.30 |
| [개념 정리] Fronto Parallel Plane (0) | 2024.05.26 |




댓글