GPU 메모리 구성과 데이터 흐름에 관해 다뤄보겠습니다.
Graphic관련 논문을 읽기 위한 목적으로 일반적인 개념들을 정리해보았습니다.
GPU 메모리 구조

GPU와 CPU메모리 구조의 차이입니다. (출처 : link)
- GPU SM은 CPU Core와 같은 단위입니다. SM은 Streaming Multiprocessor의 약자입니다. 1개의 GPU에는 여러 개의 SM으로 구성되어 있습니다.
- SM 내부에는 L1 cache가 있고, SM들은 L2 cache를 통해 RAM(=main memory=global memory)에 access 하는 구조입니다. CPU와 cache단위가 다른 것을 볼 수 있습니다.

세부적인 수치를 같이 보겠습니다. 위는 A100 GPU의 구조입니다. (출처 : link)
- Register : 가장 빠른 저장소입니다. GPU Core 연산에 직접적으로 사용됩니다.
- Cache : RAM의 데이터나 값을 미리 복사해 놓는 빠른 속도의 임시 저장소입니다. SM 내/외부로 나눠져있습니다.
- DRAM : 프로그램 실행을 위해 사용되는 저장소입니다.
- 용량(=Capacity)과 속도(=Latency)가 반비례합니다.
- 용량 : Register < L1 cache < L2 cache < GPU DRAM (위 이미지에서 확인 가능합니다.)
- 속도 : Register > L1 cache > L2 cache > GPU DRAM

각각의 속도에 관해서는 정확한 자료를 못찾았지만 위와 같은 속도 차이가 발생한다고 보면 됩니다. (출처 : link)
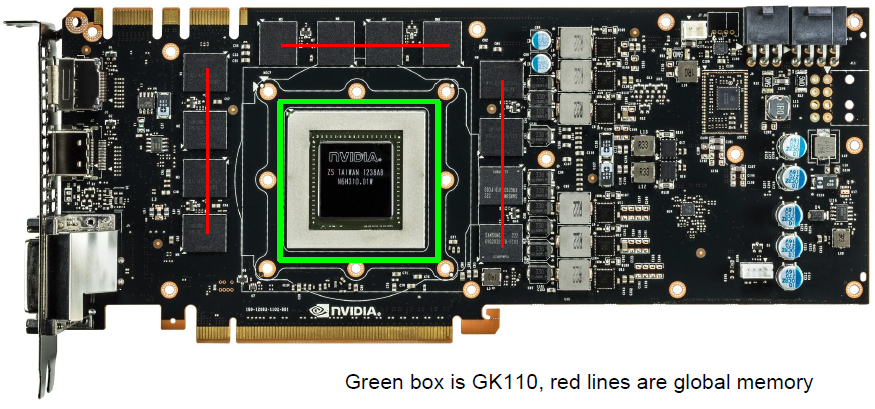
Kepler GK110이라는 GPU의 실제 구성입니다. (출처 : link )
초록색은 SM에 해당하고, 빨간색은 global memory에 해당합니다. (L2 Cache는 어느 부분인지 모르겠네요. 댓글에 어떤분이 초록색 안쪽에 있다고 알려주셨습니다!)
프로그램 실행시 데이터 흐름

하나의 프로그램이 실행 될 때, 데이터의 흐름입니다. (출처 : link)
단위에 대한 개념부터 설명하자면 아래와 같습니다. Grid는 여러개의 Thread Block으로 구성되어 있고, Thread Block은 여러개의 Thread로 구성됩니다.
- Grid : 병렬 실행되는 명령의 모음이며, Kernel(=함수)당 1개의 grid 실행합니다. 여러 개의 block으로 구성됩니다.
- Block : 병렬로 독립적으로 수행되는 단위입니다. 여러 개의 thread로 구성됩니다.
- Thread : 명령을 실행하는 동작 단위입니다. Cuda Core 1개가 1개의 thread 를 수행합니다.
각각의 Thread는 Cuda Core안에서 다음과 같은 메모리 Access를 통해 수행됩니다.
SM에 Register와 Shared Memory에 Acess합니다.
- Register : Thread마다 사용되는 메모리입니다.
- Shared Memory (=SMEM) :데이터나 값을 미리 복사해 놓는 빠른 속도의 임시 저장소입니다. L1 cache와 동일한 역할을 하며 L1은 자동으로 관리되며 SMEM는 수동으로 코드를 통해 관리 됩니다. Block안의 모든 thread 들이 공유합니다.
DRAM의 Local Memory(지역 변수용), Global memory(전역 변수용), Constant memory(=상수용), Texture memory(=그래픽용)에 Acess합니다.
- Local Memory : Thread마다 사용되는 메모리입니다.
- Global, Constant, Texture Memory : Thread간에 공유되어 사용되는 메모리입니다.

위 과정은 병렬 연산을 통해 수행됩니다.(출처 : link) Grid내 Thread Block은 여러 SM에 병렬적으로 나눠 수행되는 것을 볼 수 있습니다. 위에서 설명 안한 용어만 추가적으로 적어보겠습니다.
- Kernel : programmer가 GPU에서 병렬로 실행하게 구현한 함수입니다. 코드를 작성하는 함수 단위로 생각하면 될 것 같습니다. Kernel은 SW형태이고 Grid는 HW형태로 구분하면 됩니다. (일반적으로 커널은 OS에서 System Resource을 관리하는 프로그램을 의미합니다.)
- Warp : 동시에 동일 instruction으로 실행되는 thread 묶음입니다(출처 : link) . 스케쥴링되는 최소 단위입니다. 32개의 Thread로 구성되어 있습니다. 여러 개의 warp로 1개의 thread block을 구성 합니다.
SM(Stream Multiprocessor) 의 세부구조

SM이 세부적으로 어떤 구조로 되어 있는지 보겠습니다. 위는 Kepler GF110의 SM구조입니다. GPU마다 다른 구조로 되어 있습니다. (출처 : link)
- cache : Instruction cache, Uniform cache, Texture cache가 존재합니다.
- Warp Scheduler : Warp을 스케쥴링하는 모듈입니다.
+ Warp Divergence : warp안에 동일한 instruction 이 없을 경우, 서로 다른 횟수만큼 실행될 때를 말합니다. 2~32-way divergence가 존재 할 수 있습니다. 이을 막기 위해 Warp Scheduler가 잘 설계되어져야 합니다. - Dispatch Unit : 작업 할당을 dispatch라고 합니다. Dispatcher를 통해 Cuda Core에 thread작업이 할당됩니다.
- Register File : 위에서 언급된 레지스터 메모리입니다.
- Core : Cuda Core라고 불립니다. CPU Core와 다른 단위입니다. Cuda Core 1개가 1개의 thread 를 수행합니다.
- Shared Memory / L1 Cache : 위에서 언급된 Shared Memory/ L1 Cache입니다.
GPU Spec 확인
마지막으로 Nvidia의 GPU들의 스팩입니다. 위 내용들과 연결지으면서 보시길 바랍니다.
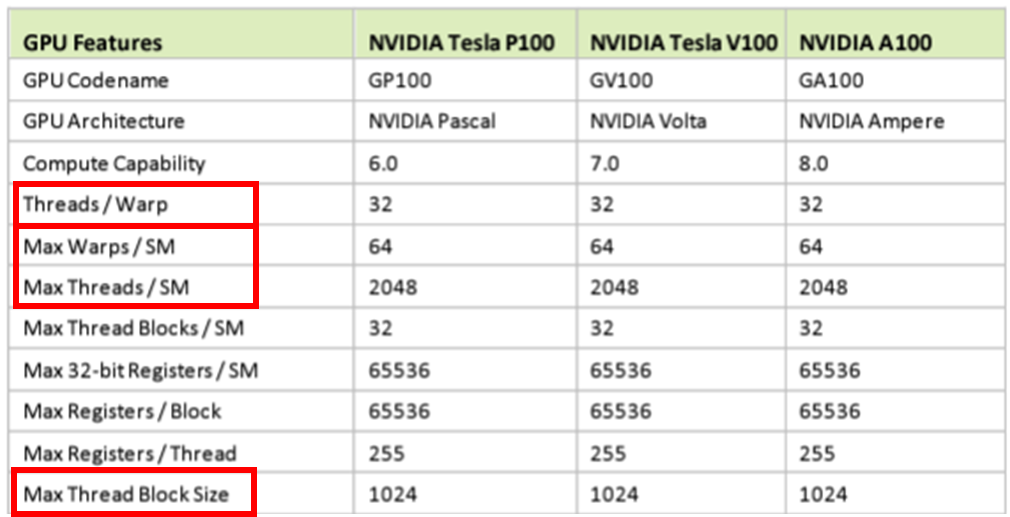
A100기준으로 보면 (출처 : link),
- (위에서 설명한대로) Warp마다 32개의 Thread로 구성되어 있습니다.
- SM마다 64개의 Warp로 구성되어 있습니다. 때문에 SM마다 총 2048개(32thread x 64warp)의 thread로 구성됩니다.
- Block은 병렬로 독립적으로 수행되는 단위라고 했었습니다. block사이즈는 1024개까지 늘일수 있네요.

다른 Spec표로 A100을 보면,
- SM은 총 108개입니다.
- SM마다 64개의 Core로 구성되어 있기 때문에, GPU에 있는 총 Core 갯수는 6912(108SM x 64core)입니다.
- FP32, FP64, INT32 core가 별도로 존재하는 것을 볼 수 있습니다. 각각은 Floating Point 32bit연산, 64bit연산, int연산을 나타냅니다.
- Memory Size는 Global Memory(=Main Memory)에 해당하며, 40GB임을 볼 수 있습니다. 딥러닝 학습 할 때 가장 많이 고려하는 항목입니다.
- 마지막 빨간 사각형에서는 L2 Cache Size와 SM마다 Shared Memory Size, Register File size를 볼 수 있습니다.
기타 용어
그 외 글 흐름상 정리하지 못한 용어입니다.
- Atomic operation : 한 번에 실행되고 중단되거나 방해 받을 수 없는 연산입니다.
- Contention : shared resource 접근시 conflict를 의미합니다.
- Stall : 이전 operation의 dependency 때문에 다음 명령을 실행 할 수 없을 때 발생합니다. 정체 현상을 의미합니다.
- ROP(Render Output Unit) : 쉽게 설명하면, 픽셀에 점을 최종적으로 찍어 display하는 단위입니다. wikipedia에 의하면, rendering process의 마지막 단계로써, local memory간의 버퍼들 사이의 transaction을 수행한다고 되어있으며, GPU의 출력이 표시할 준비가 된 비트맵 이미지로 조합되는 곳이라고 합니다. (출처 : link ). ROP가 많으면, 그만큼 짧은시간에 많은 점을 찍어서 빠른 속도로 랜더링 할 수 있게 됩니다. (출처 : link) 제가 읽는 논문에는 L2 atomic unit으로 소개되어 있습니다.
- LSU(Load-Store Unit) : 간단히 말하면, core에서 cache와 memory로 request하는 단위입니다. wikipedia에 따르면, load와 store instruction을 실행하고 virtual adress를 생성하고 memory로부터 data를 load하거나 register에서 memory로 되돌려 store하는 실행 단위입니다.
Closing..
단순히 그래픽 논문 읽기 위해 용어 정리 목적으로 글을 썼는데, 찾아보니 Cuda Programming을 하게 될 경우에 필요한 개념들이네요. 여러 분야에서 본 글이 도움이 되길 바랍니다.
기타 출처
https://cvw.cac.cornell.edu/gpu-architecture/gpu-characteristics/kernel_sm
https://forums.developer.nvidia.com/t/gpu-memory-dram-or-sram/26742/3
'Etc' 카테고리의 다른 글
| [Ubuntu] CUDA 설치 & Multi CUDA 설치 (4) | 2024.04.28 |
|---|---|
| [Ubuntu] Pytorch 설치 : 버전 호환 CUDA & python (1) | 2024.04.27 |
| [후기] AI 서비스 개발 실패 후기 (11) | 2023.12.11 |
| [Ubuntu] 윈도우에서 Ubuntu로 원격 접속 설정 (1) | 2023.05.07 |
| [정보 공유] Computer Vision 학회 / 대회 일정 (0) | 2023.02.13 |




댓글