GeoNeRF: Generalizing NeRF With Geometry Priors, Mohanmmad Mahdi Johari, CVPR2022
Main Idea는 Generalizable model(일반화된 모델)을 만들어서, 적은 수의 데이터가 학습데이터로 주어졌을 때, 학습이 가능하게 합니다.
Summary
다양한 데이터셋으로 Generalizable 모델을 1차 학습하고, Scene마다 Fine-tuning으로 2차 학습합니다.
Depth Estimation, FPN, Transformer Network사용으로 feature 추출하여 Quality를 향상합니다.
기존 연구들의 Issue
Generalizability를 가진 NeRF모델들 pixelNeRF(이전포스트) MVSNeRF(이전포스트) 등은 scene geometry와 occlusion을 처리하는데 한계를 가지며, Artifact를 만들게 됩니다. Detailed image 랜더링 어렵습니다.
Background
Multi-Head Attention (MHA)
논문에서 MHA을 사용하고 있습니다. 살짝 언급하고 넘어가려다가 개인적으로 공부를 위해 조금 상세하게 적어봤습니다. MHA에 대해 그냥 Skip하셔도 됩니다. (그림 출처 : link1 , link2)
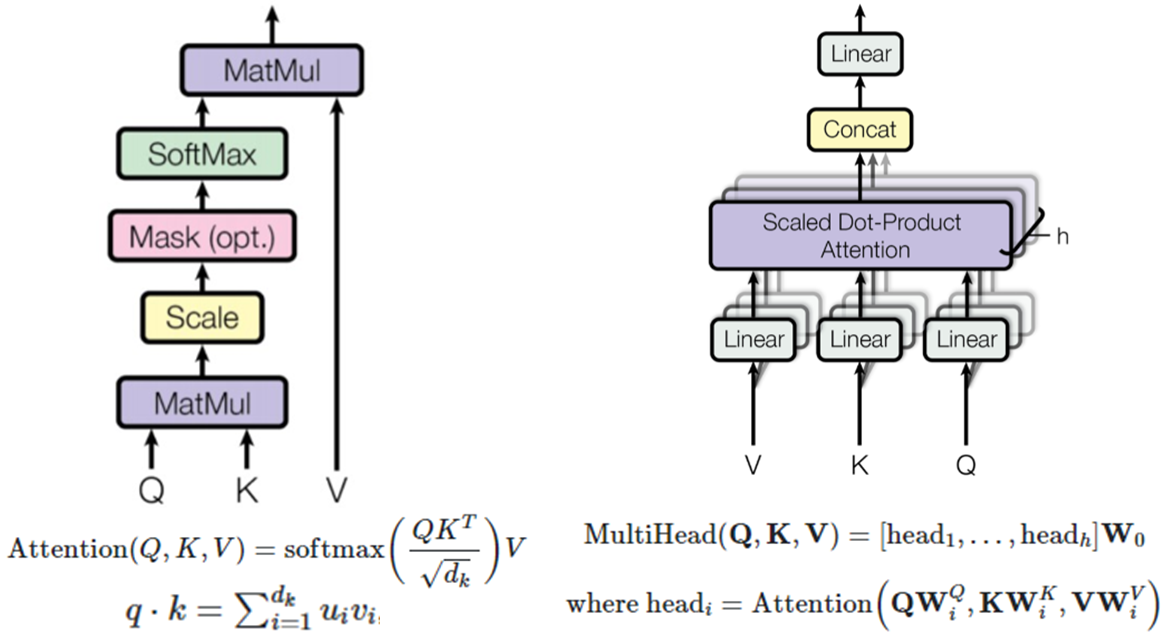
좌측 그림 Scaled Dot-product Attention부터 먼저 언급하자면,
1) 입력변수는 Query(Q), Key(K), Value vetctor(V)로 구성되어 있고, 고정된 상수vector 입니다. Query는 질의값이고, Key는 Query와 비교될 대상들, Value는 Key를 입력했을 때, 나오는 결과 값을 의미합니다. 일반적으로 인코딩된 값을 사용합니다.
2) Query vector와 Key vector를 내적해서 두 vector의 상관관계를 나타내는 Correlation Matrix를 만들게 됩니다. 이를 attention score라고도 합니다.
3) dk(vector길이)를 사용해서 해당 matrix를 나눠줌으로써 scaling이 조절된 값을 만듭니다.
4) 해당 matrix는 softmax를 사용해서 전체합의 1이 되도록 normalize를 해주고, Value vector와 내적해서 output을 계산하게 됩니다. normalized correlration matrix는 value의 가중치가 됩니다. Attention 자체에는 학습되는 parameter가 없습니다.
Attention은 단순히 Query 1개와 key와 value 쌍 여러개로 구성된 dictionary가 주어질 때, Query와 유사한 key를 찾아 key에 해당하는 value를 출력하는 알고리즘입니다.
다음으로 weight가 포함된 scaled Dot-Product Attention다뤄보겠습니다.
Q,K,V가 MatMul로 넘어갈 때, 오른쪽 그림처럼 Linear라는 layer를 두어 MLP의 weight가 곱해집니다. 오른쪽 그림 아래 보면, Attention 함수의 매개변수에 W가 붙어 있는 것을 볼 수 있습니다. W를 가진 입력값으로 Attention함수를 거쳤을 때, 나오는 predicted 결과 문장이 GT 문장과 다르다면, loss크기만큼 weight가 업데이트 됩니다. 이를 통해, query와 Value의 상관 관계가 높을 때, 높은 점수를 갖도록 weight가 업데이트(=attention) 되어집니다.
마지막으로 MultiHead Attention입니다.
weight가 들어가는 Attention이 head 갯수만큼 구성되어 있습니다. 그 결과값들이 concat되어지고, MLP를 한번더 거쳐 최종 결과값을 출력하게 됩니다. 입력값은 같지만 init weight가 다른 MLP가 여러개 붙음으로써 더 복잡한 관계를 다룰 수 있습니다.
Algorithm
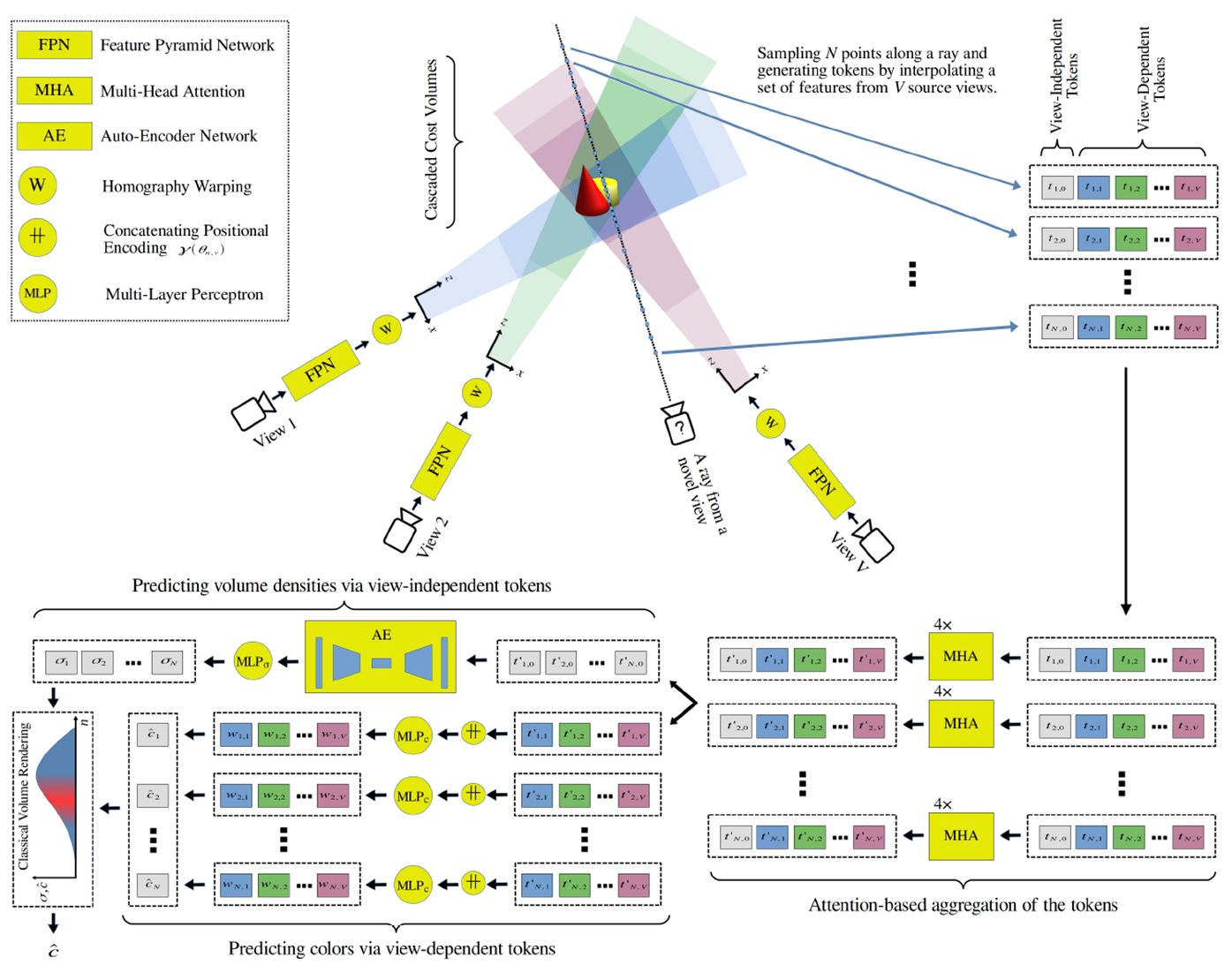
1) Geometry Reasoner network 사용 : generalizability를 위한 네트워크를 사용 (그림의 FPN에 해당)
2) Multi-Head Attention 사용 : 서로 다른 view 의 관계성을 활용 (그림의 MHA에 해당)
3) Auto-Encoder network 사용 : view-independent 한 feature 로 volume density 추정 (그림의 AE에 해당)
4) Occlusion Mask사용 : 특정 view에서 어떤 point가 가려져서 안보이거나 plane밖으로 벗어날 경우, Mask값으로 만들어 랜더링 시 해당 point에서 해당 view을 제외 (그림에서 표현되지 않음)
5) Nearby Source view사용 : 1차 학습시 3-5개, 2차 학습시 5개 (그림의 "?카메라" 주변에 인접한 3개의 카메라에 해당)
Geometry Reasoner
CasMVSNet(2019)의 Feature Pyramid Network(FPN)으로 3개의 다른 scale(아래 그림의 ℓ)의 2D Feature를 추출하고, 3가지 scale의 depth map을 생성합니다. 아래 그림은 CasMVSNet에서 가져왔습니다.(그림 출처 : link)

ℓ이 감소 할수록 fine한 정보를 잘 획득하고, ℓ이 증가 할수록 depth를 잘 파악하게 됩니다. 서로 다른 scale에 대한 2d feature는 아래 수식으로 표현되어집니다.
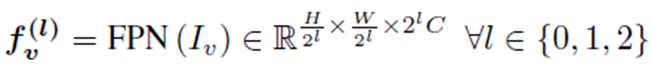
여기에서 group-wise correlation similarity(2020)으로 위 결과값을 한번 더 정제합니다.
1) 추정한 Depth d(ℓ)을 네트워크에 통과시키면 3D feature map Φ을 출력하도록 만듭니다.
2) targer view와 가까운 3~5개 nearby view Γ에 있는 <points:colst volume> 값들로 target view에 맵핑되는 points와 cost volume을 표현합니다. 이 때의 points간 맵핑은 plane sweep 와 homography warping을 기법을 사용하게 되며, points에 대한 cost volume은 group-wise correlation similairy metric을 통해 mult-cost volume이 만들어집니다.
3) cost volume을 regularize하는 3D hourglass network R을 통해 depth map D와 3D feature map Φ 을 획득합니다.
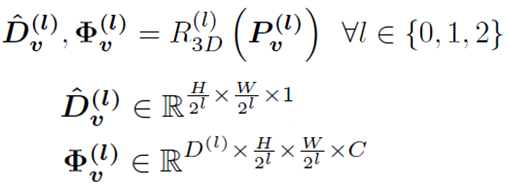
Geometry Reasoner
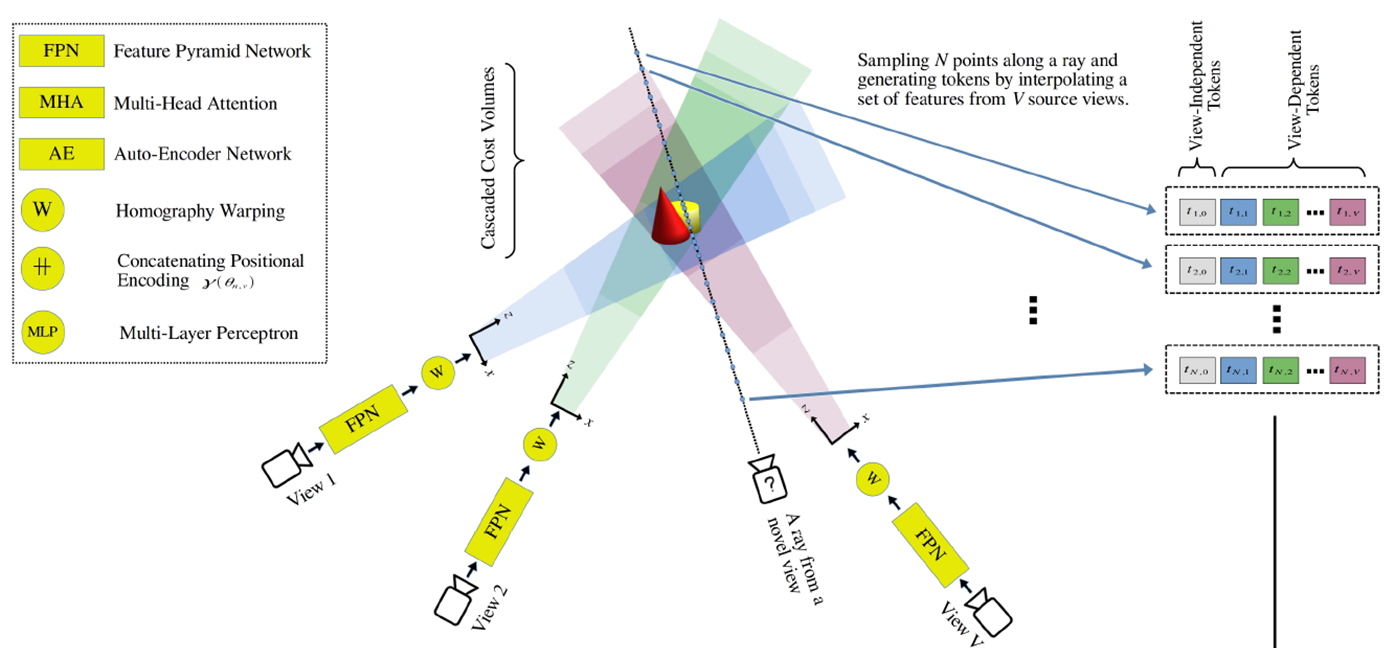
v개만큼의 view가 주어질 경우, ray위에 n개의 points들은 크게 view-depednet token과 view-independent token으로 구분되어 Encoding됩니다. view-depednet token은 말 그대로 view마다 scene정보를 담기 위한 token이며, view-independent token은 global한 정보를 담기 위한 token입니다. 수식은 아래와 같습니다.
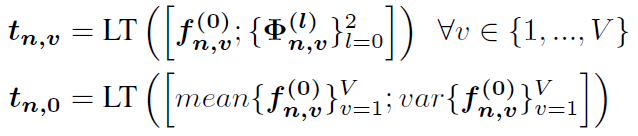
view-dependet token은 view마다 2D feature f와 3D feature map Φ 값이 list형태로 구성(tn,v)이 되고, view-indepedent token은 모든 view에 대한 2D feature 값의 평균과 분산으로 구성(tn,0)이 됩니다. (LT는 concatnation이라고 보면 됩니다.)
여기서 앞서 언급한 occlusion mask 개념도 같이 적용되는데, target view에서의 특정 point x의 token을 구성할 때, 해당 점이 source view에서 그려질 때, occlusion되어서 안보이거나 view 영역을 벗어나게되면, 해당 뷰를 제외시키는 방법이 사용됩니다.
Renderer
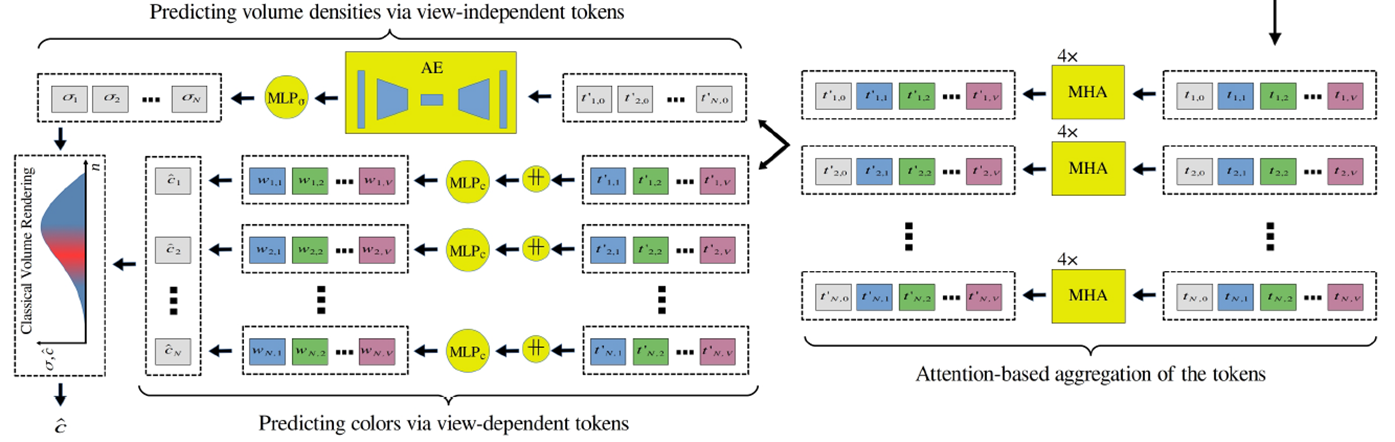
위에서 각 points가 token의 list로 변환이되었고, 이 list들은 layer 4개로 구성된 Multi-Head Attention (MHA)를 통과하게 됩니다.
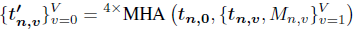
Occlusion Mask가 그대로 사용되어 Occlusion된 영역에 대해서는 view를 사용하지 않고 있고, view-independent token은 모든 points에 동일한 값으로 MHA의 입력값으로 적용됩니다. 이를 통해서, 각각의 points에 대해 기여도가 높은 view에 대해서 더 높은 점수를 부여할 수 있게 합니다.
Volume Density는 Multi-Head Attention을 통과한 view-indepedent token이 auto-encoder Nework와 density MLP로 전달됩니다. volume density는 view에 상관없이 동일해야 하기 때문에, global feature값인 view-independet token이 사용되어진 것으로 보입니다.
RGB값은 Multi-Head Atention을 통과한 view-dependent token이 color MLP로 전달됩니다. view각도에 따라 다른 radiance값이 필요하므로, view-dependent token이 사용되어진 것으로 보입니다. Color값은 기존 NeRF 연구들과 다르게 계산되어 집니다.
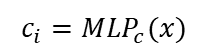
NeRF에서는 point에 대한 color값을 MLP로 계산(위의 수식)했다면, GeoNeRF에서는 point x를 source view로 projection하면서 color값을 1차 획득(아래 수식에 sigma 안쪽에 있는 c에 해당)합니다.

view에 따른 weight가 추가되게 되는데, point x와 source view의 camera center좌표를 잇는 선을 그렸을 때, 그 line과 novel camera ray가 만드는 각도값을 계산하여 이 각도값을 token list값과 같이 MLP의 입력으로 넣어줍니다. 이 각도가 적을수록 높은 유사도를 가질 것이라 기대한 것으로 보입니다. 여기서도 어김없이 Occlusion Mask가 나옵니다. non-occluded view의 color를 제외하고 weight를 구성합니다.
마지막으로 이렇게 계산된 color와 volume density는 최초 NeRF와 동일한 Volume Rendering공식을 통해 랜더링 됩니다.
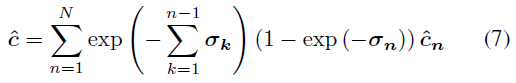
Loss Functions
generalizable model을 학습할 땐, (13) 수식을 사용하지만, 특정 scene을 학습하는 fine-tuning시엔, (9)수식만 사용합니다.
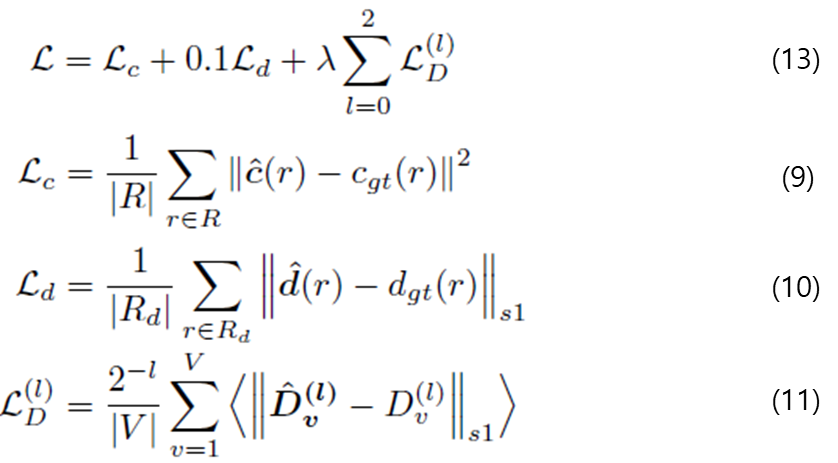
수식 (9)은 vanila NeRF와 동일하게 pixel color에 대한 mean squared error loss입니다.
수식(10)은 depth loss로써, DS-NeRF에서 적은 input view를 가질 때 빠르게 학습하는데 도움을 줄 수 있었다고 합니다. depth데이터가 없는 경우에는 빼도 된다고 합니다.
수식 (11)에서는 Geometry Reasoner에서 scale ℓ에 따른 depth map의 차이를 계산합니다. < >는 모든 픽셀의 평균값을 의미합니다.
GT에 depth가 없이 샘플을 학습할 땐, depth map은 self-supervise됩니다. pseudo-GT로써 rendered ray depth를 구성합니다. 모든 source view에서 estimated된 상응되는 color와 추정된 depth와 warping합니다(?). 만약 ray의 GT pixel color가 source view의 color와 동등하고 texture상에서도 인접하게 위치한다면, 해당 view의 geometry resoner을 학습합니다. 이에 대한 수식은 아래와 같습니다.
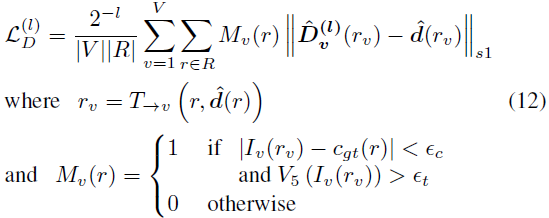
수식 (13)에서 λ는 GT depth가 있을 땐 1.0이고, 없을 땐 0.1을 사용합니다.
Experiments
실험에 사용된 Dataset 구성입니다. 자세한 정보와 그림은 NeRF Dataset 포스트 참조 바랍니다.
| Total Scene | Train Scene | Test Scene | |
| DTU | 88 | 72 | 16 |
| LLFF forward facing |
35 | 27 | 8 |
| IBRNet realistic synthetic data |
67 | 59 | 8 |
DTU, LLFF, IBRNet의 Train Scene에 대해 Generalizable model을 학습하였고, Test Scene에 대해 fine-tuning을 진행하였습니다. 이중 DTU만 depth GT를 갖고 있었습니다.
Generalizable Model은 512ray 배치 단위로 랜덤하게 선택해 250k iteration을 했고, fine-tuning시에 10k iteration을 진행하였습니다. 아래는 실험 결과입니다. 평가지표는 PSNR/SSIM/LPIPS 이전글 참조 바랍니다.

비교군들이 Generalizable Model들로 되어 있어서, 전반적으로 PSNR이 낮은 수치입니다.
fine-tuning을 진행한 per-scene optimization과 fine-tuning을 진행하지 않은 No per-scene optimization으로 구성됩니다. Generalizable Model에서도 GeoNeRF의 성능이 높음을 볼 수 있습니다. 그리고 fine-tuning을 1k만 하더라도 기존 연구들보다 성능이 좋았고, 10k했을 때 가장 좋은 성능을 보였습니다.
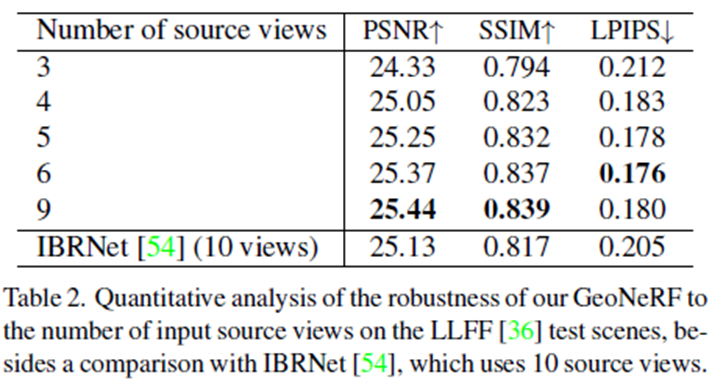
source view의 갯수에 따른 성능차이입니다. source view가 많을 수록 성능이 높아지는 것을 볼 수 있습니다.
Closing..
Occlusion Mask를 모든 step에서 다 적용한 것으로 보아, 이부분을 굉장히 중요하게 고려했다고 생각되네요. sparse dataset에서 생각보다 artifact가 많이 발생하는데, 이걸 방지하기 위해서 썼다고 생각하고 있습니다. (논문에서도 짧게 언급은 되어 있긴합니다.) 다른 Generalizble Model보다 이미지 퀄리티가 좋다고 언급해뒀지만, 실제로는 blur한 이미지로 느껴졌습니다. 그리고 Generaizable Model을 학습시킬 때 너무 오랜 시간이 소요되어서, 반복적으로 실험이 가능할까?라고 의문이 들었습니다. 반대로 장점을 언급하자면, fine-tunning없이 성능 평가를 했을 때, 저 정도 성능을 보였다는 것 자체가 대단하다고 생각을 했습니다. Generalizable model이 어떻게 발전될지 궁금하네요.
'NeRF' 카테고리의 다른 글
| [논문 리뷰] One-2-3-45++ (arXiv 2023) : Image-to-3D 속도/퀄리티 개선 (0) | 2023.12.08 |
|---|---|
| [논문 리뷰] Tri-MipRF (ICCV 2023) : 속도/퀄리티/메모리 개선 (0) | 2023.08.16 |
| [데이터셋] NeRF Dataset 정리 (3) | 2023.08.05 |
| [논문 리뷰] Zip-NeRF (ICCV 2023) : Anti-Aliasing, 속도 개선 (1) | 2023.08.02 |
| [논문 리뷰] TensoRF (ECCV 2022) : 메모리/속도 개선 (1) | 2023.07.30 |




댓글