논문명 : The Unreasonable Effectiveness of Deep Features as a Perceptual Metric(2018)
LPIPS는 2개의 이미지의 유사도를 평가하기 위해 사용되는 지표 중에 하나입니다.
단순하게 설명하자면, 비교할 2개의 이미지를 각각 VGG Network에 넣고, 중간 layer의 feature값들을 각각 뽑아내서, 2개의 feature가 유사한지를 측정하여 평가지표로 사용합니다.
본 글은 LIPIPS 논문 내용을 풀어쓴 내용로써, 평가 지표로써 의미가 있는지를 여러 실험을 통해 증명하는 내용입니다. 단순한 수학 수식을 증명 과정이 길어 지듯이, 해당 논문도 내용이 깁니다...
- 단순히 LPIPS가 무엇인지 궁금하신 분은 위에 강조한 2줄만 읽으시면 되구요.
- Feature를 어떻게 뽑는지 좀 더 알고 싶으신분은 "Network Activation to Distance" 만 읽으시면 됩니다.
- 깊게 탐구하고 싶으신 분은 다 읽으시면 됩니다.
- 그 외 다른 평가지표는 PSNR/SSIM/LPIPS 글 참고 바랍니다.
Introduce
딥러닝 커뮤니티에서 VGG Network의 Feature가 이미지 합성을 위한 Training Loss로 유용하다는 것을 발견 했습니다. Perceptual Loss는 Perceptual(인지적)일 수 있는가? 성공을 평가하는 기준이 무엇인가? 에 대한 질문에 답하기 위해, 가능한 다양하게 Distortion한 데이터셋을 구성하고, CNN기반의 다양한 Task의 알고리즘으로 이미지 유사도에 관하여 다룬 논문입니다.

Contribution
논문에서 언급한 기여도는 아래와 같습니다.
- 484,000개의 사람의 판단이 포함된 크고, 다양한 perceptual similiaty dataset을 만들었습니다. Parameterized distortions과 real 알고리즘이 포함되었고, Just noticeable differences(JND)라는 Perceptual Test 결과를 수집하였습니다.
- Supervised, self-supervised, unsupervised object로 학습된 deep feature가 low-level의 preceptual similarity 모델링을 아주 잘하는 것을 보여줬습니다.
- Network architecture는 performance와 관련이 없고, 학습되지 않은 Network는 낮은 performance를 보였습니다.
- 본 연구에서 만든 데이터를 사용해서 Pre-trained network로 feature를 calibration함으로써 성능 향상을 볼 수 있었습니다.
Berkeley-Adobe Perceptual Patch Similarity (BAPPS) Dataset
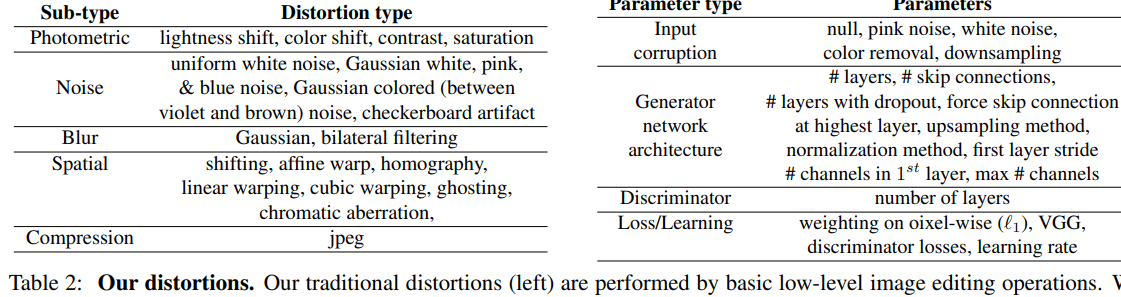
적용한 Distortion 함수
- Traditional Distortion : 아래 왼쪽 표에 표시된 20개의 기본 distortion과, 이를 조합해 sequentially하게 구성하여 308개의 distortion을 만들었습니다.
- CNN-Based Distortion : 아래 오른쪽 표에 명시한 paramters를 랜덤으로 다양하게 하여 96개의 denosing autoencoder를 구성하고, 1300만개의 ImageNet 데이터셋으로 1번 학습시켰습니다.
평가 데이터셋 구성 : 실제 알려진 알고리즘으로 Distortion한 이미지를 만들어서 평가Testdata를 구성하였습니다. Colorization Task로는 Bleeding과 Color Variation를 평가하기 좋고, Superresolution Task로는 Structural Changes를 평가 하기 좋습니다.
- Superresolution : 2017 NTRIE workshop의 top 4의 알고리즘[24, 59, 31, 48]과 여러 추가적인 superresolution 알고리즘으로 평가하였습니다. Div2K 데이터셋 (고해상도의 GT와 2개 알고리즘 결과를 갖고 있음) 에서 랜덤으로 64x64 triplets(3개쌍)을 샘플링 하였습니다.
- Frame Interpolation : Davis MiddleBurry 데이터셋으로 3가지 Frame Interpolation 알고리즘(flow-based interpolation, CNN-based interpolation, phase-base interpolation)을 수행하고, 그 결과들에서 patch들을 샘플링 하였습니다.
- Video deblurring : Photoshop Shake Reduction, Weighted Fourier Aggregation, [53]논문내 3개의 다양성을 가진 deblurring 결과로부터 샘플링 하였습니다.
- Colorization : imageNet데이터셋에서 이미지로 Pxi2pxi와 [63] 알고리즘을 사용하고, 랜덤 scale로 patch들을 샘플링 하였습니다.
2AFC(two alternative force choice) Test : 2개 distortion중에 어떤 것이 좀더 reference와 유사한지를 묻는 Test를 진행 하였습니다.
- 랜덤하게 이미지 patch를 선택하고, distortion을 적용하여 2개의 patch를 만들었습니다. 그리고 original patch와 가까운 것이 무엇인지 사람이 판단하였습니다. 평균적으로 판단하는데 3초정도 대략 걸렸습니다.
이전 연구의 데이터셋들은 적은 input image와 적은 distortion으로 human judgement 횟수에 초점을 맞추었지만 본 연구에서는 64x64 patch로 많은 input을 구성하고, 많은 distortion을 만드는 것에 초점을 두었습니다. 그이유는 1) Full image로 할 경우 평가할 space가 너무 컸고, 2) High-level semantics에 영향을 덜 받게하면서 low-level 유사도 관점에 초점을 맞췄고. 3) 일반적인 합성 알고리즘들은 patch단위로 loss를 계산하기 때문입니다. - MIT-Adobe5K(Train dataset), RAISE1k(Validation dataset)를 사용해서 161K 패치를 구성하였습니다.
- Amazon Mechanical Turk(crowd-sourcing)서비스를 통해 평가하였습니다. Train set에서 예제마다 2개 judgement를 질문하고, Validation set에서 5개의 judgement를 질문하였습니다.
JND(Just Noticable Difference) Test : 1개의 Reference와 1개의 distorted 패치가 같은지 다른지를 묻는 Test를 진행하였습니다. 2AFC에 대한 유효성을 판단하기 위해, 2번째 실험으로 JND Test를 사용하였습니다.
- 2AFC에서 사람이 유사도 판단을 할 때, 주관적으로 어떤 특성을 중요하는가에 따라 human 에러가 발생합니다. JND Test에서는 원본 이미지와 distorted한 이미지를 1초씩 0.25초 간격으로 보여주고 서로 같은지 다른지를 물어봤습니다.
Network Architecture
- VGGNet에서는 5개 Convolution Layer를 사용하였습니다.
- AlexNet에서는 사람의 시각 (대뇌) 피질의 구조와 좀 더 가깝다고 볼 수 있는 얕은 네트워크인 AlexNet에서 Layer1~5를 사용하였습니다.
- (AlexNet과 성능이 비슷하고 Weight가 적은)SqueezeNet에서는 layer1과 "fire" layer 4개를 사용하였습니다.
- 추가적으로 puzzle-solving, cross-channel prediction, learning from video, generative modeling을 포함한 self-supervised 함수를 추가적으로 평가하였습니다.
Network Activation to Distance
- 2개의 이미지 Patch(x,x0)를 Network에 통과 시켜, 각 Layer의 Feature Vector의 값을 아래와 같이 추출하여 거리를 비교하였습니다.


- L은 레이어를 의미하고, h,w는 각 layer에서 height, width이고, y, y0는 채널 차원에서 unit-normalize한 feature vector입니다. w는 Scale Factor이며 모두 1로 사용합니다. y,y0에 대해 채널 단위로 L2 Loss를 구하여 모든 layer에 대해 Sum해줍니다.
Evaluation
다음부터는 논문 서술법과 동일하게 질의 응답형태로 결론을 도출하였습니다.
Q. low-level metrics과 classification netowrks가 잘 수행되는가?
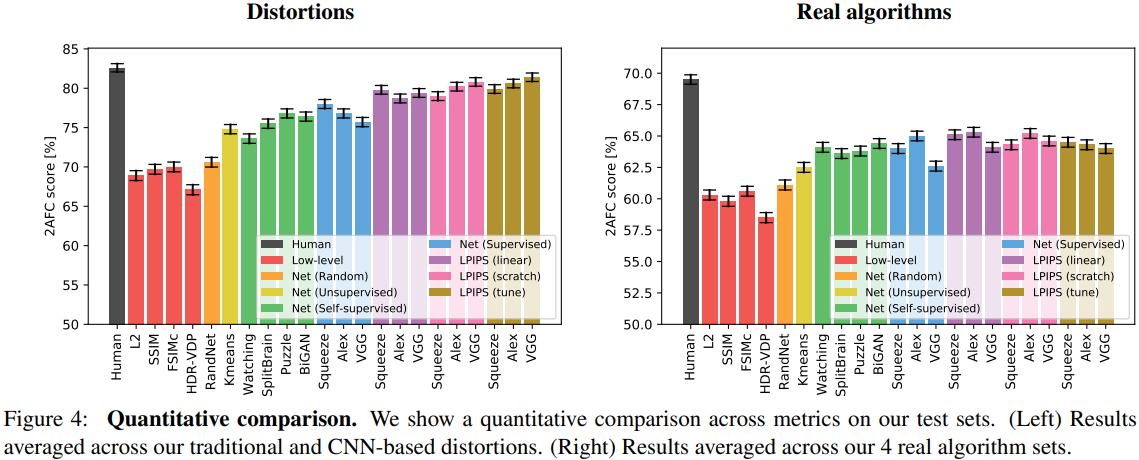
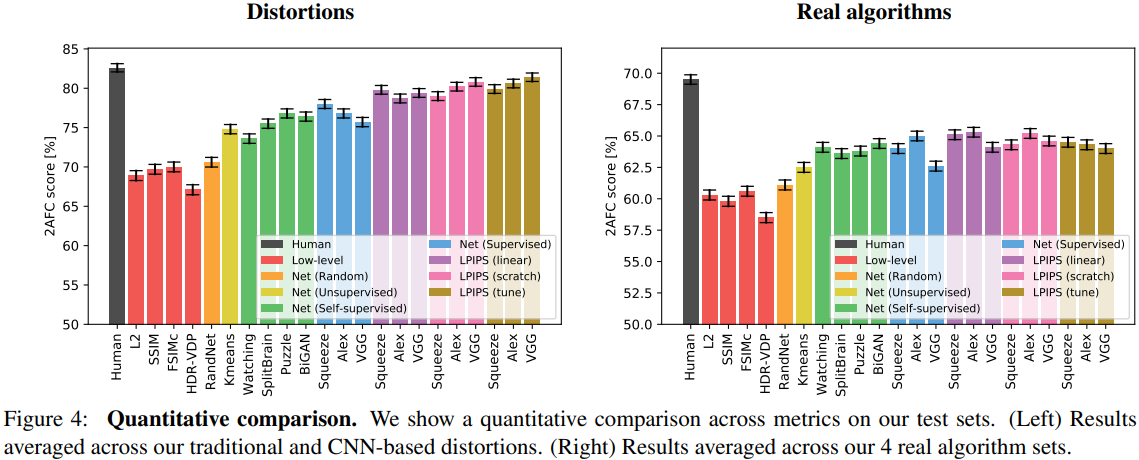
- 위에 언급한 Figure 4는 다양한 low-level metrics(빨강)와 deep networks, human ceiling(검정)의 performance를 보여줍니다. 왼쪽은 2개의 distortion test sets (traditional+CNN-based) 으로 평균낸 점수이고 오른쪽은 4개의 알고리즘 밴치마크 (superresolution, frame interpolation, video deblurring, colorization) 로 평균낸 점수입니다. 6개 test set을 평균하였습니다.

- 결과적으로, Classification Network(파랑)가 기존 metrics(빨강)보다 Perceptual Simularity를 잘 계산하는 것을 볼 수 있었습니다.
(SSIM은 geometric distortion이 Large Factor가 되는 상황을 위해 설계되지 않았습니다.)
Q. 네트워크는 classification으로 학습되어져야 하는가?
- Figure4의 초록 부분을 보면, 다양한 unsupervised와 self-supervised task의 성능을 볼 수 있습니다.
Generative model인 BiGANs[13], 퍼즐 풀기인 Puzzle[40], cross-channel prediction인 Split-Brain[64], 비디오의 foreground 물체 segmentation인 Watching[43]에 대해 평가 하였습니다. Self-supervised task를 classification network으로 평가했습니다(=These self-supervised tasks perform on par with classification networks). 결과를 봤을 때, 큰 스펙트럼을 가진 task는 perceptual distance를 잘 transfer하는 representation을 만들어 낼 수 있다는 것을 보여줬습니다. Stacked K-means와 같은 함수(노랑)은 low-level metrics에서 잘 수행하는 것을 볼 수 있었습니다. 가우시안 분포를 가지고 랜덤 weight로 만든 network(주황)은 성능이 좋지 않았습니다. 입력이미지의 feature들을 dense하게 추출 할 수 있는 network structure들을 조합했더니, perceptual judgments에 대해 좀 더 correlation을 가졌습니다. - PASCAL datatset으로 (self-supervised방법인 Split-Brain[64]연구를 포함한) sementic task(Classification, Detection)가 perceptual task(2AFC, JND)와 얼마나 correlation을 가지는지를 봤습니다.

- 2AFC와 JND는 사람이 다른 2개 방법으로 평가하였기에, 92.8%로 correlation이 높습니다. 그에 비해 2AFC와 Classification는 64%, 2AFC와 Detection은 36.3%의 correlation을 가졌습니다. 2AFC는 "Low-level"인 Percetual Task입니다. Classification과 Detection 둘다 "High-level" Semantic Task이지만, 둘 사이의 correlation은 42.9%였습니다.
Q. Metrics는 다른 Perceptual Task와 correlation을 가지는가?
- 2AFC와 다른 perceptual task와 상관관계를 테스트해봤습니다. 주어진 metric들로 patch pair를 오름차순으로 정렬하고, CNN-based distortions으로 precision-recall을 계산하였습니다. 그리고 curve아래의 영역으로 mAP를 계산하였습니다. Distortion type들에 대한 결과들의 평균을 구했을 때, JND가 92.8%로 높은 correlation을 가졌습니다. 아래 그림은 어떻게 다른 함수들이 각각의 perceptual test를 수행하는지를 보여줍니다. 2AFC가 다른 perceptual test를 generalize하고, 사람의 judgment와 관련된 신호를 찾아 낸다는 것을 보여줍니다. (이 부분은 정확히 이해 못했습니다)

Q. Traditional and CNN-based인 distortion으로 metric을 학습 할 수 있는가?
- Variants를 고려하여 Lin, Tune, Scratch Configuration을 구분하였고, LPIPS(Learned Perceptual Image Patch Similarity) metric의 varient으로써 사용하였습니다.
- Lin configuration(보라) : pre-trained된 network weights F를 고정하고 top에 있는 weights w 를 학습하였습니다. feature space에서 적은 parameters로 "perceptual calibration"을 구성하였습니다. 예를 들어, VGG network는 1472개의 parameters 로 학습되었습니다.
- Scratch Configuration(분홍) : Random 가우시안 weight로 network를 initialize하고, judgments 전체를 학습하였습니다.
- Tune Configuration(황토) : pre-trained classification model로 initialize하고, 네트워크 F의 모든 weight가 Fine-tuned 될 수 있도록 하였습니다.
- 왼쪽 그래프를 보면. Traditional and CNN-based distortion으로 validation하였을 때, LPIPS가 모두 좋은 Score를 보였고, 그 중에서도 Tune하였을 때 가장 좋은 성능을 보였습니다.
오른쪽 그래프를 보면, VGGNet은 상대적으로 low capacity인 SqueezeNet과 AlextNet 보다 더 좋은 성능을 보였습니다. 이 결과를 통해 Network가 perceptual judgment를 배울 수 있다는 것을 증명하였습니다.
Q. Traditional and CNN-based distortion으로 학습한 것을 real-world 시나리오로 transfer할 수 있는가?
- Fig4 오른쪽 그래프를 보면, Linear Classifier(보라)를 학습하는 것이 가장 좋은 성능을 보여줬습니다. 파랑,보라,분홍,황토에서 12개중에 11개 성능이 좋았다는 점을 보았을 때, 본 논문의 데이터를 사용한 representation에서 "calibrating" activation은 약간의 성능 향상에, 안전한 방법이라는 것을 보여줍니다.
- Scratch로부터 네트워크 학습은 Linear Calibration보다 AlexNet에서 낮은 성능을 보였고, VGG에서 Linear Calibration보다 좋은 성능을 보였습니다. 하지만 이 12개 수치들은 여전히 low-level metrics(L2, SSIM 등)을 능가합니다. 우리가 표현한 distortion들은 실제 알고리즘을 평가하는 test-time tasks로 대입 할 수 있다는 것을 나타냅니다.
- pre-trained network와 lower (layer)를 통한 tuning은 performance를 transfer합니다. 이것은 흥미로운 negative result입니다. 직접적으로 Low-level perceptual task를 학습하지 않고, High-level task를 위해 학습된 representation을 transfer도 하지 않습니다.
Q. Deep metrics와 low-level metrics가 어디에서 불일치 하는가?
- Fig 11에서, deep method인 BiGANs[13]과 low-level metrics인 SSIM의 퀄리티를 비교하였습니다. BiGAN이 유사도가 멀리 떨어지도록 인식하지만 SSIM은 가깝다고 인식하는 pair들은 일반적으로 blur를 포함하였습니다. BiGAN은 correlated noise pattern을 SSIM보다 적은 distortion으로 인식하는 경향이 있었습니다.

Closing...
이미지 유사도를 측정하는 지표중에 하나인 LPIPS를 살펴 보았습니다. 다양한 Distortion으로 만들어진 데이터들을 CNN의 Feature Vector 비교를 하여, 전통적인 Low-level Metric인 L2, SSIM, FSIMc보다는 성능이 좋다라는 것을 보였습니다. 컴퓨터가 사람처럼 유사도를 판단하는 것은 어려운 Task이기 때문에, 본 논문 이후에도 관련된 다양한 논문들이 나오고 있고, 보다 더 나은 평가 지표들이 나올 것으로 예상합니다.
'Terminology' 카테고리의 다른 글
| [개념 정리] Likelihood 와 Probability (13) | 2023.03.20 |
|---|---|
| [기술 용어 정리] fidelity 와 quality (1) | 2023.03.11 |
| [개념 정리] Chamfer Distance (0) | 2023.03.08 |
| [개념 정리] HDR : High Dynamic Range (0) | 2023.02.05 |
| [평가 지표] PSNR / SSIM / LPIPS (0) | 2022.10.08 |




댓글